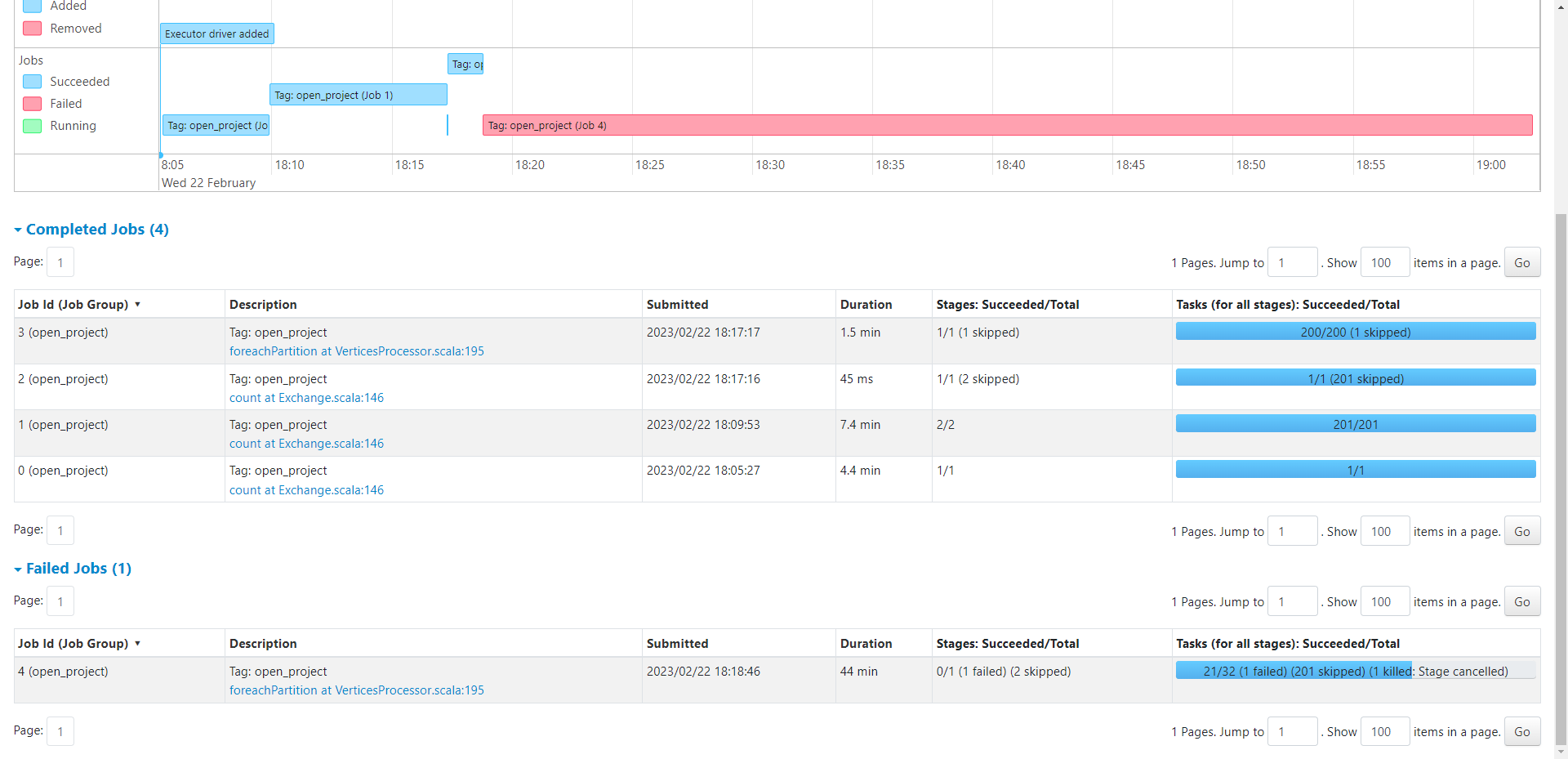
- nebula 版本:3.3.0
- 部署方式:分布式
- 安装方式:Docker
- 是否上生产环境:N
- 硬件信息
- 磁盘 SSD
- CPU、内存信息
- 问题的具体描述
一开始可以正常导入,执行一段时间后就就会报com.vesoft.nebula.client.graph.exception.IOErrorException: java.net.SocketTimeoutException: Read timed out
nebula-exchange版本:nebula-exchange_spark_3.0-3.4.0.jar(github下载)
spark版本:3.3.1
scala版本:2.11.12
导入方式:mysql、csv均使用过
导入命令:
/opt/spark-3.3.1-bin-hadoop3/bin/spark-submit --driver-memory 64G --master "local" --class com.vesoft.nebula.exchange.Exchange nebula-exchange_spark_3.0-3.4.0.jar -c .mysql_application.conf
配置文件:
{
# Spark 相关配置
spark: {
app: {
name: NebulaGraph Exchange 3.3.0
}
driver: {
cores: 1
maxResultSize: 1G
}
cores: {
max: 16
}
}
# NebulaGraph 相关配置
nebula: {
address:{
# 以下为 NebulaGraph 的 Graph 服务和 Meta 服务所在机器的 IP 地址及端口。
# 如果有多个地址,格式为 "ip1:port","ip2:port","ip3:port"。
# 不同地址之间以英文逗号 (,) 隔开。
graph:["127.0.0.1:9669"]
meta:["127.0.0.1:32770"]
}
# 填写的账号必须拥有 NebulaGraph 相应图空间的写数据权限。
user: root
pswd: nebula
# 填写 NebulaGraph 中需要写入数据的图空间名称。
space: xxx
connection: {
timeout: 3000
retry: 3
}
execution: {
retry: 3
}
error: {
max: 32
output: /tmp/errors
}
rate: {
limit: 1024
timeout: 1000
}
}
# 处理点
tags: [
{
# NebulaGraph 中对应的 Tag 名称。
name: open_project
type: {
# 指定数据源文件格式,设置为 MySQL。
source: mysql
# 指定如何将点数据导入 NebulaGraph:Client 或 SST。
sink: client
}
host:192.168.32.11
port:3308
database:"tu"
table:"open_project_vertex"
user:"root"
password:"xxx"
sentence:"select vid, name, version,lj_project_id,author,language,host_type,license,stars,watchers,forks from open_project_vertex order by vid"
# 在 fields 里指定 player 表中的列名称,其对应的 value 会作为 NebulaGraph 中指定属性。
# fields 和 nebula.fields 里的配置必须一一对应。
# 如果需要指定多个列名称,用英文逗号(,)隔开。
fields: [name,version,lj_project_id,author,language,host_type,license,stars,watchers,forks]
nebula.fields: [name,version,lj_project_id,author,language,host_type,license,stars,watchers,forks]
# 指定表中某一列数据为 NebulaGraph 中点 VID 的来源。
vertex: {
field:vid
}
# 单批次写入 NebulaGraph 的数据条数。
batch: 256
# Spark 分区数量
partition: 32
}
# 设置 Tag team 相关信息。
{
name: package
type: {
source: mysql
sink: client
}
host:192.168.32.11
port:3308
database:"tu"
table:"package_vertex"
user:"root"
password:"xxx"
sentence:"select vid,package_id,name,version,type,license from package_vertex order by vid"
fields: [package_id,name,version,type,license]
nebula.fields: [package_id,name,version,type,license]
vertex: {
field: vid
}
batch: 256
partition: 32
}
]
# 处理边数据
edges: [
# 设置 Edge type follow 相关信息
{
# NebulaGraph 中对应的 Edge type 名称。
name: package_dependencies
type: {
# 指定数据源文件格式,设置为 MySQL。
source: mysql
# 指定边数据导入 NebulaGraph 的方式,
# 指定如何将点数据导入 NebulaGraph:Client 或 SST。
sink: client
}
host:192.168.32.11
port:3308
database:"tu"
table:"package_dependencies_edge"
user:"root"
password:"xxx"
