测试环境
单台服务器,ubuntu20,512GB内存,多块ssd组成raid容量13TB,处理器Intel(R) Xeon(R) Gold 5320 CPU @ 2.20GHz
测试系统
nebula 3.3,默认配置单机部署(1 storage)
neo4j 4.4.17社区版
测试数据
SF100,neo4j落盘大小134G,nebula落盘大小108G
short query测试
由于driver中没有为short query生成测试参数,因此简单的手动进行了测试
neo4j使用cypher-shell,nebula使用nebula-console
nebula使用了默认的参数配置,neo4j则是创建了索引以及调整了page cache大小
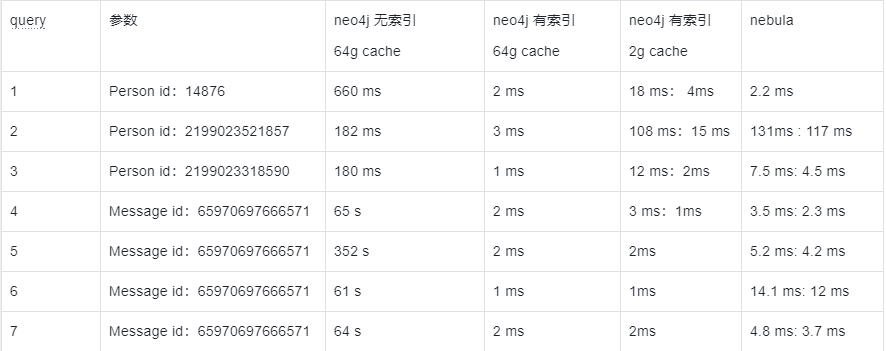
测试结果里有两个数据的,第一个表示第一次运行这个query,第二个表示多次运行后的值(应该是缓存起了加速)
query 5 6 7使用了相同的参数,导致neo4j直接缓存了内容速度很快。但是在将page cache限制到2G后,在query 1 2 3 4中,nebula并没有比neo4j性能更高。
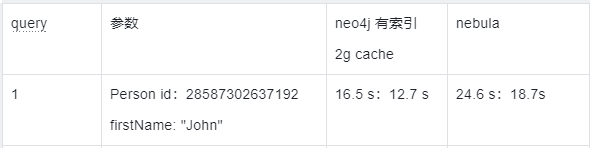
complex query 1
由于测试参数的datetime类型没处理好,因此只测了complex1
得到的结果是
求助
目前由于测试环境没有弄好,因此只简单的测了几个query。根据之前的了解,nebula的性能高于neo4j,但我的测试里可能因为测试参数的不均匀,导致neo4j对访问的数据都进行了缓存,从而导致性能高于nebula。
希望大佬分享一些nebula的调优配置经验