- 部署方式:分布式
- 安装方式:源码编译
- 是否上生产环境:Y
- 硬件信息
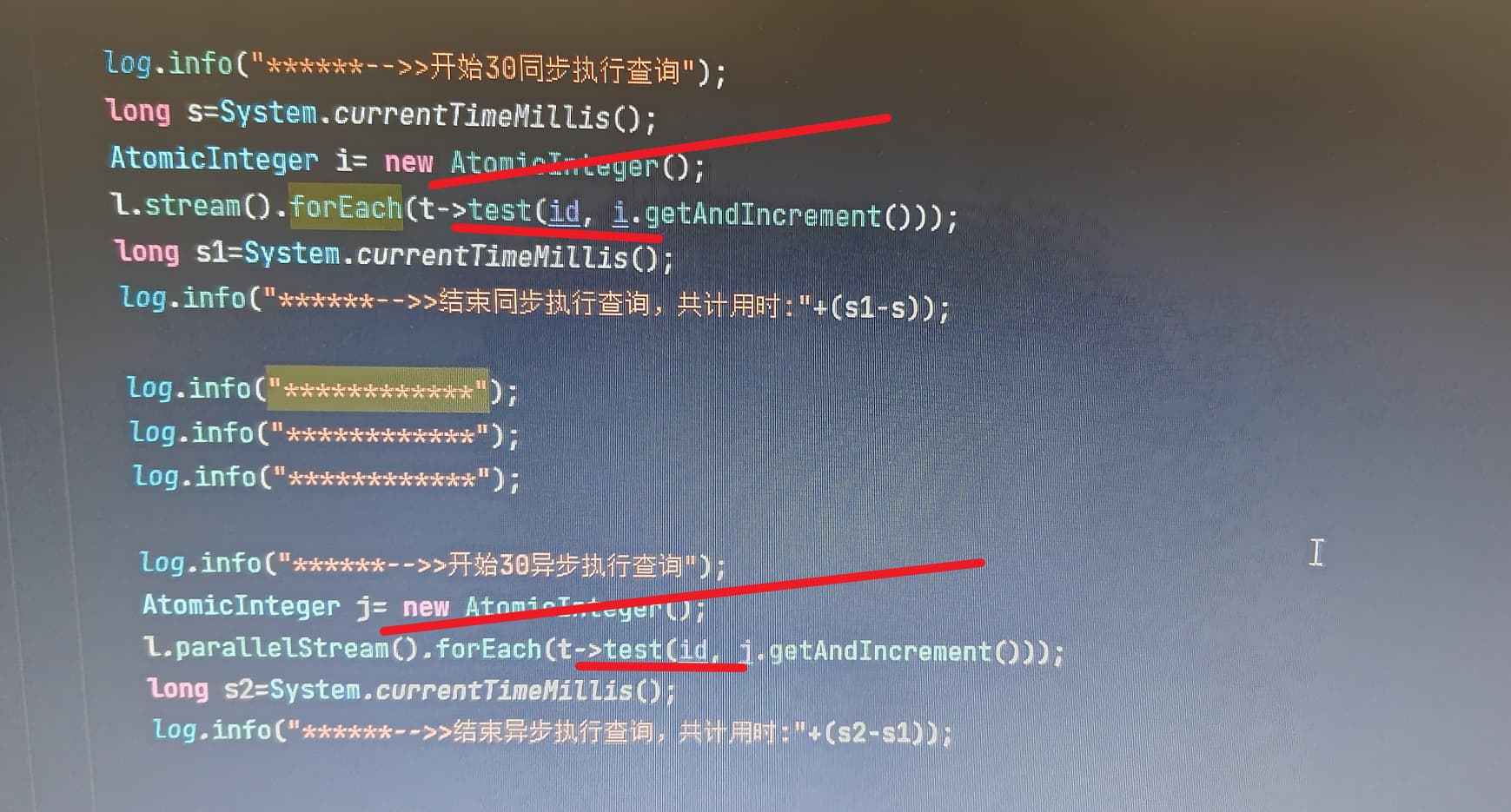
- parallelstream并行查询图数据库,发现这个并发执行查询的时间与单线程比拉慢了很多。就类似单线程一个个执行的叠加。我们猜是不是图数据库在并发执行查询时并没有做到同时响应呢?