sentence:"select src_id,dep_id,dependency from package_dependencies_edge order by src_id"
# 在 fields 里指定 follow 表中的列名称,其对应的 value 会作为 NebulaGraph 中指定属性。
# fields 和 nebula.fields 里的配置必须一一对应。
# 如果需要指定多个列名称,用英文逗号(,)隔开。
fields: [dependency]
nebula.fields: [dependency]
# 在 source 里,将 follow 表中某一列作为边的起始点数据源。
# 在 target 里,将 follow 表中某一列作为边的目的点数据源。
source: {
field: src_id
}
target: {
field: dep_id
}
# 指定一个列作为 rank 的源(可选)。
#ranking: rank
# 单批次写入 NebulaGraph 的数据条数。
batch: 256
# Spark 分区数量
partition: 32
}
]
}
错误日志:
23/02/22 19:02:24 ERROR Executor: Exception in task 21.0 in stage 10.0 (TID 424)
com.vesoft.nebula.client.graph.exception.IOErrorException: java.net.SocketTimeoutException: Read timed out
at com.vesoft.nebula.client.graph.net.SyncConnection.executeWithParameter(SyncConnection.java:191)
at com.vesoft.nebula.client.graph.net.Session.executeWithParameter(Session.java:117)
at com.vesoft.nebula.client.graph.net.Session.execute(Session.java:82)
at com.vesoft.exchange.common.GraphProvider.submit(GraphProvider.scala:78)
at com.vesoft.exchange.common.writer.NebulaGraphClientWriter.writeVertices(ServerBaseWriter.scala:135)
at com.vesoft.nebula.exchange.processor.VerticesProcessor.$anonfun$processEachPartition$1(VerticesProcessor.scala:79)
at com.vesoft.nebula.exchange.processor.VerticesProcessor.$anonfun$processEachPartition$1$adapted(VerticesProcessor.scala:77)
at scala.collection.Iterator.foreach(Iterator.scala:943)
at scala.collection.Iterator.foreach$(Iterator.scala:943)
at scala.collection.AbstractIterator.foreach(Iterator.scala:1431)
at com.vesoft.nebula.exchange.processor.VerticesProcessor.processEachPartition(VerticesProcessor.scala:77)
at com.vesoft.nebula.exchange.processor.VerticesProcessor.$anonfun$process$11(VerticesProcessor.scala:195)
at com.vesoft.nebula.exchange.processor.VerticesProcessor.$anonfun$process$11$adapted(VerticesProcessor.scala:195)
at org.apache.spark.rdd.RDD.$anonfun$foreachPartition$2(RDD.scala:1011)
at org.apache.spark.rdd.RDD.$anonfun$foreachPartition$2$adapted(RDD.scala:1011)
at org.apache.spark.SparkContext.$anonfun$runJob$5(SparkContext.scala:2268)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:90)
at org.apache.spark.scheduler.Task.run(Task.scala:136)
at org.apache.spark.executor.Executor$TaskRunner.$anonfun$run$3(Executor.scala:548)
at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1504)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:551)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)
at java.lang.Thread.run(Thread.java:748)
23/02/22 19:02:24 INFO TaskSetManager: Starting task 22.0 in stage 10.0 (TID 425) (fosscheck-saas-v4, executor driver, partition 22, NODE_LOCAL, 4453 bytes) taskResourceAssignments Map()
23/02/22 19:02:24 INFO Executor: Running task 22.0 in stage 10.0 (TID 425)
