meta切主存在一些bug。
可以先把meta全部kill然后重新拉起,应该能恢复服务。
我们需要一点时间排查这个问题
ricki
3
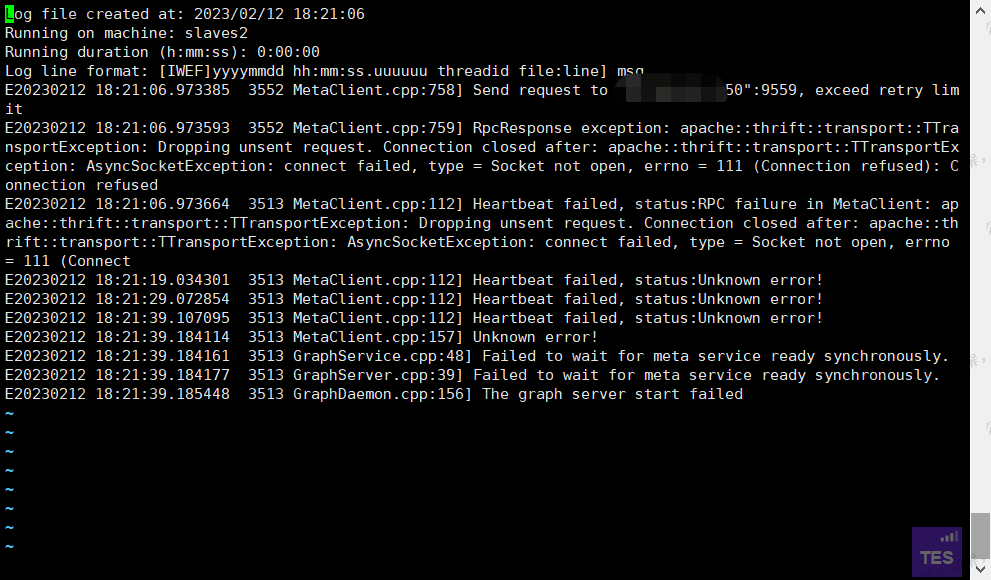
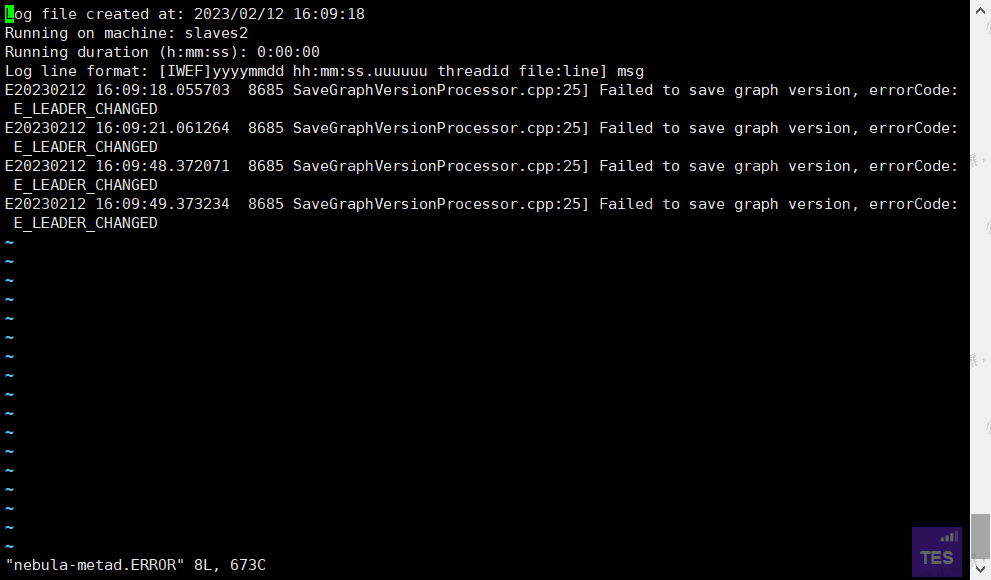
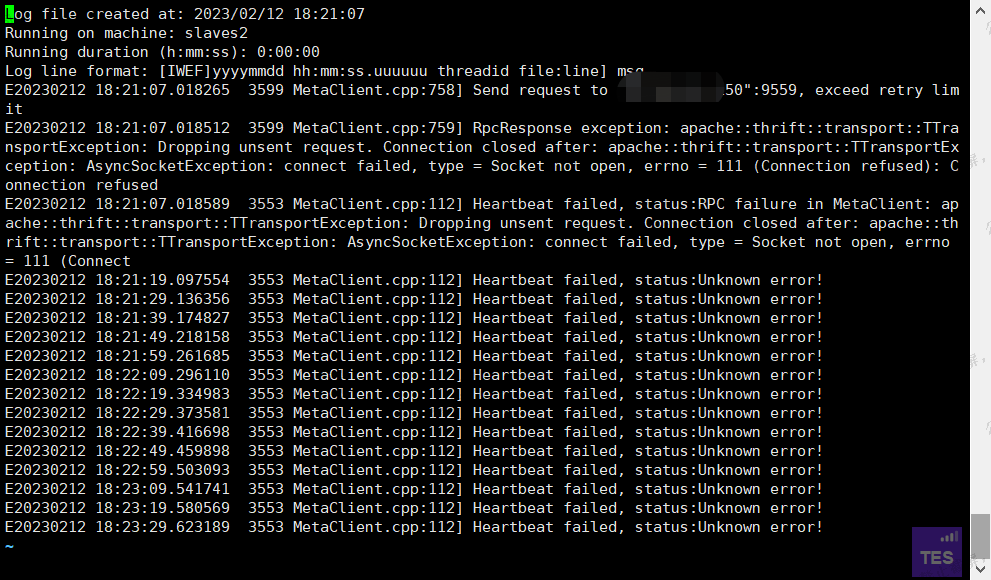
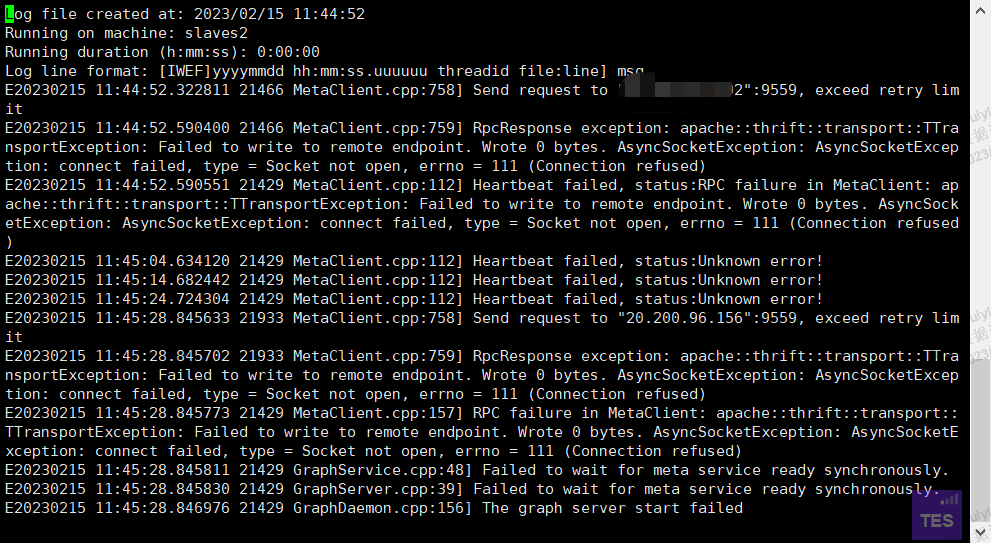
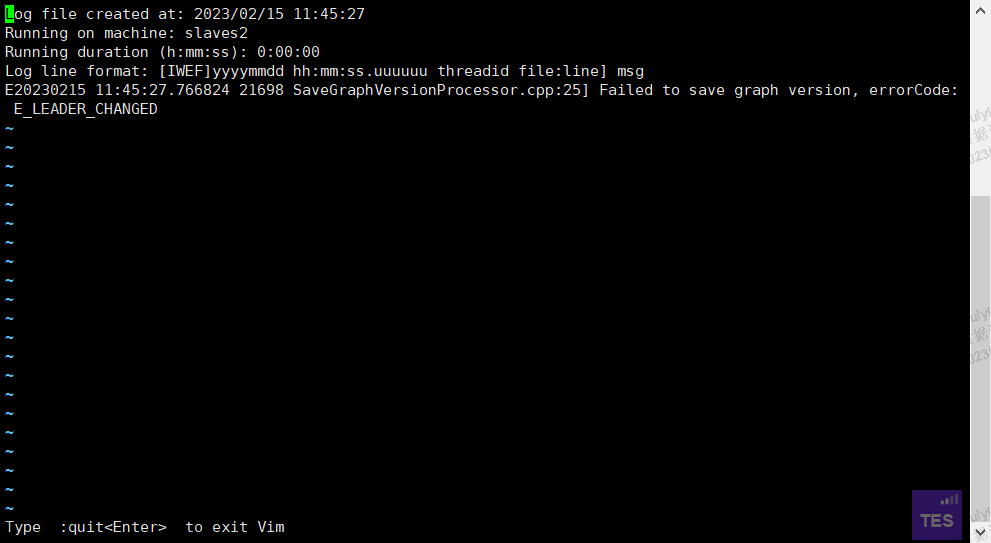
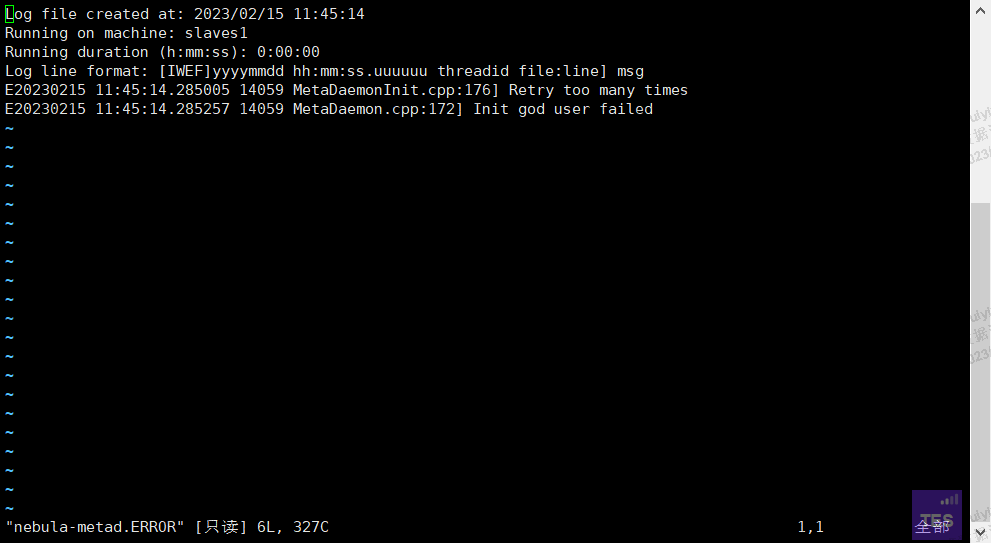
