- nebula 版本:3.4.0
- 部署方式:分布式
- 安装方式:RPM
- spark-connector版本:3.0-SNAPSHOT
问题描述:
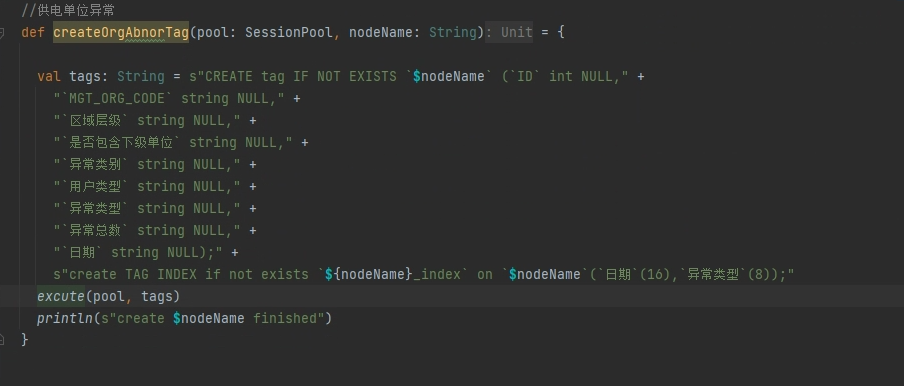
使用spark-connector 来创建tag,tag字段为中文字段。 以local模式或者client模式提交spark任务时能够正常创建,以cluster模式提交时,任务运行不报错,但中文字段全部乱码。推测可能是提交流程中的bug
问题描述:
使用spark-connector 来创建tag,tag字段为中文字段。 以local模式或者client模式提交spark任务时能够正常创建,以cluster模式提交时,任务运行不报错,但中文字段全部乱码。推测可能是提交流程中的bug
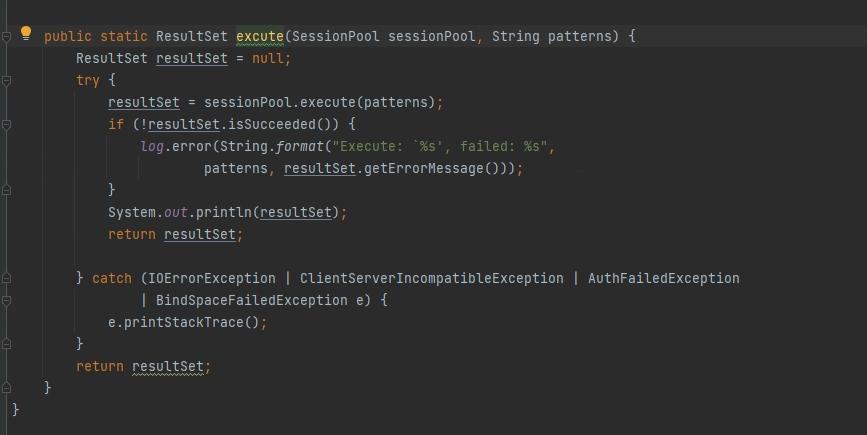
相关的导入代码和配置文件贴一下。
首先这个版本是不对齐的,spark connector 的 snapshot 版本对应的是 nebulagraph 的最新分支 master / nightly。
其次,你的使用方法为啥和文档的是不对齐的。参考文档:https://docs.nebula-graph.com.cn/3.4.0/nebula-spark-connector/#_5
snapshot版本是思为发我的,应该是没问题的。 然后你贴的这个连接,是写入和读取的demo。 我这边是创建tag的代码
此话题已在最后回复的 30 天后被自动关闭。不再允许新回复。