nebula graph版本:3.2.1
===========================
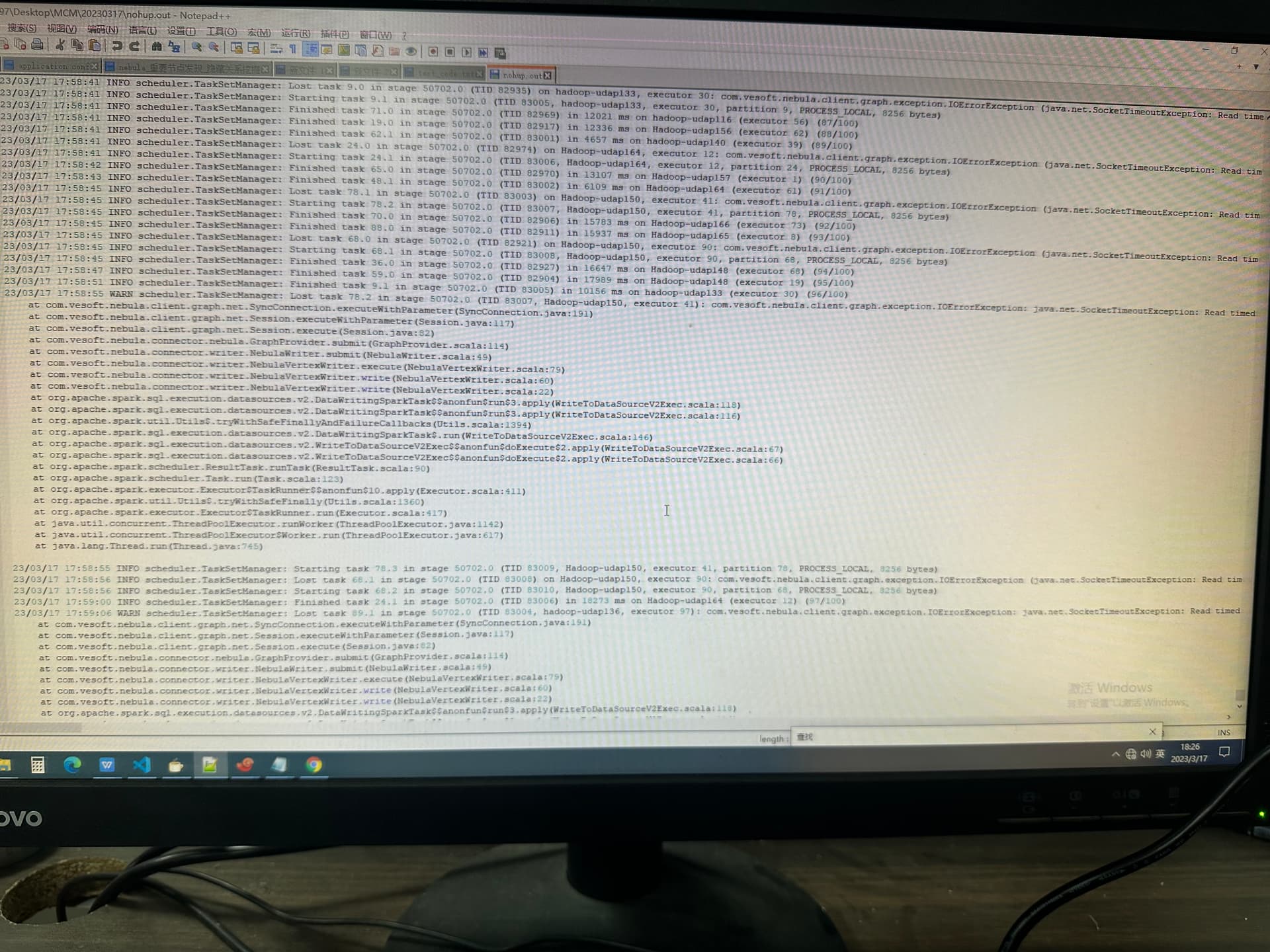
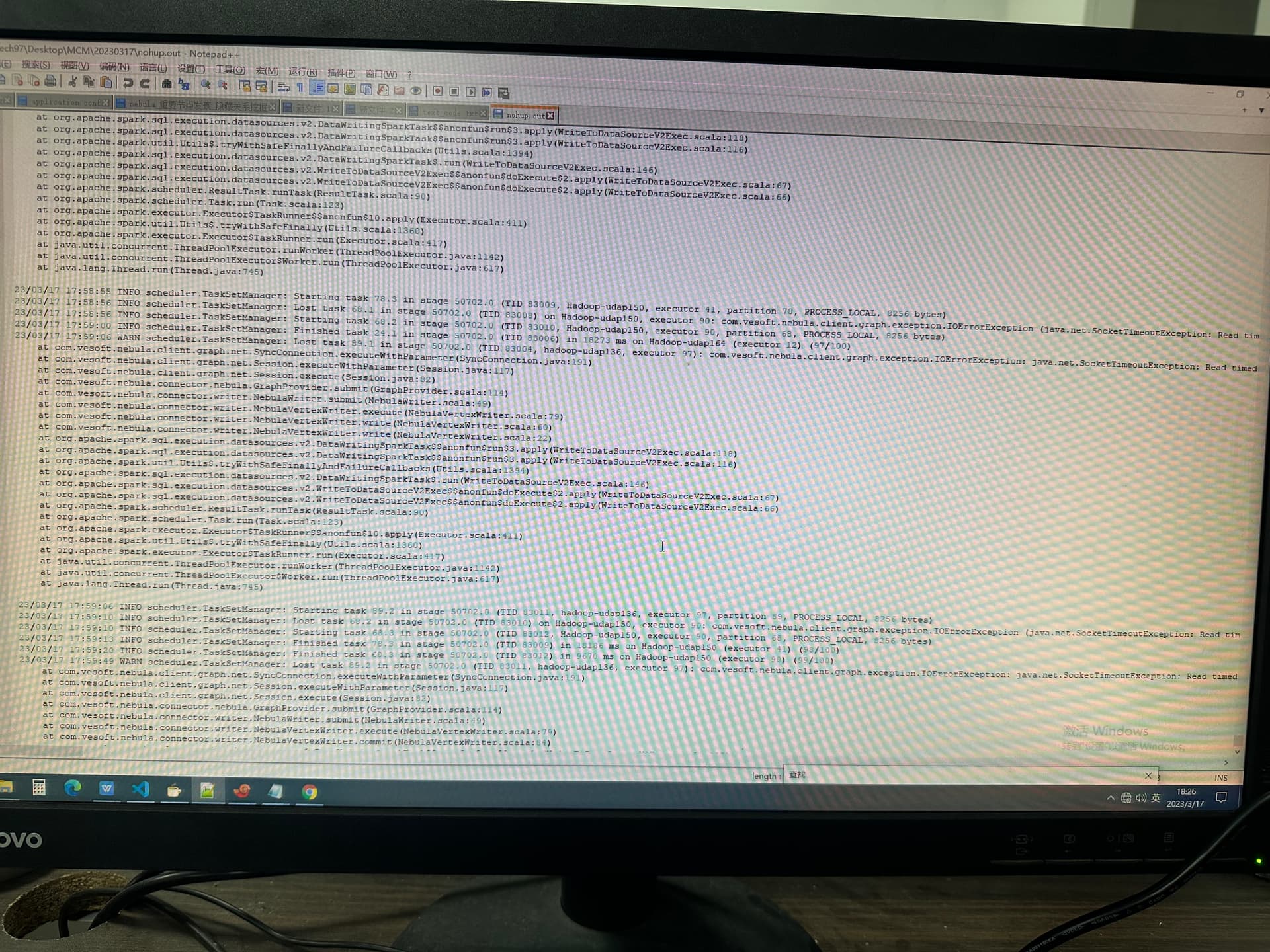
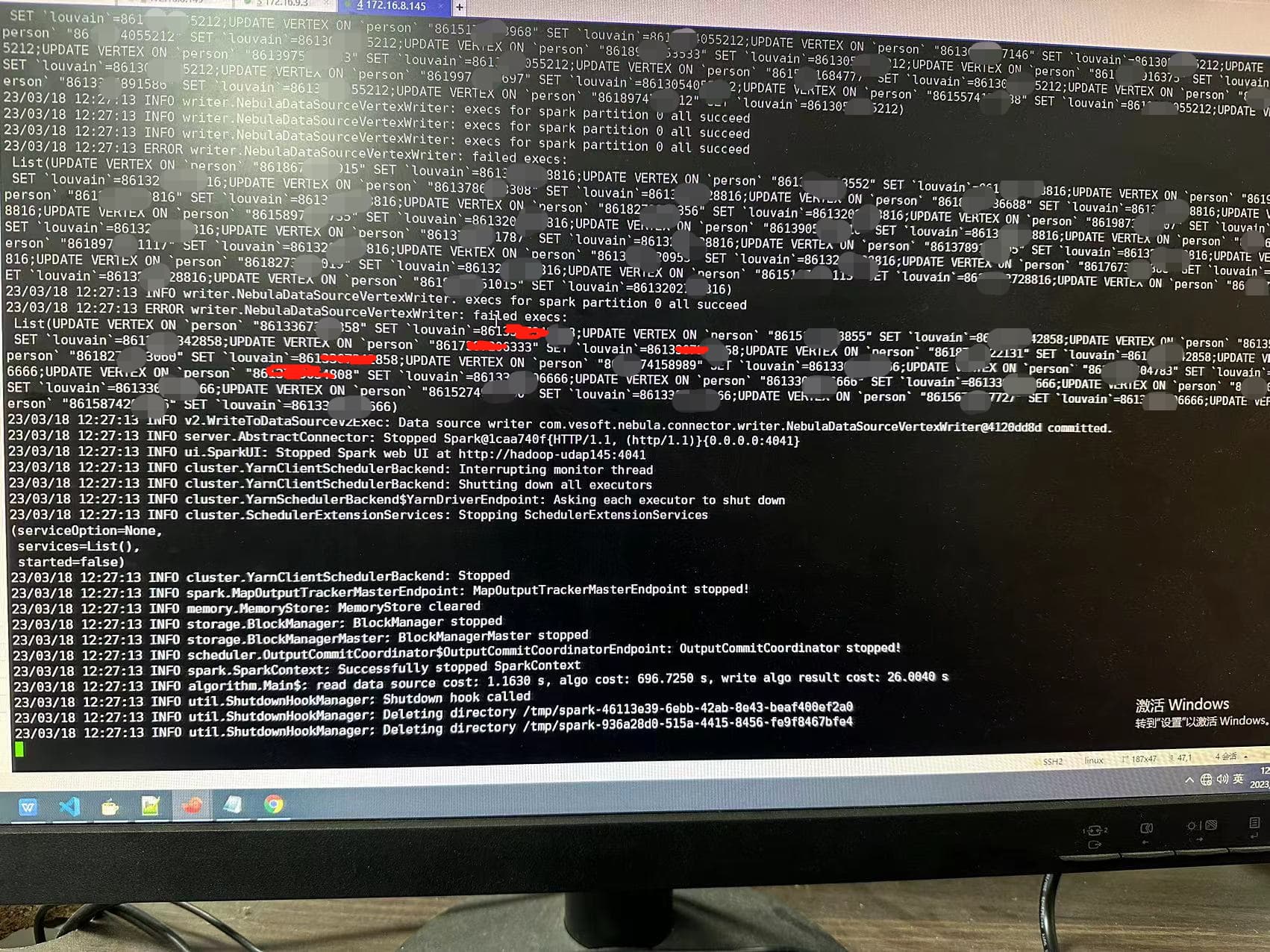
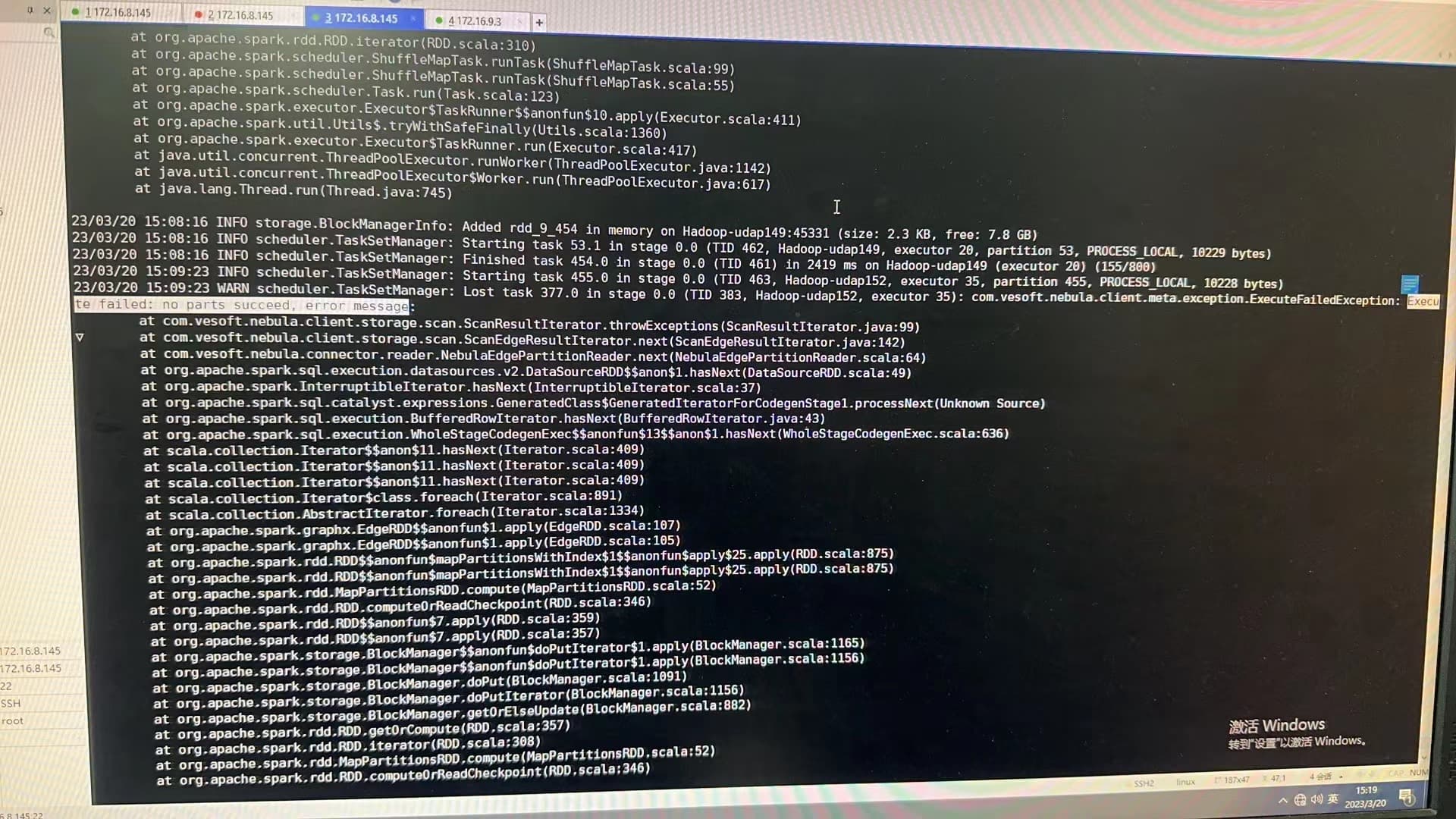
在跑louvain社区划分时,日志中先是出现WARN yarn.Client:Neither spark.yarn.jars nor spark.yarn.archive is set, falling