23/02/22 19:02:24 WARN TaskSetManager: Lost task 21.0 in stage 10.0 (TID 424) (fosscheck-saas-v4 executor driver): com.vesoft.nebula.client.graph.exception.IOErrorException: java.net.SocketTimeoutException: Read timed out
at com.vesoft.nebula.client.graph.net.SyncConnection.executeWithParameter(SyncConnection.java:191)
at com.vesoft.nebula.client.graph.net.Session.executeWithParameter(Session.java:117)
at com.vesoft.nebula.client.graph.net.Session.execute(Session.java:82)
at com.vesoft.exchange.common.GraphProvider.submit(GraphProvider.scala:78)
at com.vesoft.exchange.common.writer.NebulaGraphClientWriter.writeVertices(ServerBaseWriter.scala:135)
at com.vesoft.nebula.exchange.processor.VerticesProcessor.$anonfun$processEachPartition$1(VerticesProcessor.scala:79)
at com.vesoft.nebula.exchange.processor.VerticesProcessor.$anonfun$processEachPartition$1$adapted(VerticesProcessor.scala:77)
at scala.collection.Iterator.foreach(Iterator.scala:943)
at scala.collection.Iterator.foreach$(Iterator.scala:943)
at scala.collection.AbstractIterator.foreach(Iterator.scala:1431)
at com.vesoft.nebula.exchange.processor.VerticesProcessor.processEachPartition(VerticesProcessor.scala:77)
at com.vesoft.nebula.exchange.processor.VerticesProcessor.$anonfun$process$11(VerticesProcessor.scala:195)
at com.vesoft.nebula.exchange.processor.VerticesProcessor.$anonfun$process$11$adapted(VerticesProcessor.scala:195)
at org.apache.spark.rdd.RDD.$anonfun$foreachPartition$2(RDD.scala:1011)
at org.apache.spark.rdd.RDD.$anonfun$foreachPartition$2$adapted(RDD.scala:1011)
at org.apache.spark.SparkContext.$anonfun$runJob$5(SparkContext.scala:2268)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:90)
at org.apache.spark.scheduler.Task.run(Task.scala:136)
at org.apache.spark.executor.Executor$TaskRunner.$anonfun$run$3(Executor.scala:548)
at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1504)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:551)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)
at java.lang.Thread.run(Thread.java:748)
23/02/22 19:02:24 ERROR TaskSetManager: Task 21 in stage 10.0 failed 1 times; aborting job
23/02/22 19:02:24 INFO ShuffleBlockFetcherIterator: Getting 200 (99.8 MiB) non-empty blocks including 200 (99.8 MiB) local and 0 (0.0 B) host-local and 0 (0.0 B) push-merged-local and 0 (0.0 B) remote blocks
23/02/22 19:02:24 INFO ShuffleBlockFetcherIterator: Started 0 remote fetches in 0 ms
23/02/22 19:02:25 INFO TaskSchedulerImpl: Cancelling stage 10
23/02/22 19:02:25 INFO TaskSchedulerImpl: Killing all running tasks in stage 10: Stage cancelled
23/02/22 19:02:26 INFO GraphProvider: switch space supply_chains_v3
23/02/22 19:02:26 INFO NebulaGraphClientWriter: Connection to List(127.0.0.1:9669)