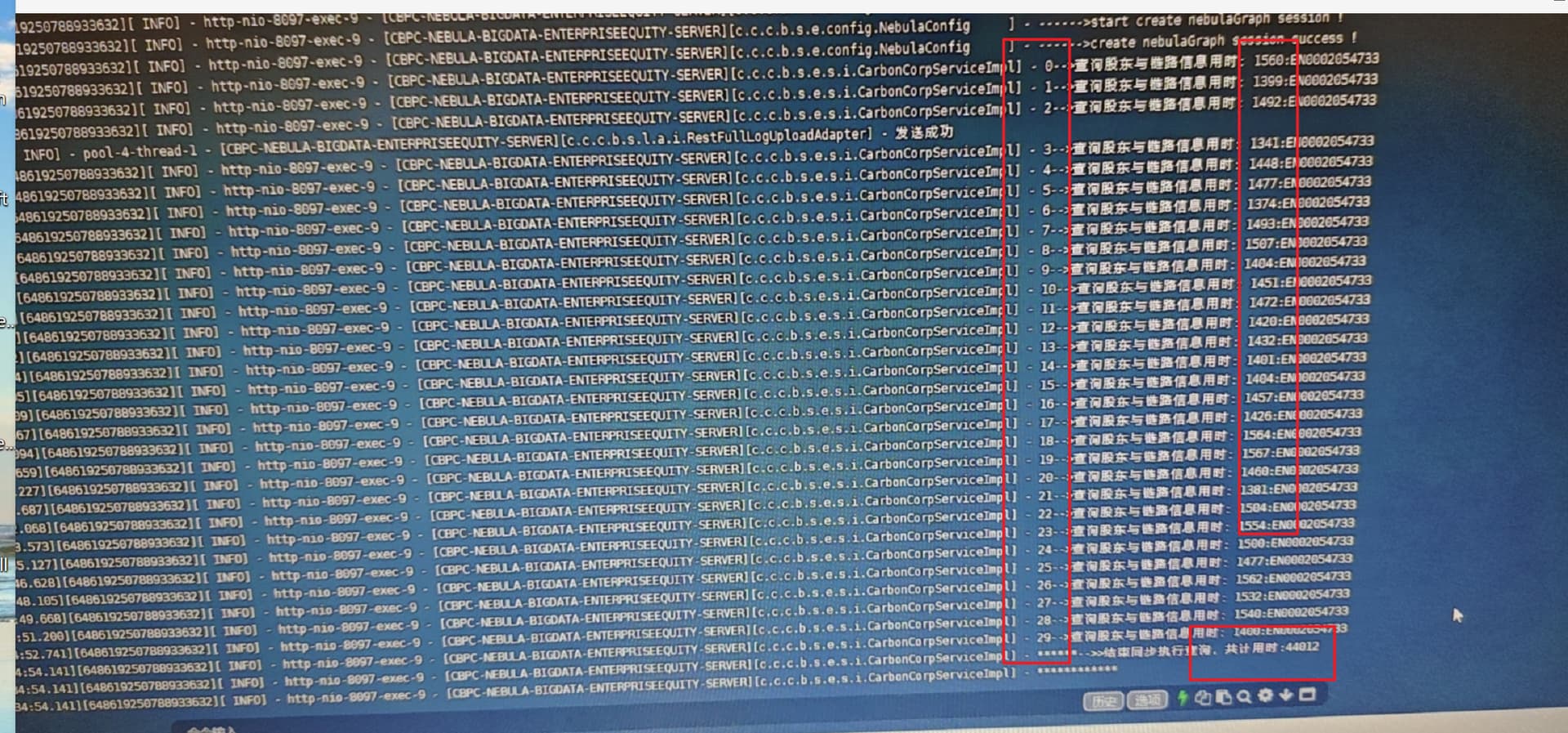
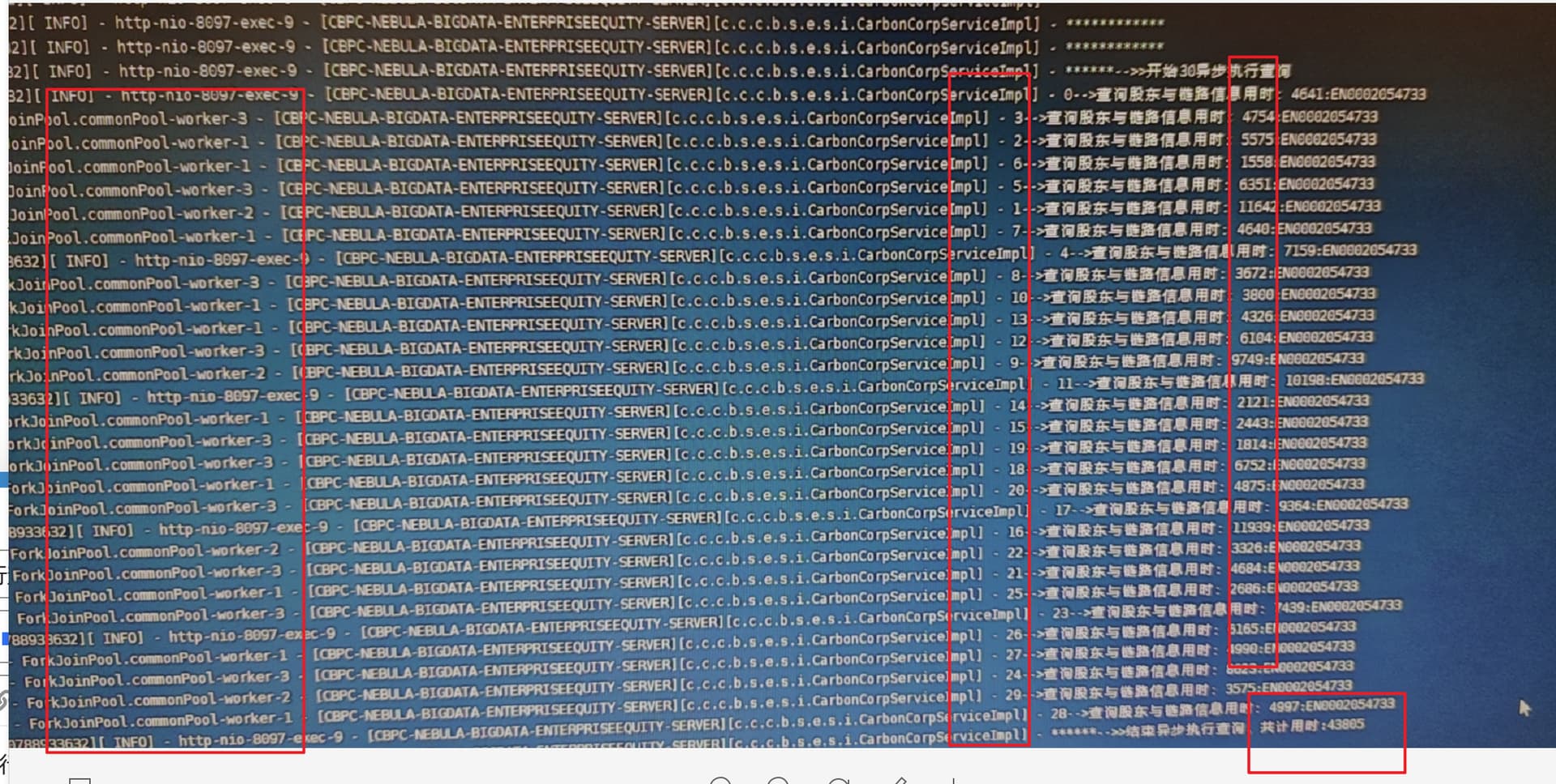
1.单线程执行差不多一秒多。
2.而并发执行时间一下上去了。
但是最终的总时间都差不多44s左右
- 相关的 meta / storage / graph info 日志信息(尽量使用文本形式方便检索)
代码 / 终端输出 / 日志…
这个是做的测试:5次轮询查询:go查询和find路径查询
steam
2
你的关键性代码脱敏下文本贴一下吧。信息不是很清晰。还有,你用的是 java 客户端?