back to uploading libraries under SPARK_HOMEWARN scheduler.TaskSetManager: Lost task 97.0 in stage 50702.0 (TID 82998, Hadoop-udap147, executor 16): com.vesoft.nebula.client.graph.exception.IOErrorException: java.net.SocketTimeoutException: Read timed out
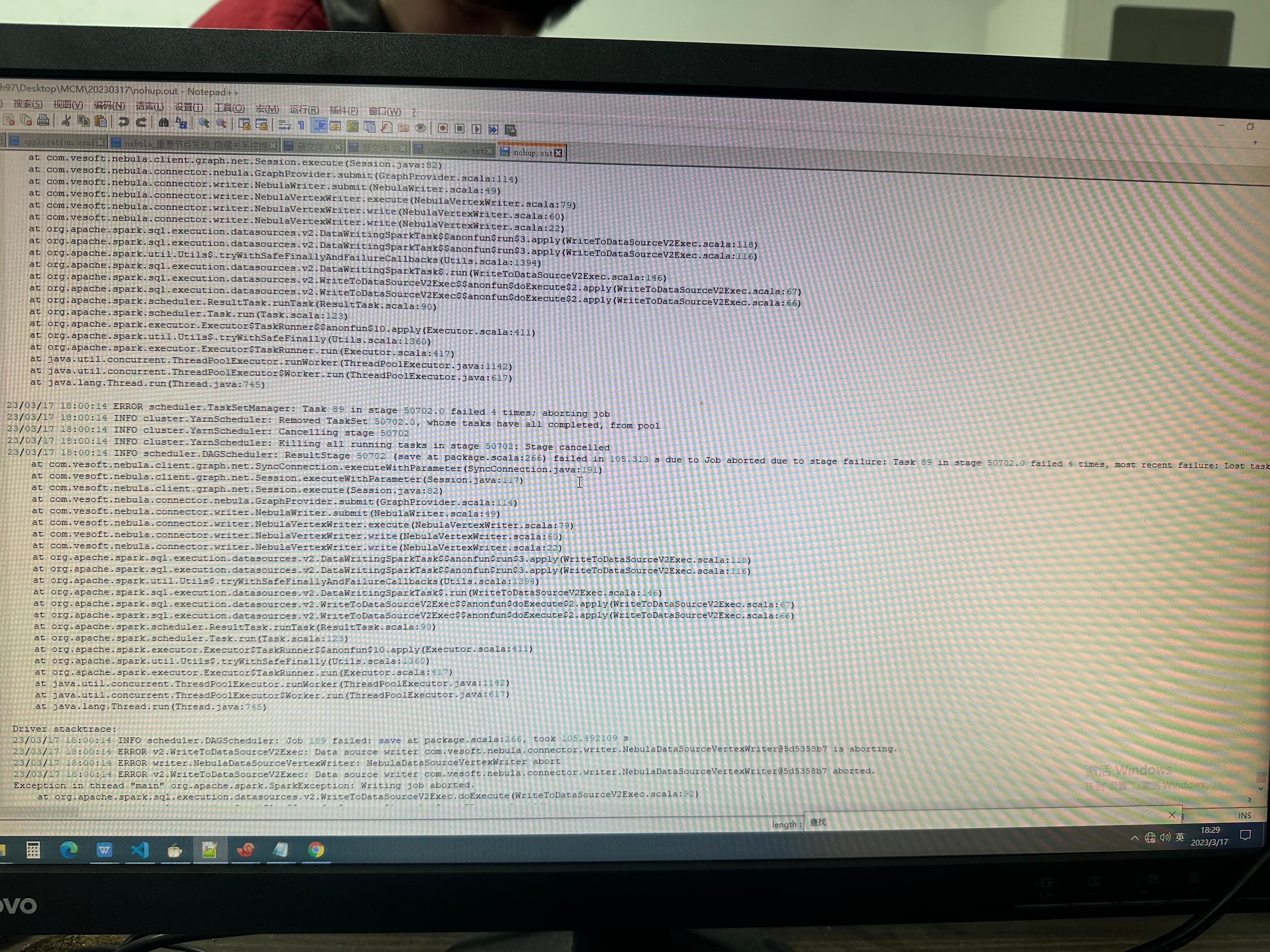