23/02/22 19:02:26 INFO Executor: Executor is trying to kill task 22.0 in stage 10.0 (TID 425), reason: Stage cancelled
23/02/22 19:02:26 INFO TaskSchedulerImpl: Stage 10 was cancelled
23/02/22 19:02:26 INFO DAGScheduler: ResultStage 10 (foreachPartition at VerticesProcessor.scala:195) failed in 2619.496 s due to Job aborted due to stage failure: Task 21 in stage 10.0 failed 1 times, most recent failure: Lost task 21.0 in stage 10.0 (TID 424) (fosscheck-saas-v4 executor driver): com.vesoft.nebula.client.graph.exception.IOErrorException: java.net.SocketTimeoutException: Read timed out
at com.vesoft.nebula.client.graph.net.SyncConnection.executeWithParameter(SyncConnection.java:191)
at com.vesoft.nebula.client.graph.net.Session.executeWithParameter(Session.java:117)
at com.vesoft.nebula.client.graph.net.Session.execute(Session.java:82)
at com.vesoft.exchange.common.GraphProvider.submit(GraphProvider.scala:78)
at com.vesoft.exchange.common.writer.NebulaGraphClientWriter.writeVertices(ServerBaseWriter.scala:135)
at com.vesoft.nebula.exchange.processor.VerticesProcessor.$anonfun$processEachPartition$1(VerticesProcessor.scala:79)
at com.vesoft.nebula.exchange.processor.VerticesProcessor.$anonfun$processEachPartition$1$adapted(VerticesProcessor.scala:77)
at scala.collection.Iterator.foreach(Iterator.scala:943)
at scala.collection.Iterator.foreach$(Iterator.scala:943)
at scala.collection.AbstractIterator.foreach(Iterator.scala:1431)
at com.vesoft.nebula.exchange.processor.VerticesProcessor.processEachPartition(VerticesProcessor.scala:77)
at com.vesoft.nebula.exchange.processor.VerticesProcessor.$anonfun$process$11(VerticesProcessor.scala:195)
at com.vesoft.nebula.exchange.processor.VerticesProcessor.$anonfun$process$11$adapted(VerticesProcessor.scala:195)
at org.apache.spark.rdd.RDD.$anonfun$foreachPartition$2(RDD.scala:1011)
at org.apache.spark.rdd.RDD.$anonfun$foreachPartition$2$adapted(RDD.scala:1011)
at org.apache.spark.SparkContext.$anonfun$runJob$5(SparkContext.scala:2268)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:90)
at org.apache.spark.scheduler.Task.run(Task.scala:136)
at org.apache.spark.executor.Executor$TaskRunner.$anonfun$run$3(Executor.scala:548)
at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1504)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:551)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)
at java.lang.Thread.run(Thread.java:748)
Driver stacktrace:
23/02/22 19:02:26 INFO DAGScheduler: Job 4 failed: foreachPartition at VerticesProcessor.scala:195, took 2619.509663 s
Exception in thread "main" org.apache.spark.SparkException: Job aborted due to stage failure: Task 21 in stage 10.0 failed 1 times, most recent failure: Lost task 21.0 in stage 10.0 (TID 424) (fosscheck-saas-v4 executor driver): com.vesoft.nebula.client.graph.exception.IOErrorException: java.net.SocketTimeoutException: Read timed out