问题是现在同步请求和异步并发请求,总时间差不多。按理说异步的会更快一点。但从测试来看并发执行每次的请求更大了,类似是处在等待中。。这个和nebula-graph.conf配置有关系吗?
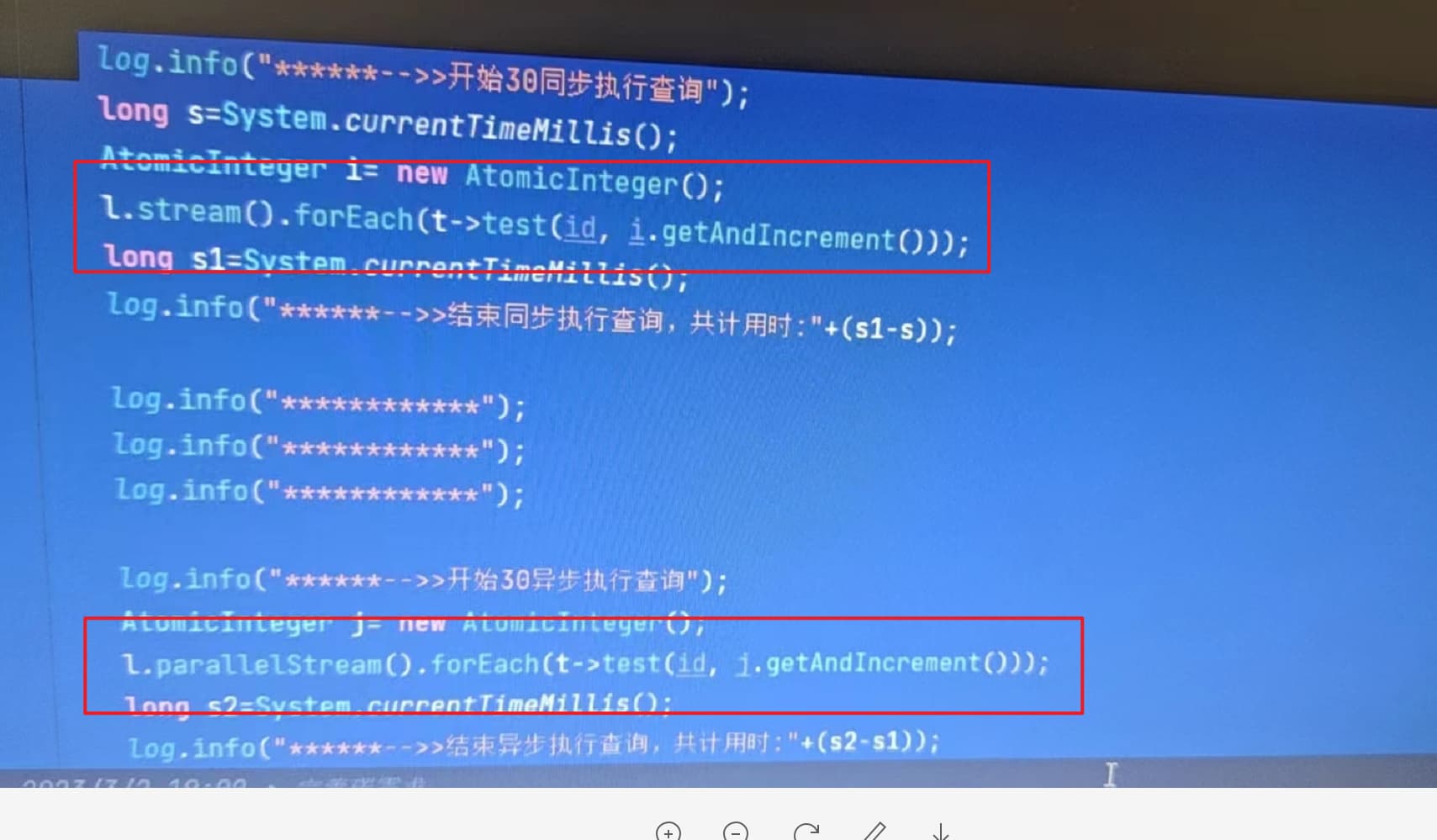
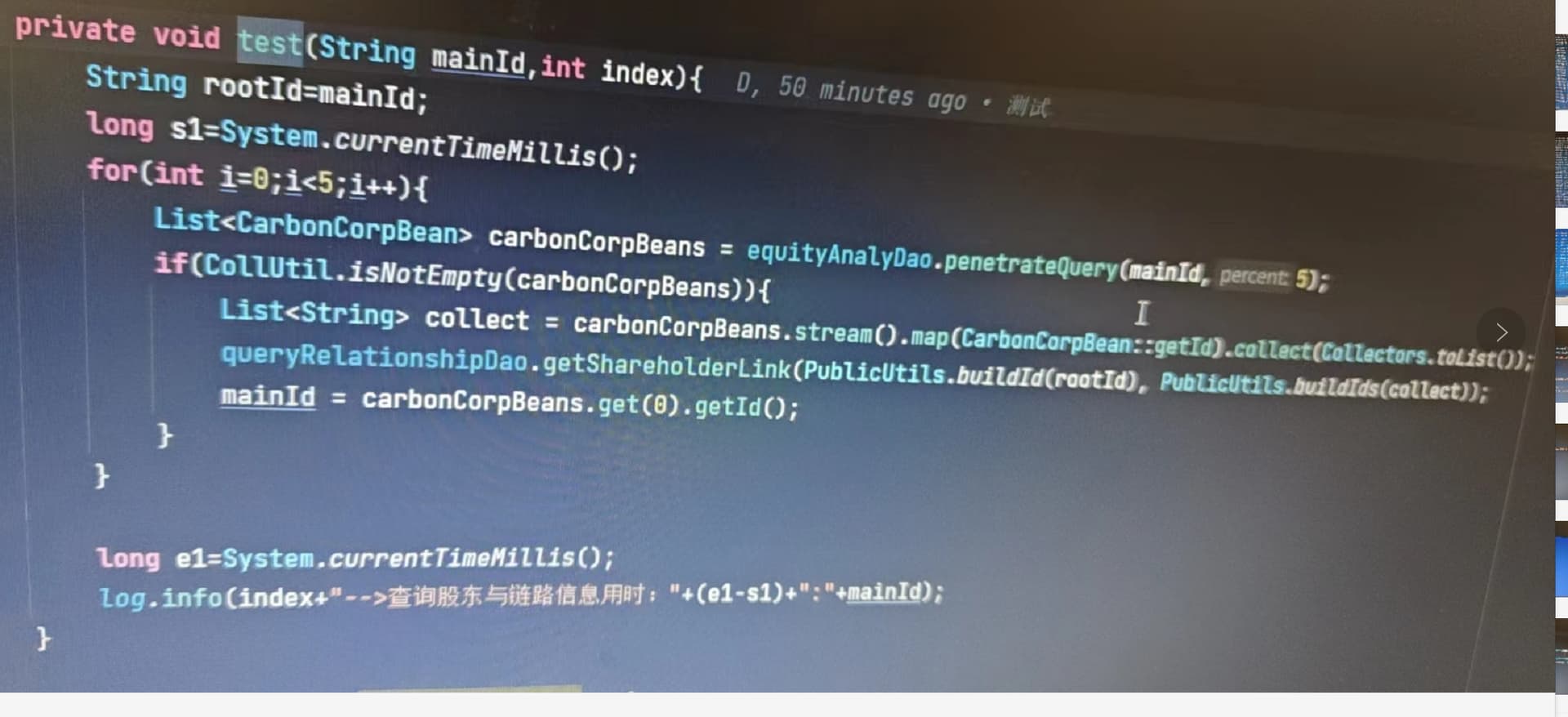