ERROR scheduler.TaskSetManager: Task 89 in stage 50702.0 failed 4 times; aboreding job
再然后:
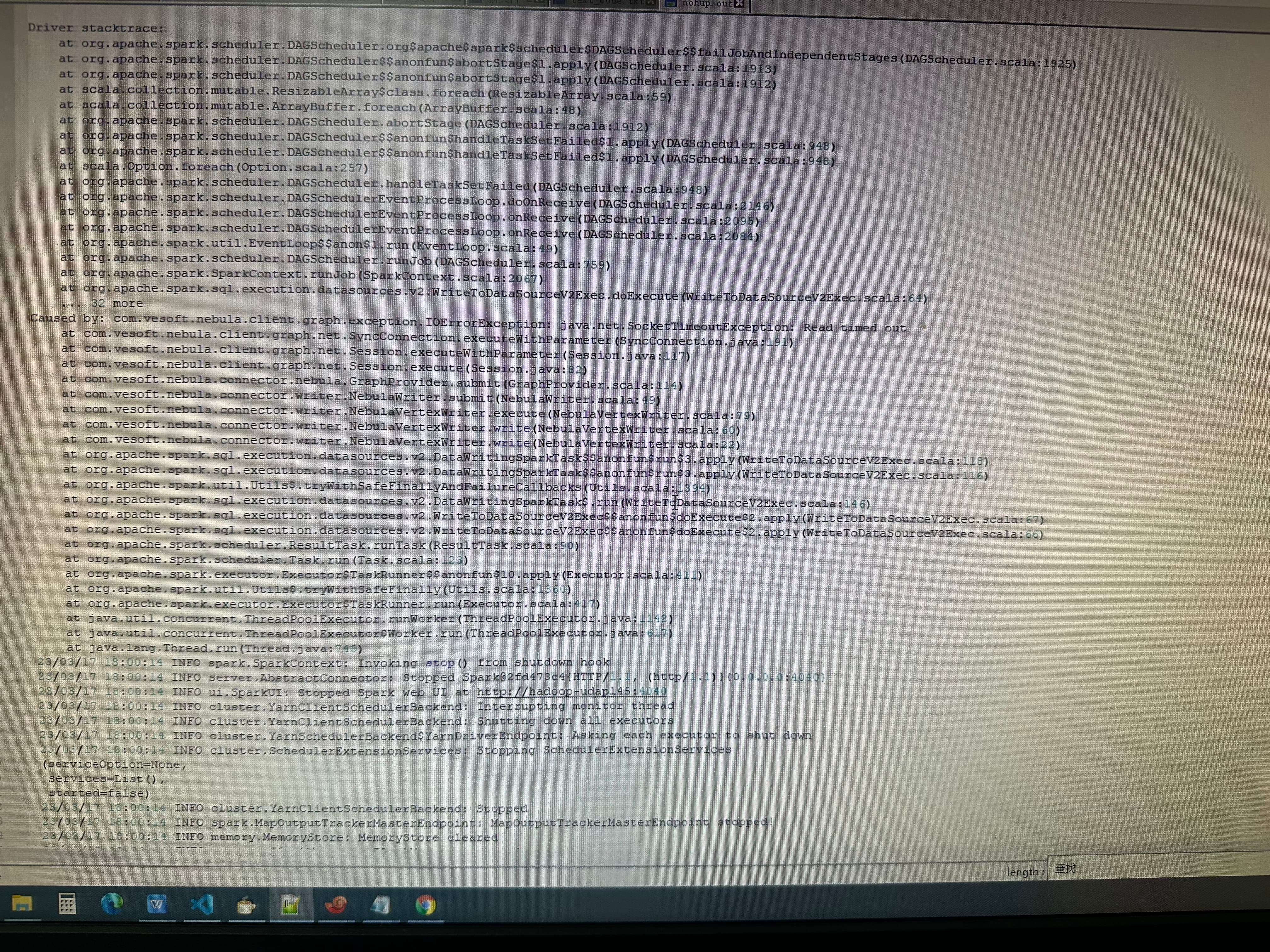
ERROR v2.WriteToDataSourceV2Exec: Data source writer com.vesoft.nebula.connector.writer.NebulaDataSourceVertexWriter@5d5358b7 aborted.
接着是:
Writing job aborted
warn和error的日志照片如下:
我不确定是不是由于并发太多导致的,我提交submit的资源配置是如下:
--executor-memory 10G --num-executors 100 --executor-cores 1 --driver-memory 15G
结合之前提过的问题,我目前想到尝试解决的方法如下:
将nebula-storage.conf中的 修改一下:
--rocksdb_db_options={"max_subcompactions":"48","max_background_jobs":"48"}
其中,两个值都为cpu核数的一半。
将结果写入方式由update改为insert,因为之前我遇到过类似问题:数据量大时,update方式就容易造成writing job aborted,而改用insert方式就顺利执行完。但前提需要为每个节点新增一个tag,并增加louvain属性,否则直接insert到原tag,会将点的其它属性消除。
那么给所有节点新增tag时,有没有方便的方法呢?目前我只知道两种方式:一是insert vertex,如INSERT VERTEX t2 (name, age) VALUES "13":("n3", 12), "14":("n4", 8); ,但这样我需要将所有VID都写在values后面,不太现实。第二种就是用importer工具,在importer.config文件中配置好节点csv数据源,并指定tag,这样又需要重新导入下数据。还有其他方式新增tag吗?