at com.vesoft.nebula.client.graph.net.SyncConnection.executeWithParameter(SyncConnection.java:191)
at com.vesoft.nebula.client.graph.net.Session.executeWithParameter(Session.java:117)
at com.vesoft.nebula.client.graph.net.Session.execute(Session.java:82)
at com.vesoft.exchange.common.GraphProvider.submit(GraphProvider.scala:78)
at com.vesoft.exchange.common.writer.NebulaGraphClientWriter.writeVertices(ServerBaseWriter.scala:135)
at com.vesoft.nebula.exchange.processor.VerticesProcessor.$anonfun$processEachPartition$1(VerticesProcessor.scala:79)
at com.vesoft.nebula.exchange.processor.VerticesProcessor.$anonfun$processEachPartition$1$adapted(VerticesProcessor.scala:77)
at scala.collection.Iterator.foreach(Iterator.scala:943)
at scala.collection.Iterator.foreach$(Iterator.scala:943)
at scala.collection.AbstractIterator.foreach(Iterator.scala:1431)
at com.vesoft.nebula.exchange.processor.VerticesProcessor.processEachPartition(VerticesProcessor.scala:77)
at com.vesoft.nebula.exchange.processor.VerticesProcessor.$anonfun$process$11(VerticesProcessor.scala:195)
at com.vesoft.nebula.exchange.processor.VerticesProcessor.$anonfun$process$11$adapted(VerticesProcessor.scala:195)
at org.apache.spark.rdd.RDD.$anonfun$foreachPartition$2(RDD.scala:1011)
at org.apache.spark.rdd.RDD.$anonfun$foreachPartition$2$adapted(RDD.scala:1011)
at org.apache.spark.SparkContext.$anonfun$runJob$5(SparkContext.scala:2268)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:90)
at org.apache.spark.scheduler.Task.run(Task.scala:136)
at org.apache.spark.executor.Executor$TaskRunner.$anonfun$run$3(Executor.scala:548)
at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1504)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:551)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)
at java.lang.Thread.run(Thread.java:748)
Driver stacktrace:
at org.apache.spark.scheduler.DAGScheduler.failJobAndIndependentStages(DAGScheduler.scala:2672)
at org.apache.spark.scheduler.DAGScheduler.$anonfun$abortStage$2(DAGScheduler.scala:2608)
at org.apache.spark.scheduler.DAGScheduler.$anonfun$abortStage$2$adapted(DAGScheduler.scala:2607)
at scala.collection.mutable.ResizableArray.foreach(ResizableArray.scala:62)
at scala.collection.mutable.ResizableArray.foreach$(ResizableArray.scala:55)
at scala.collection.mutable.ArrayBuffer.foreach(ArrayBuffer.scala:49)
at org.apache.spark.scheduler.DAGScheduler.abortStage(DAGScheduler.scala:2607)
at org.apache.spark.scheduler.DAGScheduler.$anonfun$handleTaskSetFailed$1(DAGScheduler.scala:1182)
at org.apache.spark.scheduler.DAGScheduler.$anonfun$handleTaskSetFailed$1$adapted(DAGScheduler.scala:1182)
at scala.Option.foreach(Option.scala:407)