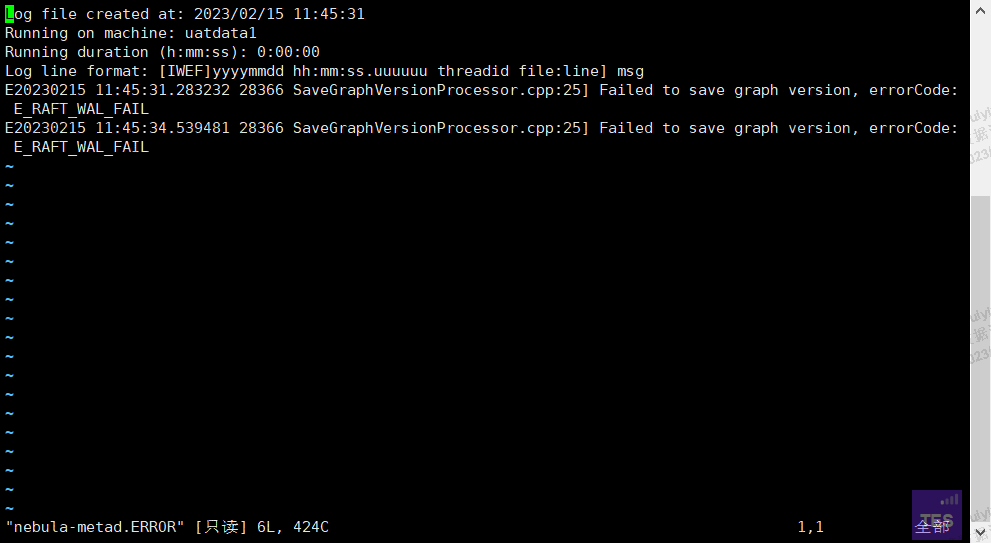
所有进程都停掉以后重启还是失败,graphd进程短暂在线以后就消失了。日志:
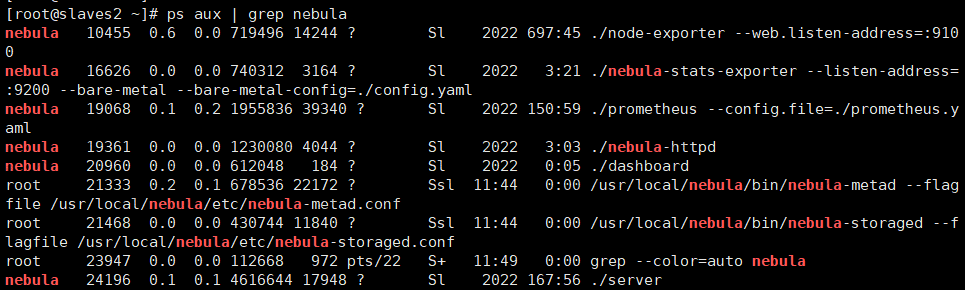
主节点进程状态
子节点进程状态:
请问这也是meta的问题吗
看上去一个节点的meta启动失败了,可以看下对应meta日志吗?
你重启meta是三个都重启了吗?看上去有meta leader一直没成功进入启动流程。
ricki
10
三台机器的状态是这样的,有一台的所有服务都不能启动,其他两台的graphd不能启动
这台完全没启动的会是什么原因呢,conf我都重新检查了一遍,应该是没问题的
steam
11
 这个报错信息很简单了,你参考下这个文档:管理 Storage 主机 - NebulaGraph Database 手册
这个报错信息很简单了,你参考下这个文档:管理 Storage 主机 - NebulaGraph Database 手册
从 v3.0 开始,有个类似激活 storaged 的步骤,你对这文档执行下(也适用于其他非 v3.4 但是是 v3.x 版本的)
ricki
12
嗯嗯,我之前注册过这个,但是疑惑是为什么有一台的所有服务起不来,这个状态下我console也不能访问数据库,没办法注册storaged呀
steam
15
果然重启不行,重装总是万能的。那你看看有啥问题可以继续更新帖子
system
关闭
16
此话题已在最后回复的 30 天后被自动关闭。不再允许新回复。