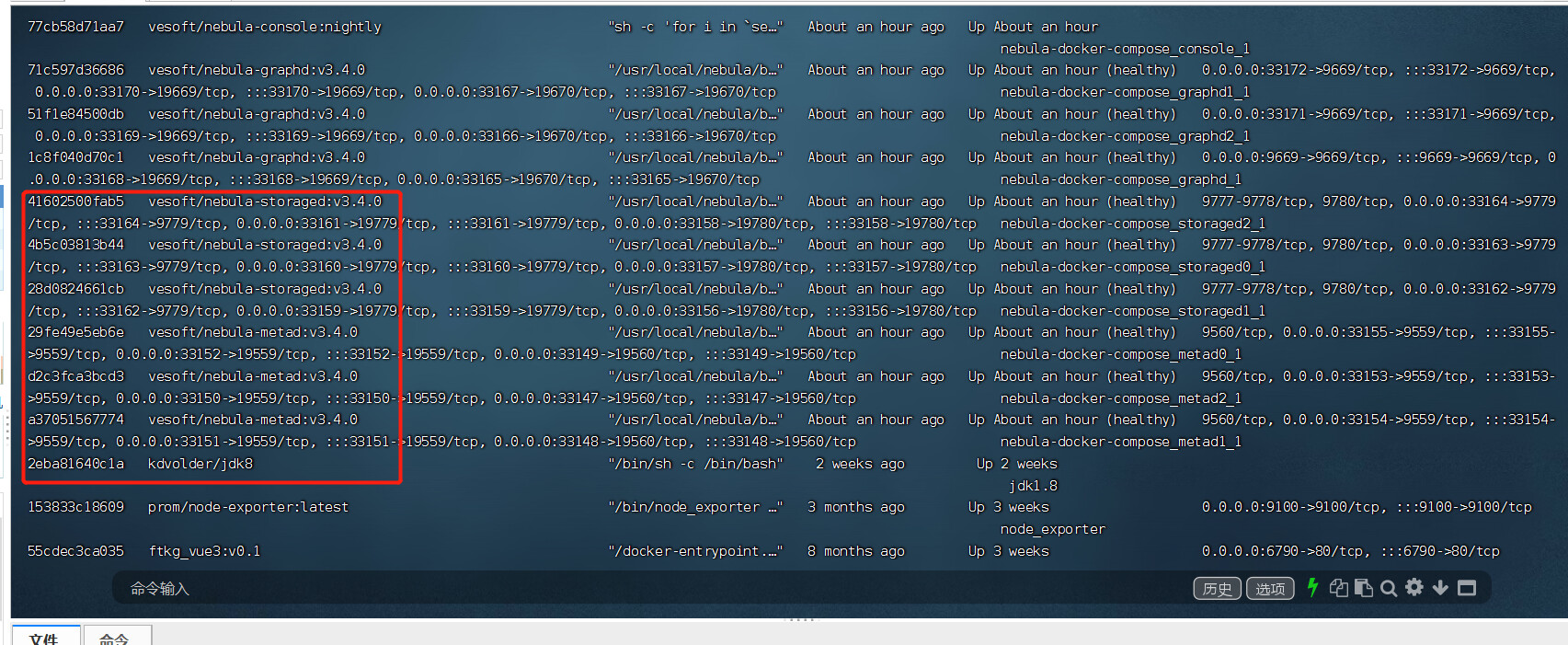
- nebula 版本:3.1.1
- 部署方式:分布式
- 安装方式: Docker
- 是否为线上版本: N
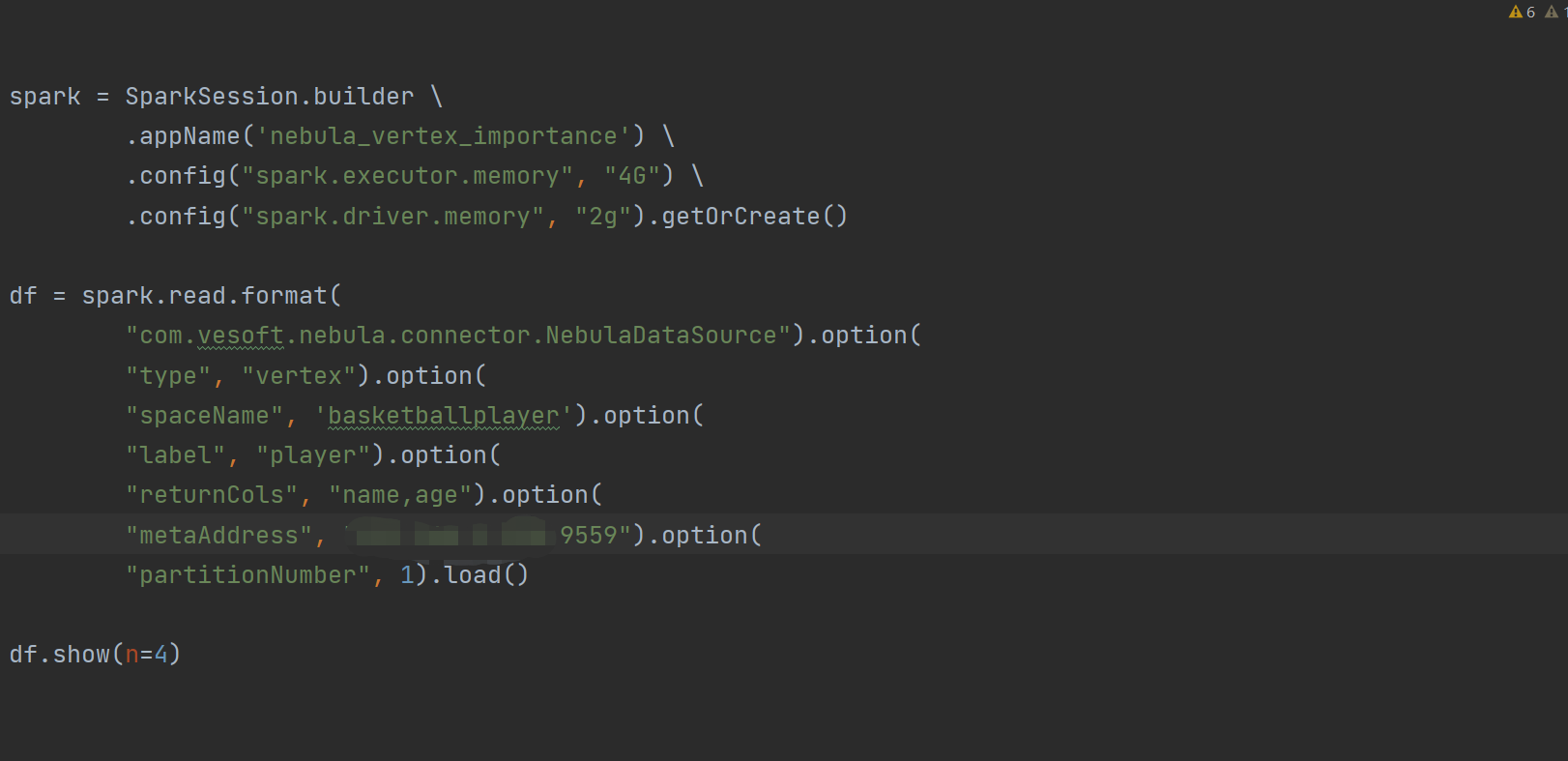
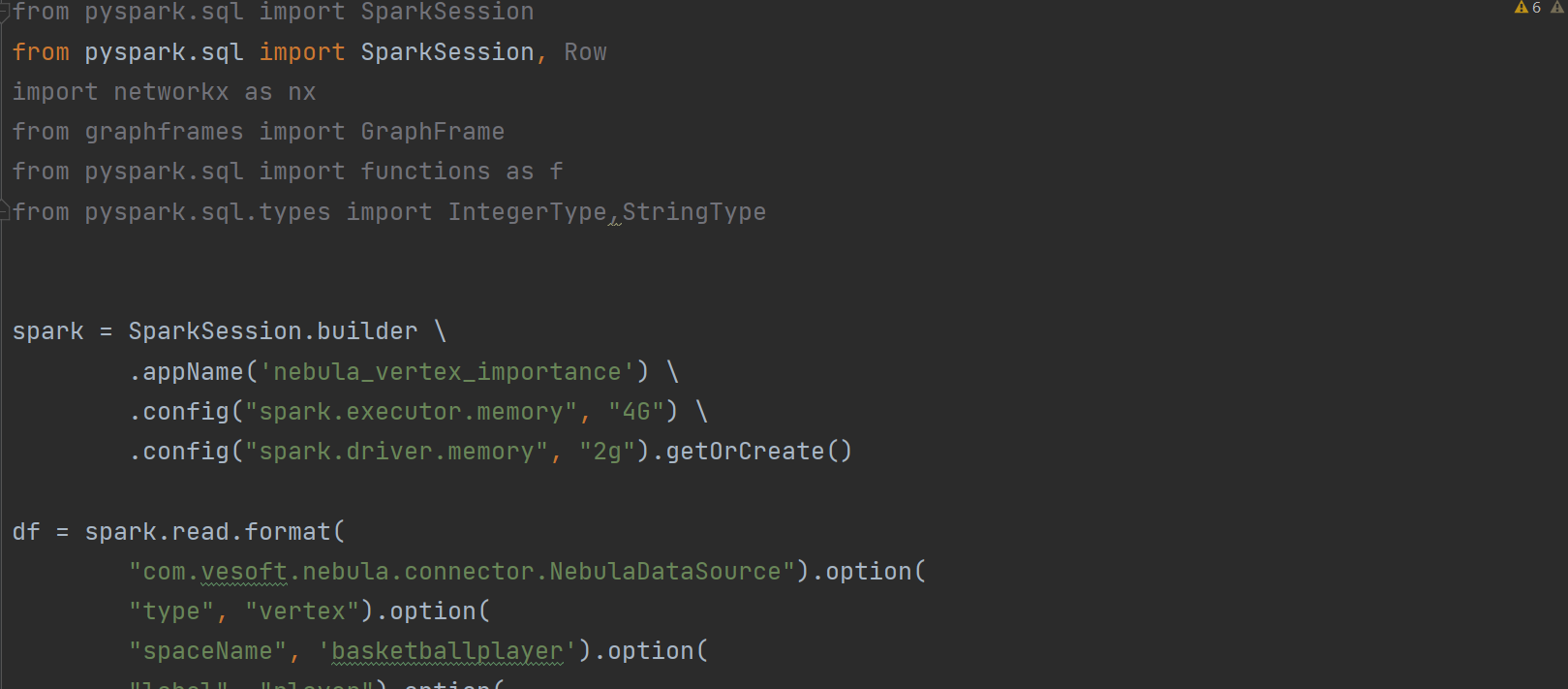
我想链接数据库读取一下信息
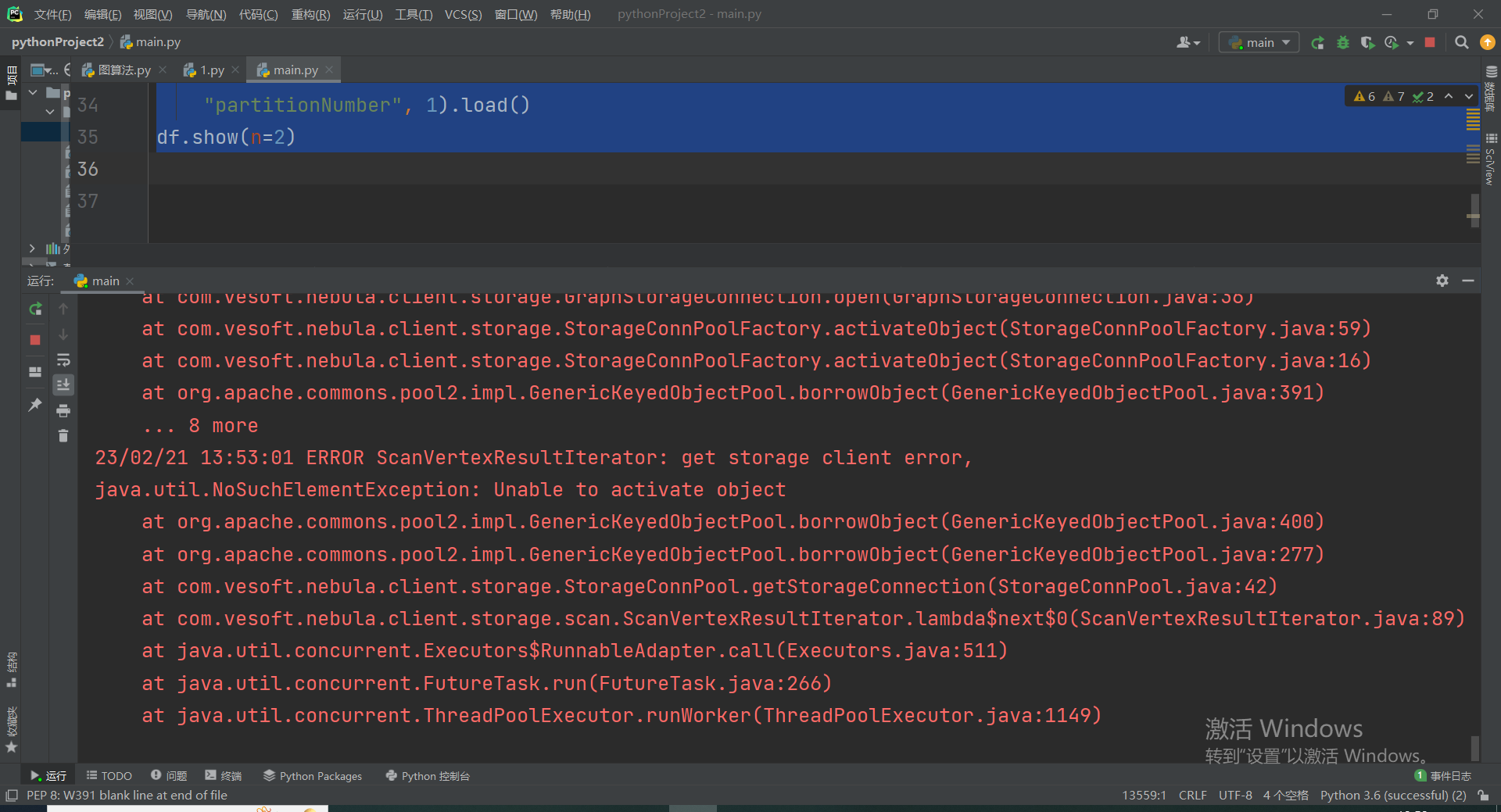
报错信息 是我写的代码不对吗
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
Traceback (most recent call last):
File "D:/PycharmProjects/pythonProject2/main.py", line 20, in <module>
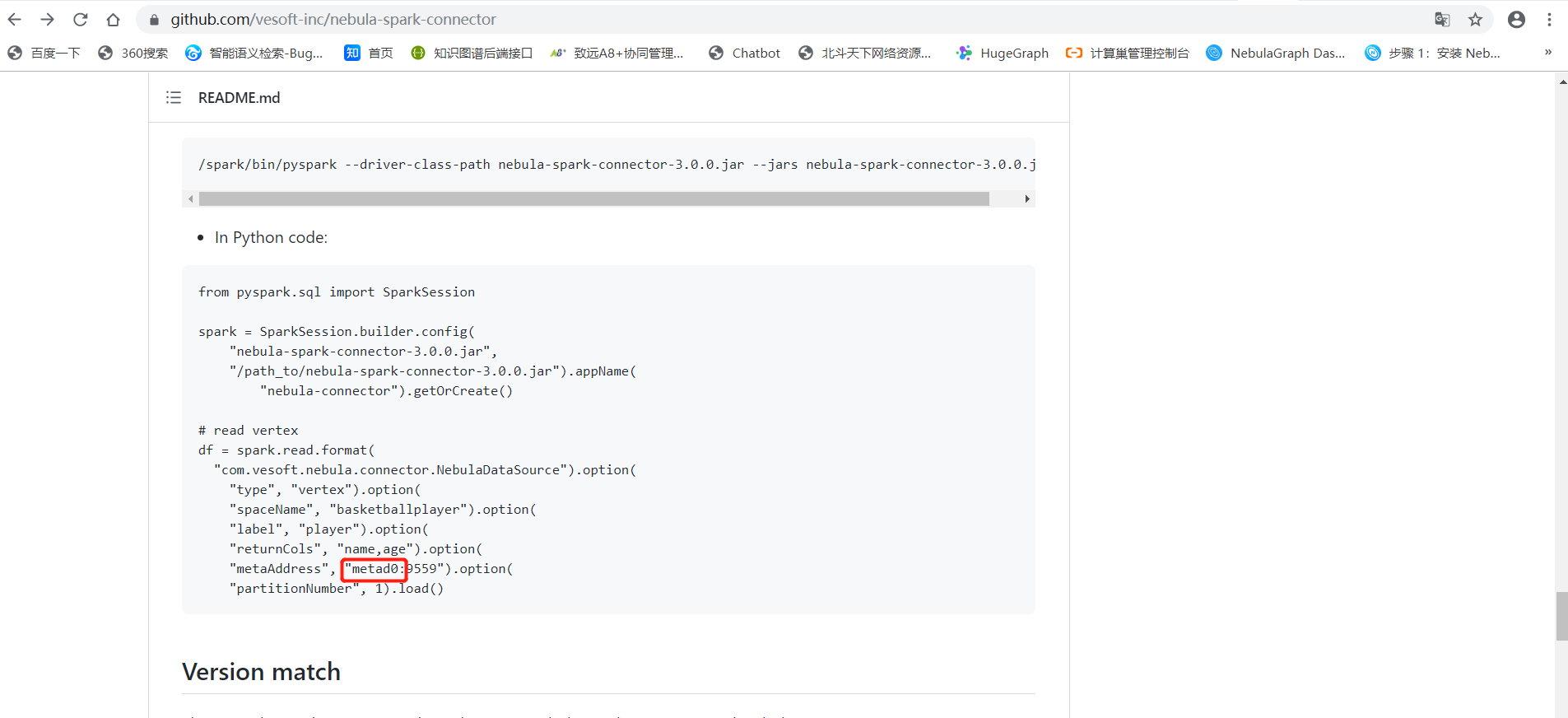
"metaAddress", "192.168.1.230:9559").load()