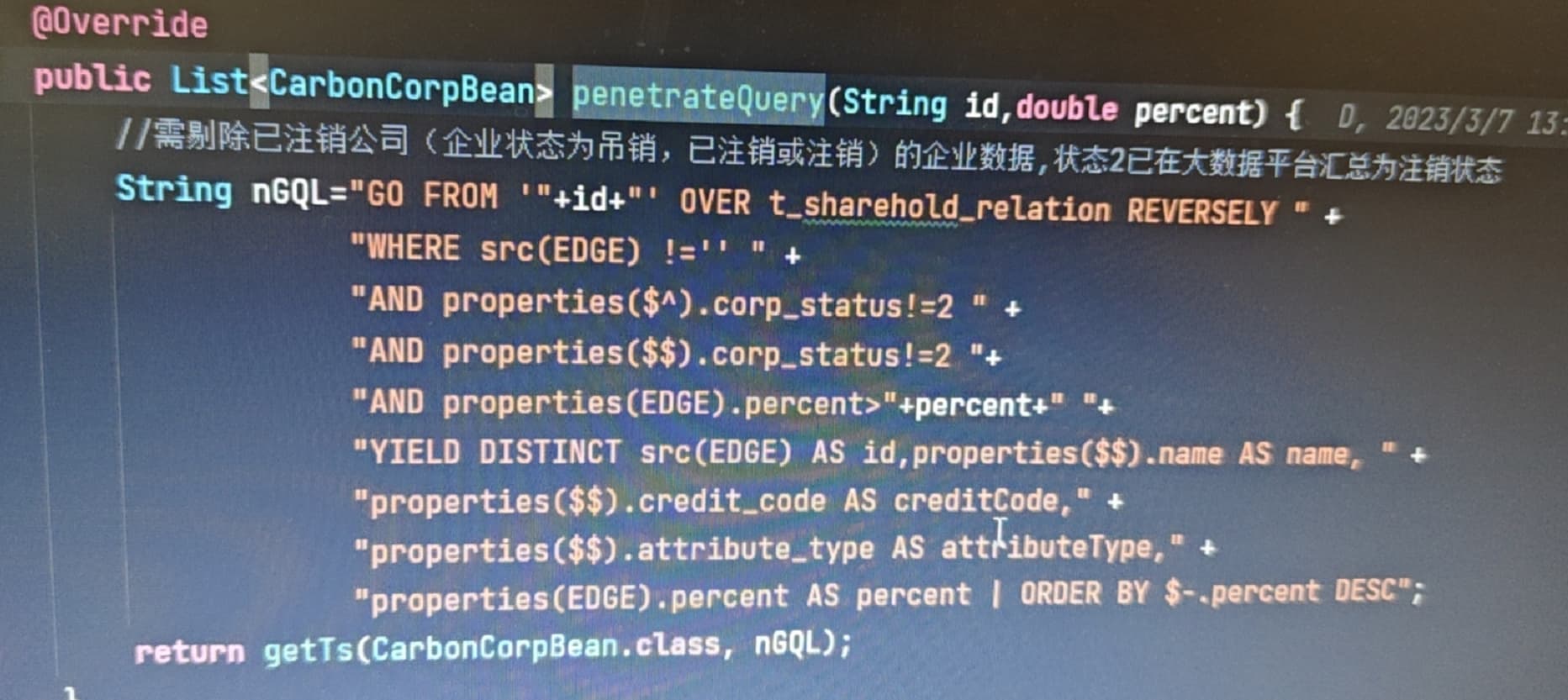
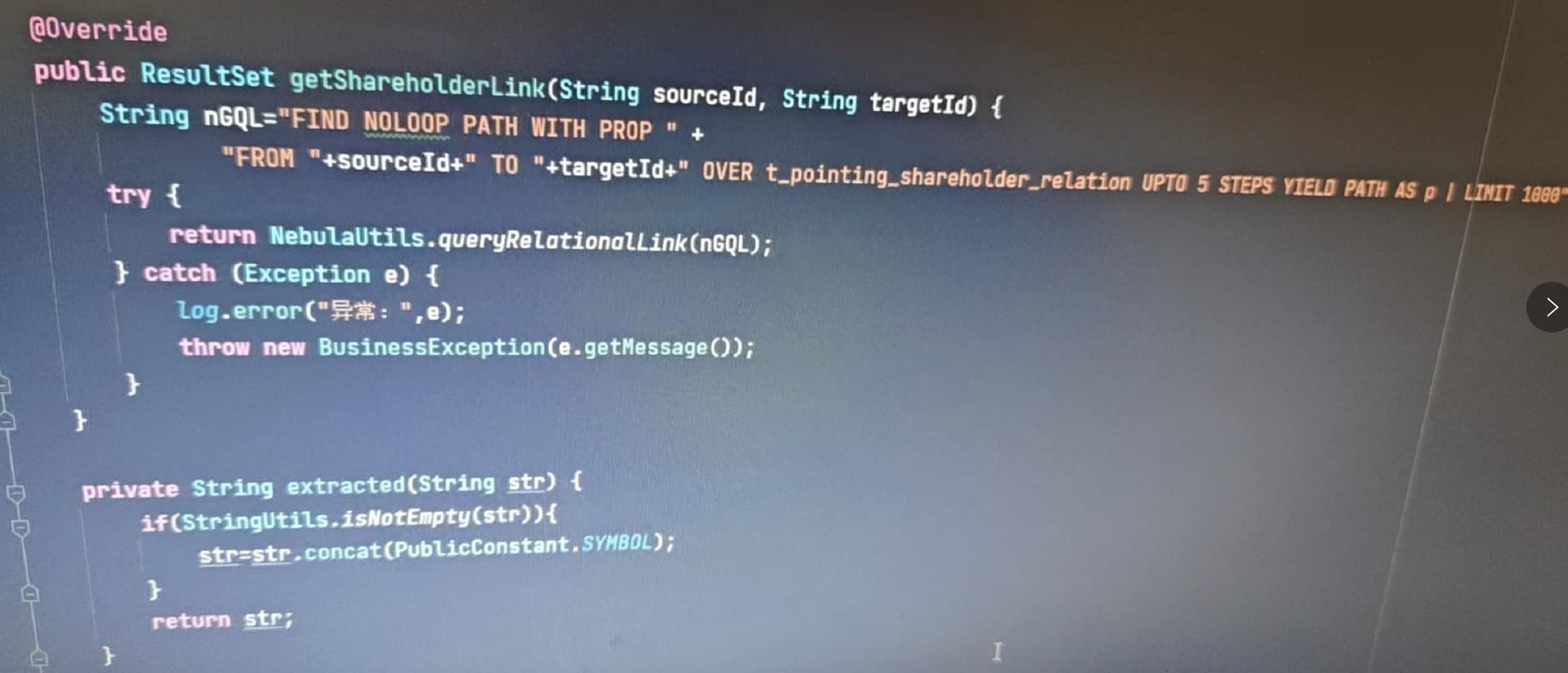
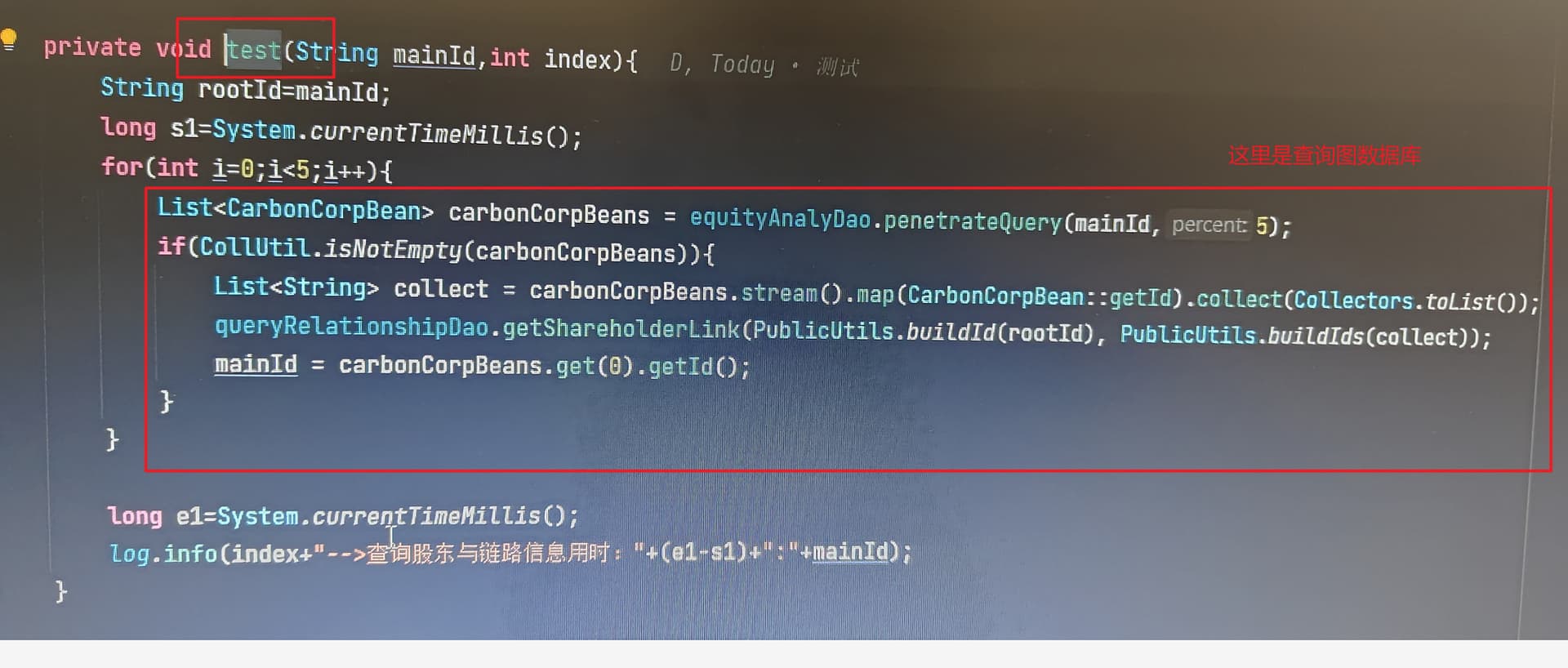
代码在公司的内网里面,我这里拿不出来。就是写了一个查询图数据库的test方法。串行调用和并行调用,
steam
6
把你 parallelStream 怎么 work 的,session 怎么用的说清楚下。
parallelStream是根据应用的CPU随机分配的线程。session我们是采用单例的模式,在系统启动后自己生成的一个session单例
Aiee
8
一个session只能同时被一个线程使用 论坛有很多例子了
哦哦感谢您,我也刚在尝试测试session单例的问题。麻烦老师帮忙发个链接看看,想参考下在系统初始化的时候如何创建session池子,后面并发时候可以从池子中随机拿session。
dengqz
10
系统初始化的时候想创建多个session,放在一个list中。后面并发查询时随机从list拿session,这个方式是否可行呢。有参的方法吗,谢谢
方法可行,我们实践中就有用到并发查询。高版本的nebula-java中已经有了线程池,可以直接使用。
1 个赞
system
关闭
12
此话题已在最后回复的 30 天后被自动关闭。不再允许新回复。