nebula 版本:3.0.0
nebula-spark-connector版本:3.4.0
spark版本:2.2.1/3.0.2
按照ReadMe里面的说明分别编译了nebula-spark-connector-2.2_3.4.0.jar和nebula-spark-connector-3.4.0.jar
起spark环境的魔法命令
%%spark
--conf spark.driver.allowMultipleContexts=true
--conf spark.yarn.queue=root.zw02_2.hadoop
--conf spark.files.overwrite=true
然后我是通过add jar的方式添加的
%%sql add_jar
add jar viewfs://file-path/nebula-spark-connector-3.0.0.jar
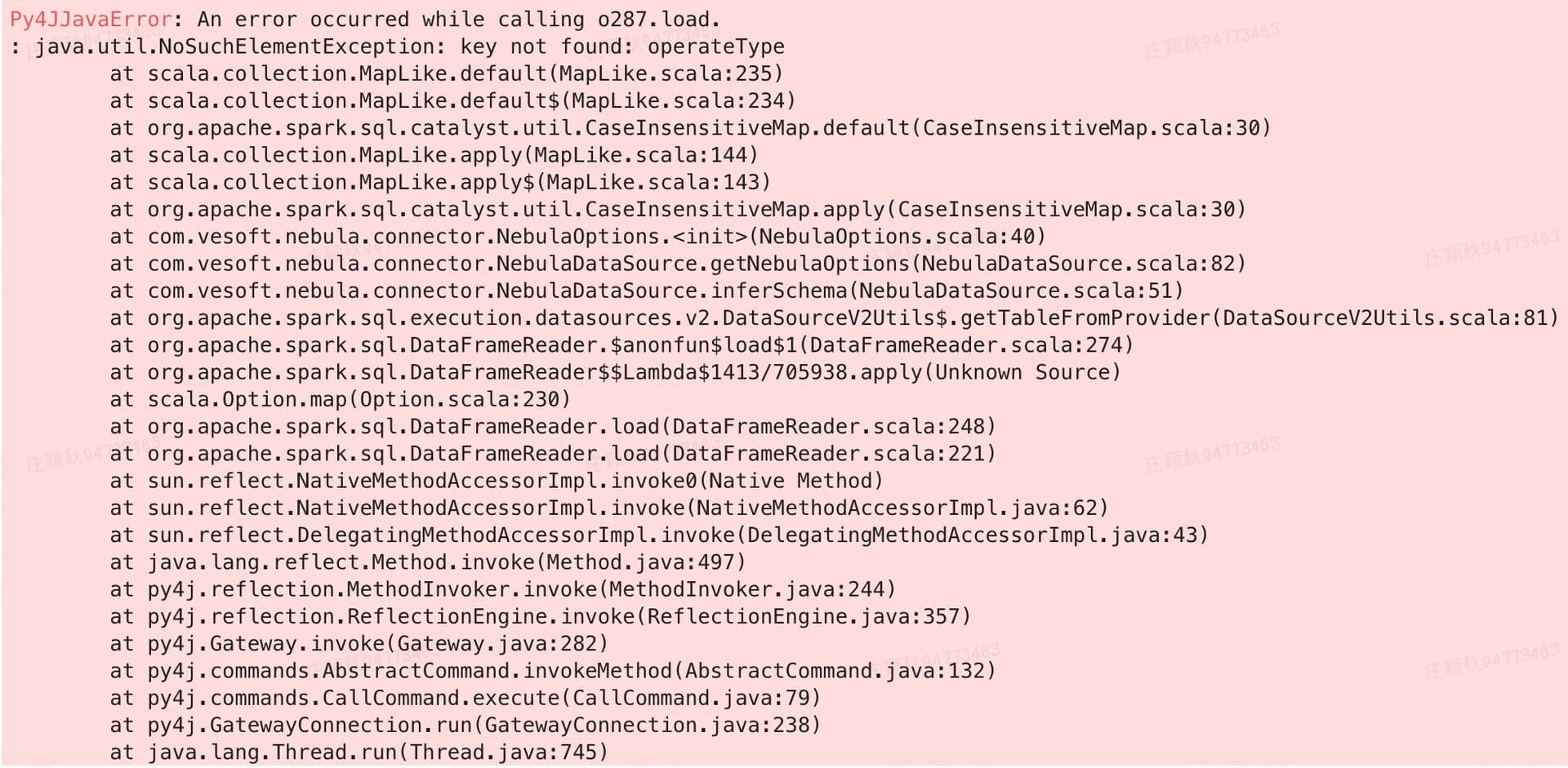
现在的问题是,在执行
df = spark.read.format(
"com.vesoft.nebula.connector.NebulaDataSource").option(
"type", "edge").option(
"spaceName", "social").option(
"label", "relation").option(
"returnCols", "prob").option(
"metaAddress", "metad0:45500").option(
"partitionNumber", 1).load()
的时候,spark3.0报错java.lang.NoClassDefFoundError: Could not initialize class org.apache.hadoop.hdfs.BlockReaderFactory,spark2.2环境报错java.lang.NoClassDefFoundError: com/vesoft/nebula/connector/exception/IllegalOptionException
add jar方式没引入成功?
spark = SparkSession.builder.appName(
"Test").master(
"local").config(
"spark.jars","/Users/nicole/Desktop/nebula-spark-connector_3.0-3.5.0-jar-with-dependencies.jar").config(
"spark.driver.extraClassPath","/Users/nicole/Desktop/nebula-spark-connector_3.0-3.5.0-jar-with-dependencies.jar").getOrCreate()
nicole:
"spark.jars"
在%%spark里面–conf加了您给的两个参数,现在3.0的环境也报java.lang.NoClassDefFoundError: com/vesoft/nebula/connector/exception/IllegalOptionException了
你打包之后会生成xxx-jar-with-dependencies.jar 的包, 你看下上面我发的代码,要引用这个with-dependencies
1 个赞
我spark2.2的环境通了,然后发现nebula-algorithm好像不支持2.2。
git clone https://github.com/vesoft-inc/nebula-spark-connector.git
cd nebula-spark-connector/nebula-spark-connector_3.0
mvn clean package -Dmaven.test.skip=true -Dgpg.skip -Dmaven.javadoc.skip=true
然后用这个包走我之前跑通的代码报如下错误
想确认一下,按照这个代码打出来的nebula-spark-connector_3.0-3.0-SNAPSHOT-jar-with-dependencies.jar只有14M是正常的吗?我之前打出来其他的都有140+M
$ git clone https://github.com/vesoft-inc/nebula-spark-connector.git
$ cd nebula-spark-connector/nebula-spark-connector_3.0
$ mvn clean package -Dmaven.test.skip=true -Dgpg.skip -Dmaven.javadoc.skip=true
而且引用这个包用spark3.0读数的话会报上面那个错误
正常的,因为当前master分支的代码将spark的依赖scope设置为了provide,这样打包的时候不会将spark的依赖打进去,所以包的size小了很多。
你不要进入子目录打包,因为每个connector目录都依赖了common模块。你用这个命令在根目录下去打包, mvn clean package -Dgpg.skip -Dmaven.javadoc.skip=true -Dmaven.test.skip=true -pl nebula-spark-connector_3.0 -am -Pscala-2.12 -Pspark-3.0
ps:我刚在scala shell中用打成的14m的assembly包去执行 ok的。
system
2023 年3 月 17 日 06:10
9
此话题已在最后回复的 7 天后被自动关闭。不再允许新回复。