问题有点笨拙,感谢各位老师解答
wey
2023 年3 月 18 日 01:12
3
cc @nicole 老师,我昨天跑 louvain 也发现会停不下来(篮球数据集),还没去研究咋回事儿。
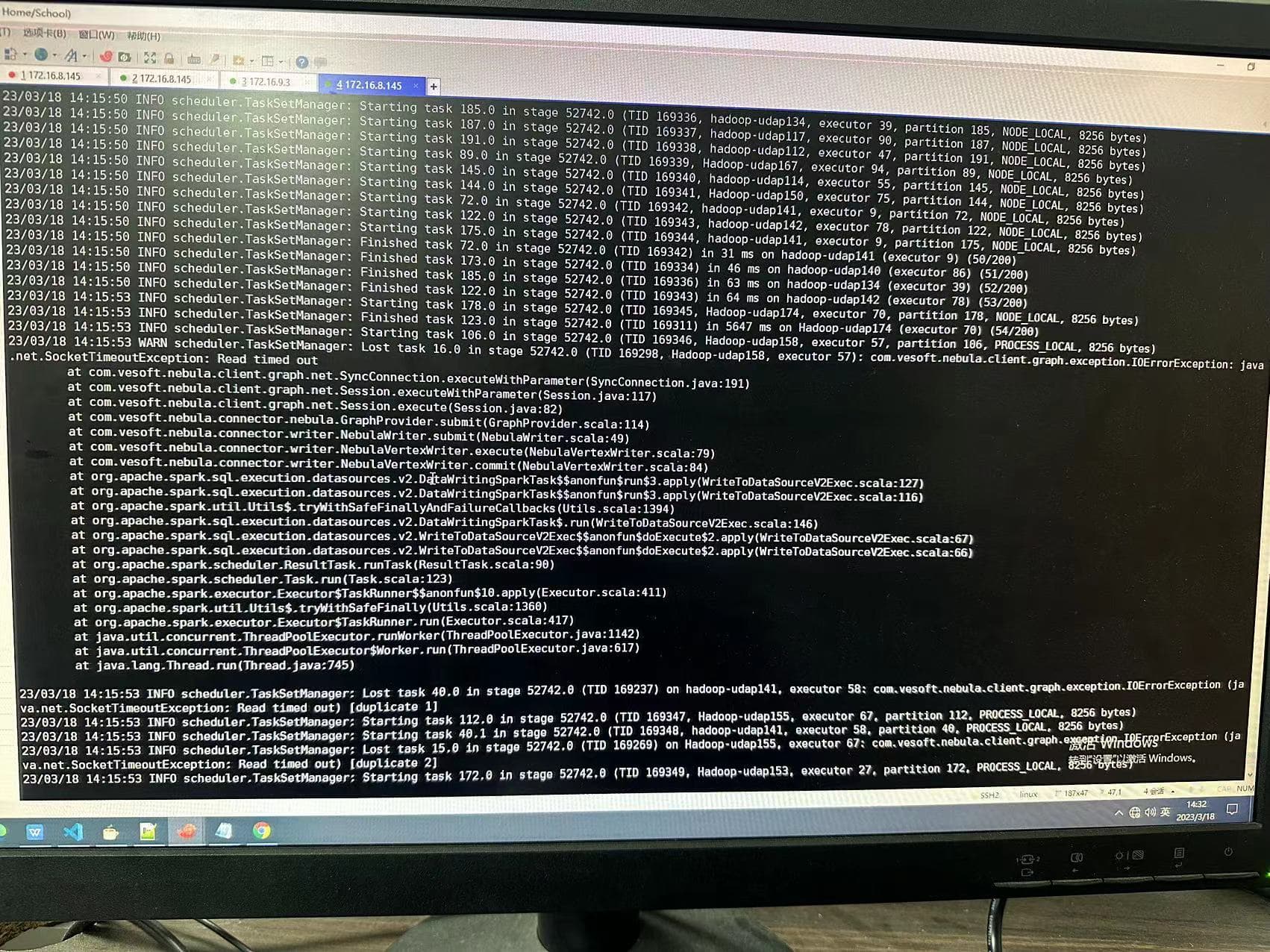
是的,我也发现最新的算法包跑的时间比较久,而且总是卡在某个地方(如:190/200),我查yarn任务看到它确实还在跑,当我加大资源时,没有卡住,但是出现了上面的问题。
我刚才又跑了两遍,发现如果在submit任务时设置num-executors 100,就不会卡住不动,日志刷新很快,而设置num-executors 60则会在运行时卡很久很久。
这次,我将资源设置为如下:
--executor-memory 5G --num-executors 100 --executor-cores 1 --driver-memory 30G
数据集中,边有228152,节点有120648。
11分钟跑完,但是出现了之前的问题,一个也没写进去:
我确定这些节点是在图空间中都存在的,也有louvain属性(int32),图空间的tag只有person一种。
这是之前发生一样问题的帖子:
这是指在算法执行的子图中,没有该节点吗?