at org.apache.spark.scheduler.DAGScheduler.handleTaskSetFailed(DAGScheduler.scala:1182)
at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.doOnReceive(DAGScheduler.scala:2860)
at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.onReceive(DAGScheduler.scala:2802)
at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.onReceive(DAGScheduler.scala:2791)
at org.apache.spark.util.EventLoop$$anon$1.run(EventLoop.scala:49)
at org.apache.spark.scheduler.DAGScheduler.runJob(DAGScheduler.scala:952)
at org.apache.spark.SparkContext.runJob(SparkContext.scala:2228)
at org.apache.spark.SparkContext.runJob(SparkContext.scala:2249)
at org.apache.spark.SparkContext.runJob(SparkContext.scala:2268)
at org.apache.spark.SparkContext.runJob(SparkContext.scala:2293)
at org.apache.spark.rdd.RDD.$anonfun$foreachPartition$1(RDD.scala:1011)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:151)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:112)
at org.apache.spark.rdd.RDD.withScope(RDD.scala:406)
at org.apache.spark.rdd.RDD.foreachPartition(RDD.scala:1009)
at org.apache.spark.sql.Dataset.$anonfun$foreachPartition$1(Dataset.scala:3061)
at scala.runtime.java8.JFunction0$mcV$sp.apply(JFunction0$mcV$sp.java:23)
at org.apache.spark.sql.Dataset.$anonfun$withNewRDDExecutionId$1(Dataset.scala:3845)
at org.apache.spark.sql.execution.SQLExecution$.$anonfun$withNewExecutionId$6(SQLExecution.scala:109)
at org.apache.spark.sql.execution.SQLExecution$.withSQLConfPropagated(SQLExecution.scala:169)
at org.apache.spark.sql.execution.SQLExecution$.$anonfun$withNewExecutionId$1(SQLExecution.scala:95)
at org.apache.spark.sql.SparkSession.withActive(SparkSession.scala:779)
at org.apache.spark.sql.execution.SQLExecution$.withNewExecutionId(SQLExecution.scala:64)
at org.apache.spark.sql.Dataset.withNewRDDExecutionId(Dataset.scala:3843)
at org.apache.spark.sql.Dataset.foreachPartition(Dataset.scala:3061)
at com.vesoft.nebula.exchange.processor.VerticesProcessor.process(VerticesProcessor.scala:195)
at com.vesoft.nebula.exchange.Exchange$.$anonfun$main$2(Exchange.scala:163)
at com.vesoft.nebula.exchange.Exchange$.$anonfun$main$2$adapted(Exchange.scala:133)
at scala.collection.immutable.List.foreach(List.scala:431)
at com.vesoft.nebula.exchange.Exchange$.main(Exchange.scala:133)
at com.vesoft.nebula.exchange.Exchange.main(Exchange.scala)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.spark.deploy.JavaMainApplication.start(SparkApplication.scala:52)
at org.apache.spark.deploy.SparkSubmit.org$apache$spark$deploy$SparkSubmit$$runMain(SparkSubmit.scala:958)
at org.apache.spark.deploy.SparkSubmit.doRunMain$1(SparkSubmit.scala:180)
at org.apache.spark.deploy.SparkSubmit.submit(SparkSubmit.scala:203)
at org.apache.spark.deploy.SparkSubmit.doSubmit(SparkSubmit.scala:90)