File "E:\anaconda\envs\successful\lib\site-packages\pyspark\sql\readwriter.py", line 172, in load
return self._df(self._jreader.load())
File "E:\anaconda\envs\successful\lib\site-packages\py4j\java_gateway.py", line 1257, in __call__
answer, self.gateway_client, self.target_id, self.name)
File "E:\anaconda\envs\successful\lib\site-packages\pyspark\sql\utils.py", line 63, in deco
return f(*a, **kw)
File "E:\anaconda\envs\successful\lib\site-packages\py4j\protocol.py", line 328, in get_return_value
format(target_id, ".", name), value)
py4j.protocol.Py4JJavaError: An error occurred while calling o45.load.
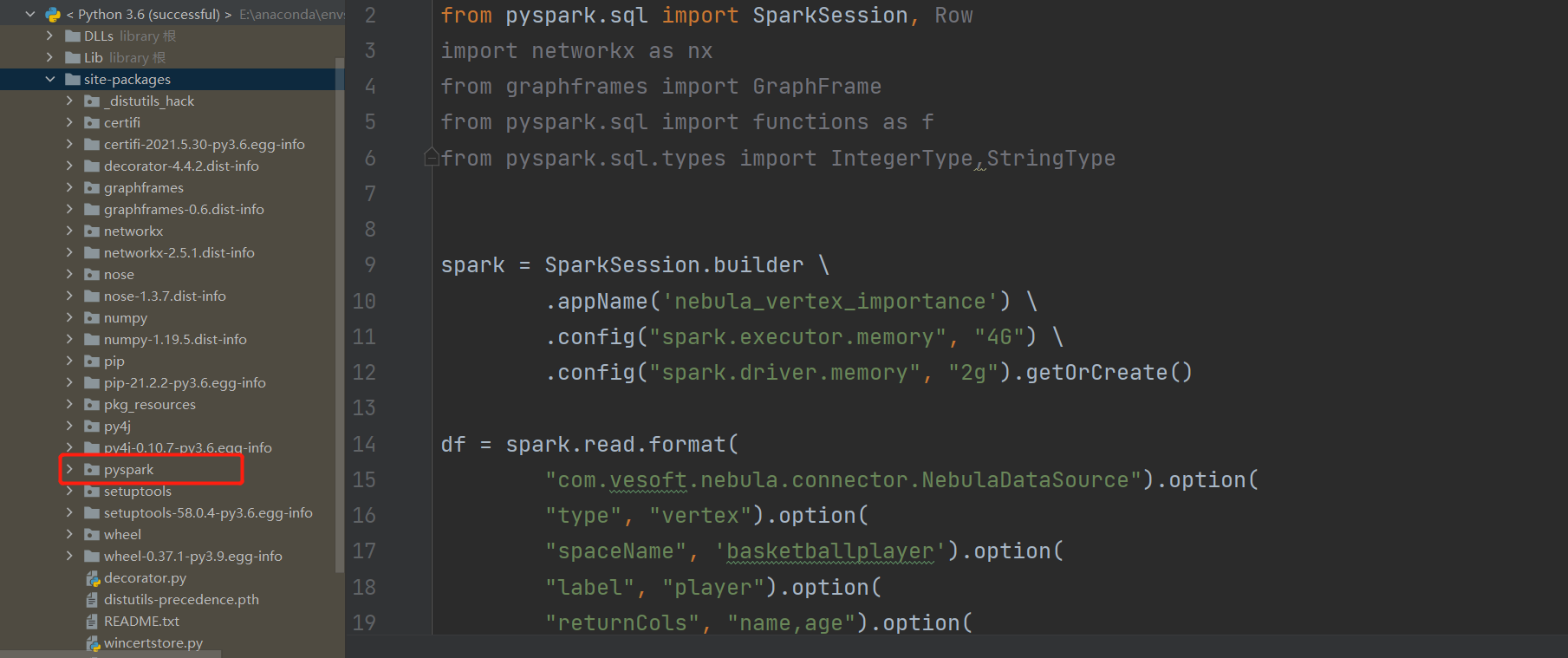
: java.lang.ClassNotFoundException: Failed to find data source: com.vesoft.nebula.connector.NebulaDataSource. Please find packages at http://spark.apache.org/third-party-projects.html
at org.apache.spark.sql.execution.datasources.DataSource$.lookupDataSource(DataSource.scala:657)
at org.apache.spark.sql.DataFrameReader.load(DataFrameReader.scala:194)
at org.apache.spark.sql.DataFrameReader.load(DataFrameReader.scala:167)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at py4j.reflection.MethodInvoker.invoke(MethodInvoker.java:244)
at py4j.reflection.ReflectionEngine.invoke(ReflectionEngine.java:357)
at py4j.Gateway.invoke(Gateway.java:282)
at py4j.commands.AbstractCommand.invokeMethod(AbstractCommand.java:132)
at py4j.commands.CallCommand.execute(CallCommand.java:79)
at py4j.GatewayConnection.run(GatewayConnection.java:238)
at java.lang.Thread.run(Thread.java:748)
Caused by: java.lang.ClassNotFoundException: com.vesoft.nebula.connector.NebulaDataSource.DefaultSource
at java.net.URLClassLoader.findClass(URLClassLoader.java:381)
at java.lang.ClassLoader.loadClass(ClassLoader.java:424)
at java.lang.ClassLoader.loadClass(ClassLoader.java:357)
at org.apache.spark.sql.execution.datasources.DataSource$$anonfun$20$$anonfun$apply$12.apply(DataSource.scala:634)
at org.apache.spark.sql.execution.datasources.DataSource$$anonfun$20$$anonfun$apply$12.apply(DataSource.scala:634)
at scala.util.Try$.apply(Try.scala:192)
at org.apache.spark.sql.execution.datasources.DataSource$$anonfun$20.apply(DataSource.scala:634)
at org.apache.spark.sql.execution.datasources.DataSource$$anonfun$20.apply(DataSource.scala:634)
at scala.util.Try.orElse(Try.scala:84)
at org.apache.spark.sql.execution.datasources.DataSource$.lookupDataSource(DataSource.scala:634)
... 13 more