nebula graph版本:3.3.0
nebula studio版本:3.5.0
部署方式:分布式
是否为线上版本:N
我们的graphd,metad,storage服务部署情况如下:

情况描述:
我用python连接nebula,执行两个nGQL语句,如下:
def JD_degree_count(community_num:int,degree:int):
config = Config()
connection_pool = ConnectionPool()
ok = connection_pool.init([('192.168.200.101',9669),('192.168.200.112',9669),('192.168.200.114',9669)], config) # ('192.168.200.101', 9669),('192.168.200.100',9669),
with connection_pool.session_context('root', 'nebula') as session:
session.execute('use ldbc')
for i in range(degree):
result = session.execute(f'LOOKUP ON partition WHERE partition.louvain=={community_num} YIELD id(vertex) AS id \
| GO {degree+1} STEPS FROM $-.id OVER * YIELD $-.id AS src, id($$) AS dst \
| YIELD $-.src AS id, count($-.dst) AS out_degree{degree+1}')
res_df = result_to_df(result)
if i == 0:
tmp = res_df.copy()
continue
connection_pool.close()
res_df = tmp.merge(res_df,on='id',how='left')
res_df = res_df.groupby('id').filter(lambda x:x["out_degree2"] > x["out_degree1"])
res_df["out_degree_sum"] = res_df["out_degree1"]+res_df["out_degree2"]
res_df = res_df.sort_values(by="out_degree_sum",ascending=False).reset_index(drop=True)
return res_df
res = JD_degree_count(94,2)
结果运行一会之后,发生如下报错Connect 192.168.200.101:9669 failed: socket error connecting to host 192.168.200.101, port 9669 (('192.168.200.101', 9669)): timeout('timed out'):
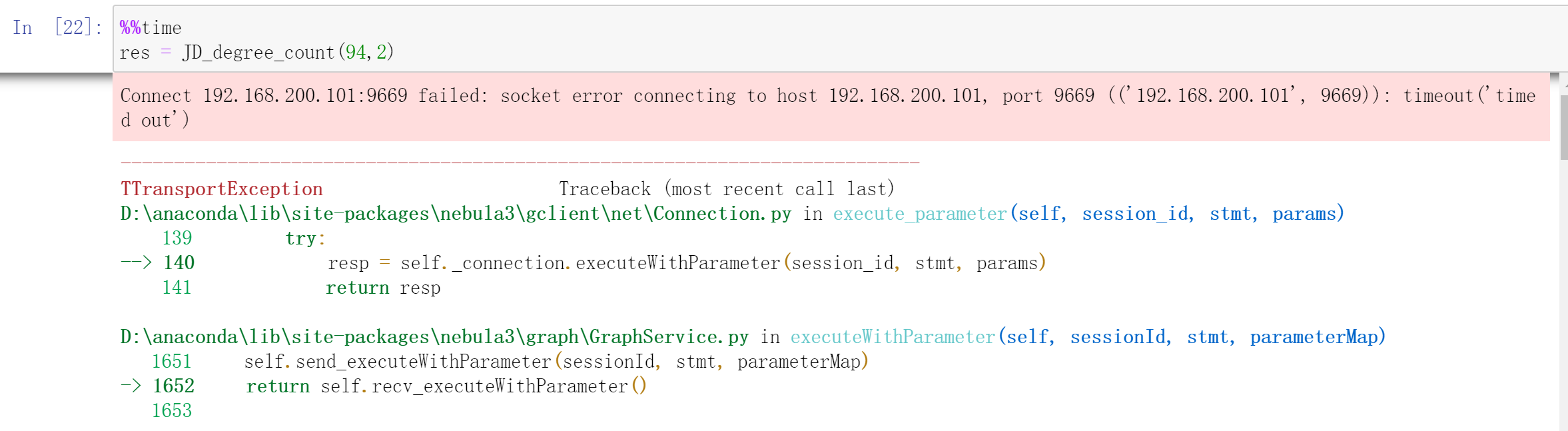
然后我去101服务器上查询graphd状态,是退出状态,我随即将它又启动了起来。
然后查询我之前查过的一个语句:
LOOKUP ON partition WHERE partition.louvain==94 YIELD id(vertex) AS id
结果是8556条
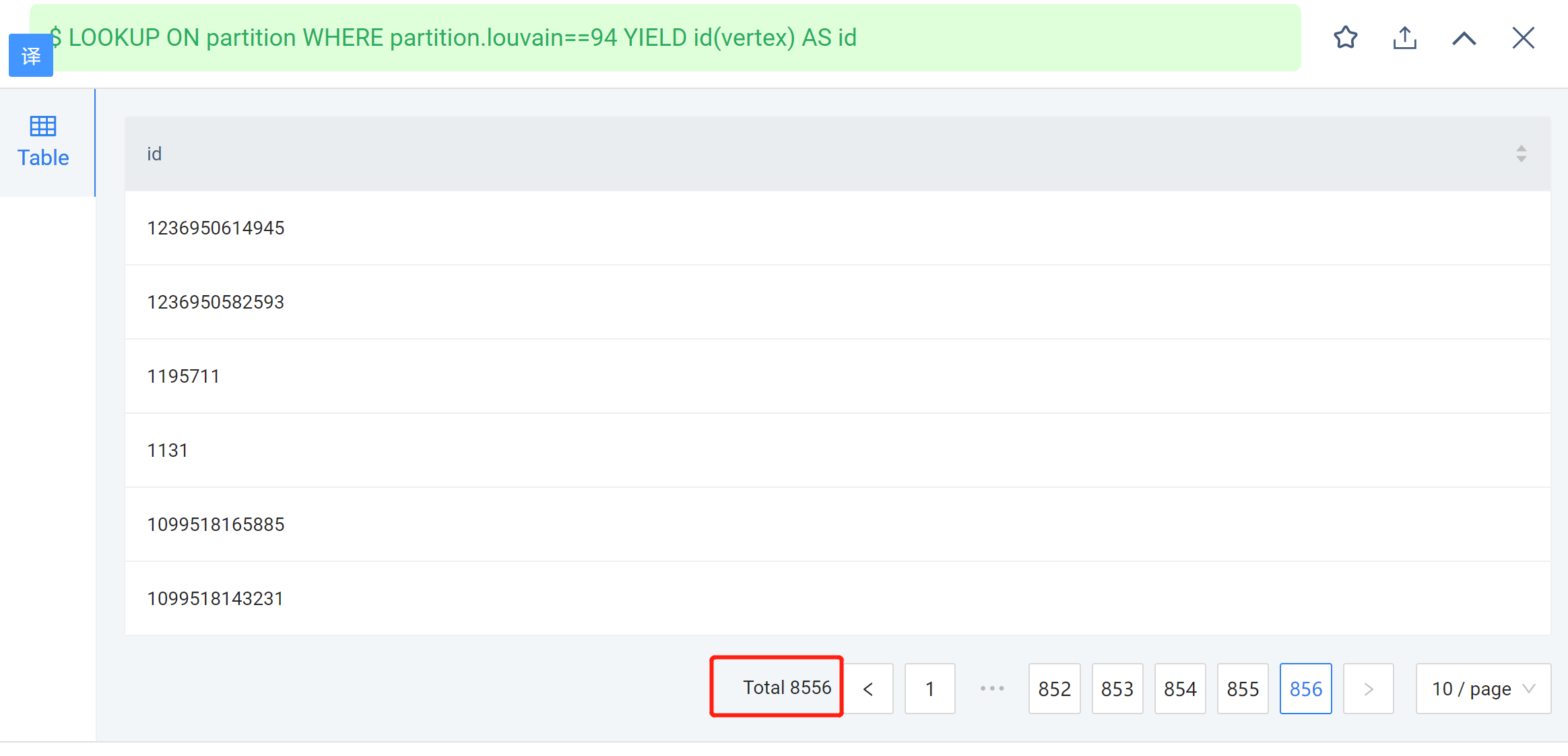
但是之前查询是16000多条:

查询101日志:
进入logs文件夹,查看 graphd-stderr.log
执行
tail -200 graphd-stderr.log,查看日志后200行:
在上面报错中,11:15之前的我记得是我在nebula studio中查询时的报错,应该和本次问题没关系。。