at org.apache.spark.deploy.SparkSubmit$$anon$2.doSubmit(SparkSubmit.scala:1046)
at org.apache.spark.deploy.SparkSubmit$.main(SparkSubmit.scala:1055)
at org.apache.spark.deploy.SparkSubmit.main(SparkSubmit.scala)
Caused by: com.vesoft.nebula.client.graph.exception.IOErrorException: java.net.SocketTimeoutException: Read timed out
at com.vesoft.nebula.client.graph.net.SyncConnection.executeWithParameter(SyncConnection.java:191)
at com.vesoft.nebula.client.graph.net.Session.executeWithParameter(Session.java:117)
at com.vesoft.nebula.client.graph.net.Session.execute(Session.java:82)
at com.vesoft.exchange.common.GraphProvider.submit(GraphProvider.scala:78)
at com.vesoft.exchange.common.writer.NebulaGraphClientWriter.writeVertices(ServerBaseWriter.scala:135)
at com.vesoft.nebula.exchange.processor.VerticesProcessor.$anonfun$processEachPartition$1(VerticesProcessor.scala:79)
at com.vesoft.nebula.exchange.processor.VerticesProcessor.$anonfun$processEachPartition$1$adapted(VerticesProcessor.scala:77)
at scala.collection.Iterator.foreach(Iterator.scala:943)
at scala.collection.Iterator.foreach$(Iterator.scala:943)
at scala.collection.AbstractIterator.foreach(Iterator.scala:1431)
at com.vesoft.nebula.exchange.processor.VerticesProcessor.processEachPartition(VerticesProcessor.scala:77)
at com.vesoft.nebula.exchange.processor.VerticesProcessor.$anonfun$process$11(VerticesProcessor.scala:195)
at com.vesoft.nebula.exchange.processor.VerticesProcessor.$anonfun$process$11$adapted(VerticesProcessor.scala:195)
at org.apache.spark.rdd.RDD.$anonfun$foreachPartition$2(RDD.scala:1011)
at org.apache.spark.rdd.RDD.$anonfun$foreachPartition$2$adapted(RDD.scala:1011)
at org.apache.spark.SparkContext.$anonfun$runJob$5(SparkContext.scala:2268)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:90)
at org.apache.spark.scheduler.Task.run(Task.scala:136)
at org.apache.spark.executor.Executor$TaskRunner.$anonfun$run$3(Executor.scala:548)
at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1504)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:551)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)
at java.lang.Thread.run(Thread.java:748)
23/02/22 19:02:26 INFO NebulaGraphClientWriter: write open_project, batch size(256), latency(419417)
23/02/22 19:02:26 INFO Executor: Executor killed task 22.0 in stage 10.0 (TID 425), reason: Stage cancelled
23/02/22 19:02:26 WARN TaskSetManager: Lost task 22.0 in stage 10.0 (TID 425) (fosscheck-saas-v4 executor driver): TaskKilled (Stage cancelled)
23/02/22 19:02:26 INFO TaskSchedulerImpl: Removed TaskSet 10.0, whose tasks have all completed, from pool
23/02/22 19:05:20 INFO BlockManagerInfo: Removed broadcast_5_piece0 on fosscheck-saas-v4:44675 in memory (size: 29.0 KiB, free: 32.4 GiB)
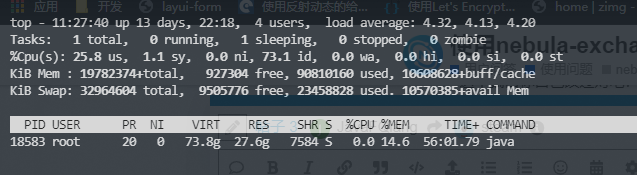
- spack控制台: