作者:Steam & Hao
本文整理自社区第 7 期会议中 13‘21″ 到 44’11″ 的 Python ORM 的分享,视频见 https://www.bilibili.com/video/BV1s8411N7Cw
在做业务开发时,NebulaGraph Python ORM 项目作者:Sword Elucidator(下文简称:Hao)发现图数据库在某些场景下有比较不错的应用实践,而 NebulaGraph 是他觉得不错、较为先进的一款图数据库产品。在 Hao 的开发过程中,他发现:虽然图数据库被应用在多个业务场景中,但对于像是 App 开发之类的 ISO/OSI 高层实践的话,nebula-python 之类的客户端就略显笨重。
而 ORM 作为一个能简化 CURD 操作、免去繁琐的查询语句编写的存在,是被广大的 Web 开发者所熟知。但是,目前 NebulaGraph 社区有 Golang 版本的 ORM norm、Java ORM NGBatis 和 graph-ocean 唯独没有 Hao 所熟悉的 Python 语言的 ORM。
于是,做一个 NebulaGraph Python ORM 的想法便诞生了。
NebulaGraph Python ORM
Nebula Carina 名字的由来
NebulaGraph Python ORM,又名 nebula-carina,虽然目前只是一个雏形,但是已经基本上具备了一个 ORM 的基础功能。在命名 Python ORM 项目之时,Hao 先想到了 nebula-model,见名便知这是一个 ORM,搞了一些封装。但它不够优雅(cool),所以 nebula-carina 便诞生了。
Carina 船底座,/kəˈriːnə/,意为龙骨,是南半球可见最大的星云。而一个组件能成为一个 Nebula(星云)还挺酷的。
Python ORM 功能设计
Nebula Carina 是用 Python 开发的针对 NebulaGraph + Python 的 ORM 框架。在设计上没有局限于 Web 框架,因此可以被应用在 Django、FastAPI 和 Flask 等主流框架上。
目前,Nebula Carina 包含了常规的 schema 定义、对象管理器 object manager(雏形)、Model Builder(雏形),以及常见的图语言、MATCH 语句封装。雏形的意思是,这些功能具备了,但是暂时只有一、两个方法在里面,欢迎阅读本文的你一起来完善。除了基础功能之外,Nebula Carina 还支持了简单的 migration 功能,能够自动计算 schema model 结构与 DB schema 的差异,并同步 schema 到当前 space。但相较于其他成熟的 ORM 项目,例如:Django ORM,Nebula Carina 缺少可回溯性及树状结构来支持 migration 包含依赖、merge 数据。所以,Nebula Carina 未来考虑设计和支持包含依赖关系的 migration 系统。如果你对此有兴趣的话,欢迎来项目:https://github.com/nebula-contrib/nebula-carina issue 区交流下。
Python ORM 的神奇之处
上面简单说了下 Nebula Carina 是什么,有什么功能。在这里,我们来解决下“为什么要用 Nebula Carina”的问题。
Nebula Carina 首要应对的问题是快速解决轻量级 App 开发的常规需求,虽然 NebulaGraph 具有极好的性能,诸如美团、快手等大企业都在使用。但大企业和小公司不同,大企业用图数据库会用非常重,像美团就直接开发了个图平台对接集团上百的业务线。而小公司的轻量级应用来说,它需要一个快速地生成简洁 schema。小公司的 Web 开发人员能非常容易地定义常用的、供于业务逻辑使用的 schema,再一键快速将 schema 同步到 space,而不需要去写些 SQL(这里指的是查询语句)来处理这些事项。此外,应对小公司的轻量级 App 开发需求,还需要支持 JSON 序列化和逆序列化来简化接口,不需要在接口处封装各类东西。最后,也是最重要的,为什么不用 Golang 之类的语言 ORM。Nebula Carina 采用了易于使用的 Python Data Model。Python 使用人员可以方便地用 Python 来调用、控制程序,像是打印,或者是在 Python Model 里面将 Dictionary 展开时拥有的 fields 都可以符合标准 Python 规范进行使用。
此外,除了适用于任何的 Python Web Framework,Nebula Carina 也适用于裸 Python 开发,可与 AI 行业快速集成。毕竟像是 Machine Learning 之类的,十有八九是 Python 语言搞的,Nebula Carina 就可以轻松应用在 GNN、NLP 这些用图数据比较多的技术领域。
总之,Nebula Carina 让 Python 开发者使用 NebulaGraph 时能把更多精力运用在业务/模型上,而非繁琐的数据库操作。
Python ORM 设计实现
目前,Carina 的实现比较简单粗暴,由 4 个部分组成:settings、nGQL 层、model 层和其他。
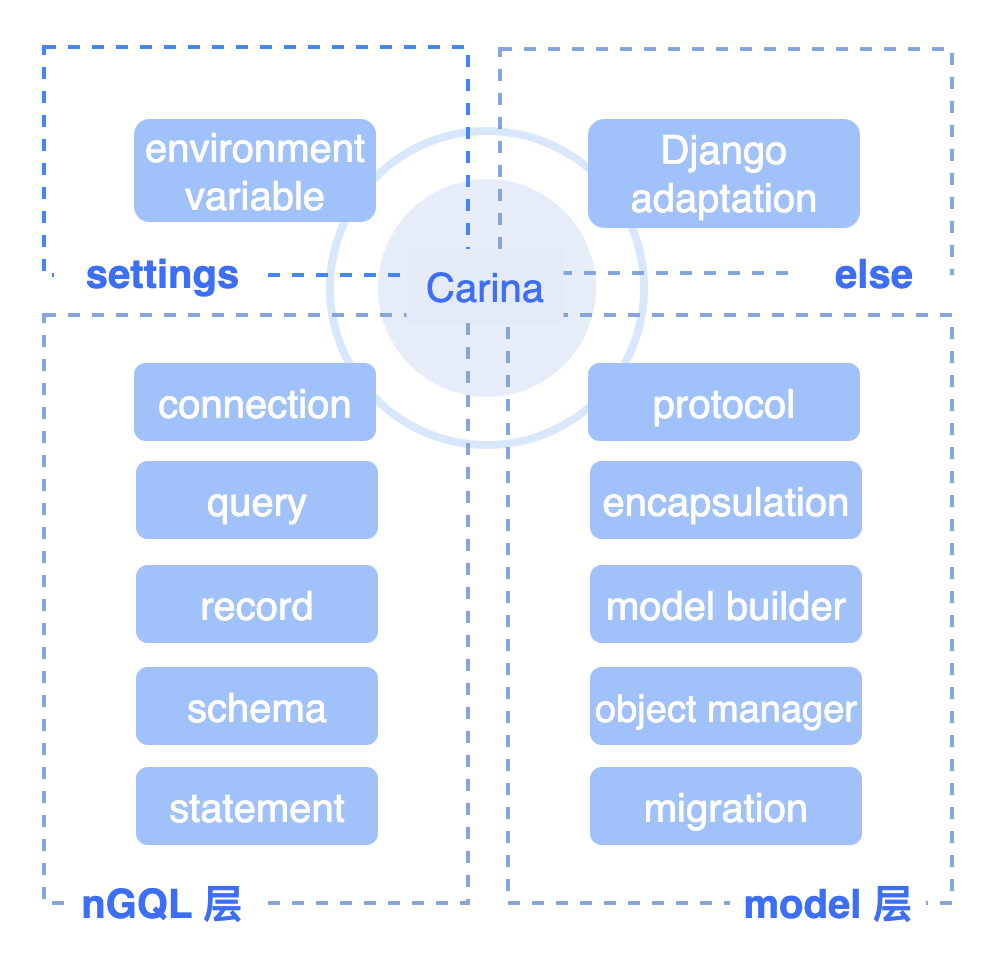
settings,搞环境变量。
nGQL 层,有 connection、query、record、schema 和 statement:
- query,主要是 condition / match / … 语句封装
- record,主要是 vertex / edge 语句封装
- schema,封装了 Data Types、schema 语句、space 语句封装
- statements,主要是 Order By、Limit、Edge 定义、Edge Value、TTL、Alter 等 statements 的语句封装,statement 的意思是 state 某类行为;
model 层,主要是调用 nGQL 层的封装的 class 和当中的方法,来解决一些具体上层的问题。它包括 nebula-python 的 vertex / edge 转成 Carina 的 vertex model / edge model 的 protocol,以及 field 和 model(schema model & data model)的封装,同绝大数编程语言的 ORM 类似,定义成某类语言常见的 class 进行封装,参见下方 Figure 类的示例说明;
class Figure(models.TagModel):
name: str = _(data_types.FixedString(30), ..., )
age: int = _(data_types.Int16, ..., )
valid_until: int = _(data_types.Int64, None, )
hp: int = _(data_types.Int16, 100, )
style: str = _(data_types.FixedString(10), 'rap', )
is_virtual: bool = _(data_types.Bool, True)
created_on: datetime = _(data_types.Datetime, data_types.Datetime.auto)
some_dt: datetime = _(data_types.Datetime, datetime(2022, 1, 1))
上述示例代码,用 Figure class 继承 TagModel,在当中定义 tag 所需的这些 field,比如:name、age…Carina 就是采用这种方式来处理 NebulaGraph 中 Schema 结构;
model 层中的 model builder 则是位于 nGQL 和纯 model 层之间的桥梁。它可以用来描述高层和低层之间的某种行为,比如说,下面的代码就定义了一个全局 MATCH 语句,而所有的 MATCH 语句都会走这样一个函数同 nGQL 层交互:
def match(
pattern: str, to_model_dict: dict[str, Type[NebulaConvertableProtocol]],
*, distinct_field: str = None,
condition: Condition = None, order_by: OrderBy = None, limit: Limit = None
) -> Iterable[SingleMatchResult]: # should be model
output = ', '.join(
("DISTINCT " if key == distinct_field else "") + key
for key in to_model_dict.keys()
)
results = match(pattern, output, condition, order_by, limit)
return (
SingleMatchResult({
key: to_model_dict[key].from_nebula_db_cls(value.value)
for key, value in zip(results.keys(), row.values) if key in to_model_dict
}) for row in results.rows()
)
而 model 层的 object manager 会根据应用场景,基于 schema 为出发点,对 model builder 具体 match 语句进行操作,对这些操作行为搞了个高级封装;migrations 则负责封装 schema model 的变更并同步给数据库;
在其他模块,则是 Django 适配的 apps 和 setting。因为要支持 Django,它的思路同 FastAPI 不同,所以需要做适配来让 Carina 无缝衔接 Django;
Nebula Carina 使用
下面举些例子来让大家了解下 Carina 的使用,主要还是摘录自 Carina 的 README:https://github.com/nebula-contrib/nebula-carina
安装 Nebula Carina
一句命令搞定
pip install nebula-carina
如果你用的是 Django,那么需要将 nebula_carina 添加到 INSTALLED_APPS,像是这样:
INSTALLED_APPS = [
...
'nebula_carina',
...
]
再在 settings.py 文件中设置 CARINA_SETTINGS,主要配置一些同 NebulaGraph 有关的信息。像是这样:
CARINA_SETTINGS = {
"auto_create_default_space_with_vid_desc": "FIXED_STRING(20)", #创建默认图空间
"default_space": "main", #图空间名
"max_connection_pool_size": 10, #连接数大小
"model_paths": ["nebula.carina"], #model 路径
"user_name": "root", #登陆 NebulaGraph 的用户名
"password": "1234", #登陆 NebulaGraph 的密码
"servers": ["192.168.31.248:9669"], # NebulaGraph graphd 服务所在服务器信息,可配置多个
"timezone_name": "UTC", #服务器所用时区
}
目前 Carina 只有支持上述信息,后续会再增加其他字段。
如果你用的是 FastAPI 之类的,用环境变量即可,具体的话可以参考项目文档:https://github.com/nebula-contrib/nebula-carina#by-environment-variables。
图空间创建
你可以通过下面 Python 语句来创建 Space,当然你也可以像上面 CARINA_SETTINGS 一样,用 "auto_create_default_space_with_vid_desc": "FIXED_STRING(20)" 自动创建一个默认图空间。
from nebula_carina.ngql.schema.space import create_space, show_spaces, VidTypeEnum
main_space_name = "main"
if main_space_name not in show_spaces():
create_space(main_space_name, (VidTypeEnum.FIXED_STRING, 20))
点边 schema 定义
同点 vertex 不同,一条边只有一个 edgetype,而一个点可以拥有多个 tag。所以在 Carina 中,Model 层的封装,models.py 文件里引入了 VirtualCharacter 的概念,在 VirtualCharacter 类里,定义这个点拥有那些 tag。
class VirtualCharacter(models.VertexModel):
figure: Figure
source: Source
一个 figure 就是一个 tag,source 是另外一个 tag 的名字。这里 Figure 和 Source 都是具体的某个 tag 在 Carina 中的映射类名,在示例中,它就叫 Figure、Source。
点边数据操作
上文提过 VirtualCharacter 的概念,在 Data Model Mathod 里,像下面这种代码:
VirtualCharacter(
vid='char_test1', figure=Figure(
name='test1', age=100, is_virtual=False, some_dt=datetime(2021, 3, 3, 0, 0, 0, 12)
), source=Source(name='movie1')
).save()
是定义了一个 VID(唯一标识)为 char_test1 的点,它拥有个名为 Figure 的 tag,这个 tag 中有 name、age、is_virtual 之类的属性。此外,它还有一个 tag Source,Source tag 的属性 name 是 movie1。而 .save() 则是保存这段代码。
同点类似,边的定义是这样的:
EdgeModel(src_vid='char_test1', dst_vid='char_test2', ranking=0, edge_type=Love(way='gun', times=40)).save()
这个语句主要表达了一条边的起点是 char_test1,终点是 char_test2,边的 rank 是 0,类型是 Love。而 Love 边类型有 2 个属性 way 和 times,![]() 也许这是一对相杀相爱的恋人,滚了 40 次。
也许这是一对相杀相爱的恋人,滚了 40 次。
Nebula Carina 再升级
因为个人能力有限,在这里希望借助大家的力量。对 Nebula Carina 的未来规划,主要集中在这些方面
- connection pool (v3.3.0)
- Indexes
- Go / Fetch / Lookup statements封装
- Bulk操作封装
- Generic Vertex Model
- advanced migrations
…
nebula-python 在 v3.3.0 中对 connection pool 做了原生支持,希望在未来 Carina 能结合这块内容更加完善。
再者就是索引,上面其实提到过,Carina 目前就封装了 MATCH 语句,后续将会对 LOOKUP、GO、FETCH 之类的 statement 字句进行封装。
然后是 Bulk 操作的封装,可以处理一次性创建大量数据。
Generic Vertex Model 则是再抽象 vertex,用户不需要告诉程序它想得到什么样的 vertex,它的结构是如何的。直接通过虚拟结构进行定义,像是上面提到的 Figuer 和 Source,现在我不定义了,Generic Vertex Model 可以把这块抽象好,自己就搞定了。
最后,之前也提到过的 advanced migrations,树状的 migration 可以搞定依赖关系。
以上,便是 Hao 贡献的 NebulaGraph Python ORM 的简单介绍。如果你有改进、优化它的 idea,欢迎来 Carina issue 和 pr 区交流哟 https://github.com/nebula-contrib/nebula-carina/issues/new~
谢谢你读完本文 (///▽///)
NebulaGraph Desktop,Windows 和 macOS 用户安装图数据库的绿色通道,10s 拉起搞定海量数据的图服务。通道传送门:http://c.nxw.so/c0svX
想看源码的小伙伴可以前往 GitHub 阅读、使用、(^з^)-☆ star 它 → GitHub;和其他的 NebulaGraph 用户一起交流图数据库技术和应用技能,留下「你的名片」一起玩耍呢~