application.conf文件中指定的关系是LIKES,然后写入的tag是Post,我理解算法流程应该是:取出LIKES的子图,对子图中所有节点做社区划分,然后tag为Post的结果写入进去。
ldbc数据集的likes关系两侧tag有person/Post/comment:
[image]
也就是将涉及likes关系的person/po…
也是由于update出现这个问题,我才转而采用insert方式将社区划分结果写入tag中,这样就得给每个节点新增一个tag。
再更新一下:
我设置的louvain属性是int32,要插入的编号一般都是86 + 11位手机号,我在想是不是int32存不下13位数字,于是将louvain属性改位string。再次运行。
结果写入方式仍然采用update,资源依旧是:
--executor-memory 5G --num-executors 100 --executor-cores 1 --driver-memory 30G
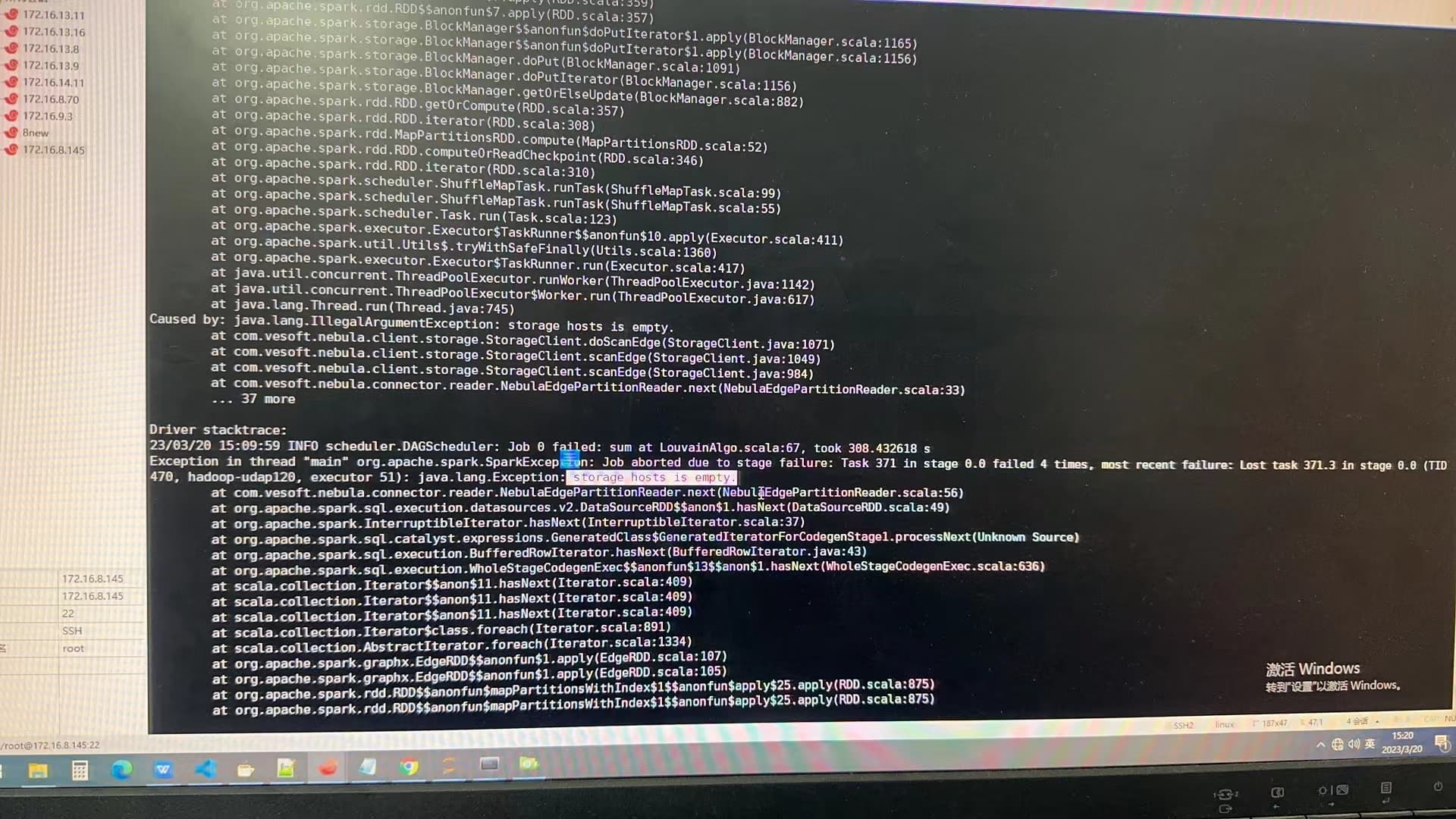
结果不再出现上面的ERROR writer.NebulaDataSourceVertexWriter: failed execs:List(UPDATE VERTEX ON prson"“8618673XXX15”SET louvain'8613XXX72X816
而是下面的报错:
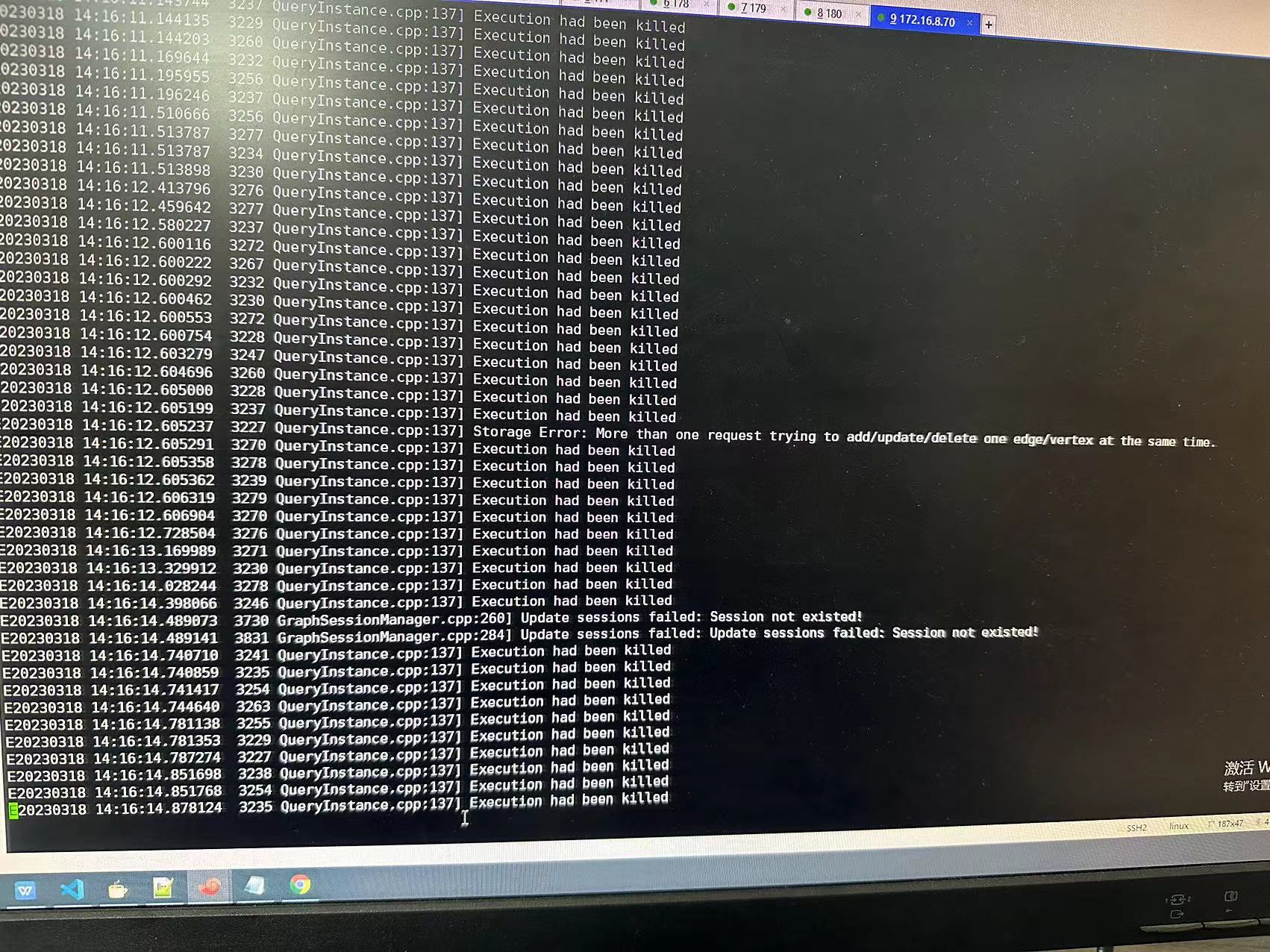
查看nebula-storage.error日志:
上面写
Storage Error: More than one request trying to add/update/delete one edge/vertex at the same time
貌似和帖子最开始报错一样,这是并发太多导致的嘛?
再次更新下
将结果写入方式由update改为insert,一开始也是运行着不动了,我又结束任务重新运行,然后10分钟跑完,但是同样出现上面的read timed out,然后一直duplicate(1),duplicate(2)… 随后writing job aborted。但最后查图库写进去8W数据,即8W节点的louvain字段是有值的。
最后总结下我的问题:
跑louvain算法时,算法结果update或Insert节点中,都会随机出现卡住(日志停住,任务还在运行),可能是数据中有超级节点?或者yarn资源有问题?不清楚。。。但也会出现10min跑完,然后报下面错。
如果不卡住,顺利跑完,则会出现read timed out和writing job aborted报错,详细日志见上述图片(可能有点乱,抱歉)。update方式时,报错后louvain字段都没写进去;insert方式时,报错后部分写进去。我猜。。还是并发多导致的。。Storage Error: More than one request trying to add/update/delete one edge/vertex at the same time 和 vertex conflict 11:16:14:86136XXXXXXXX
各位老师,麻烦帮忙看下这个问题怎么解决
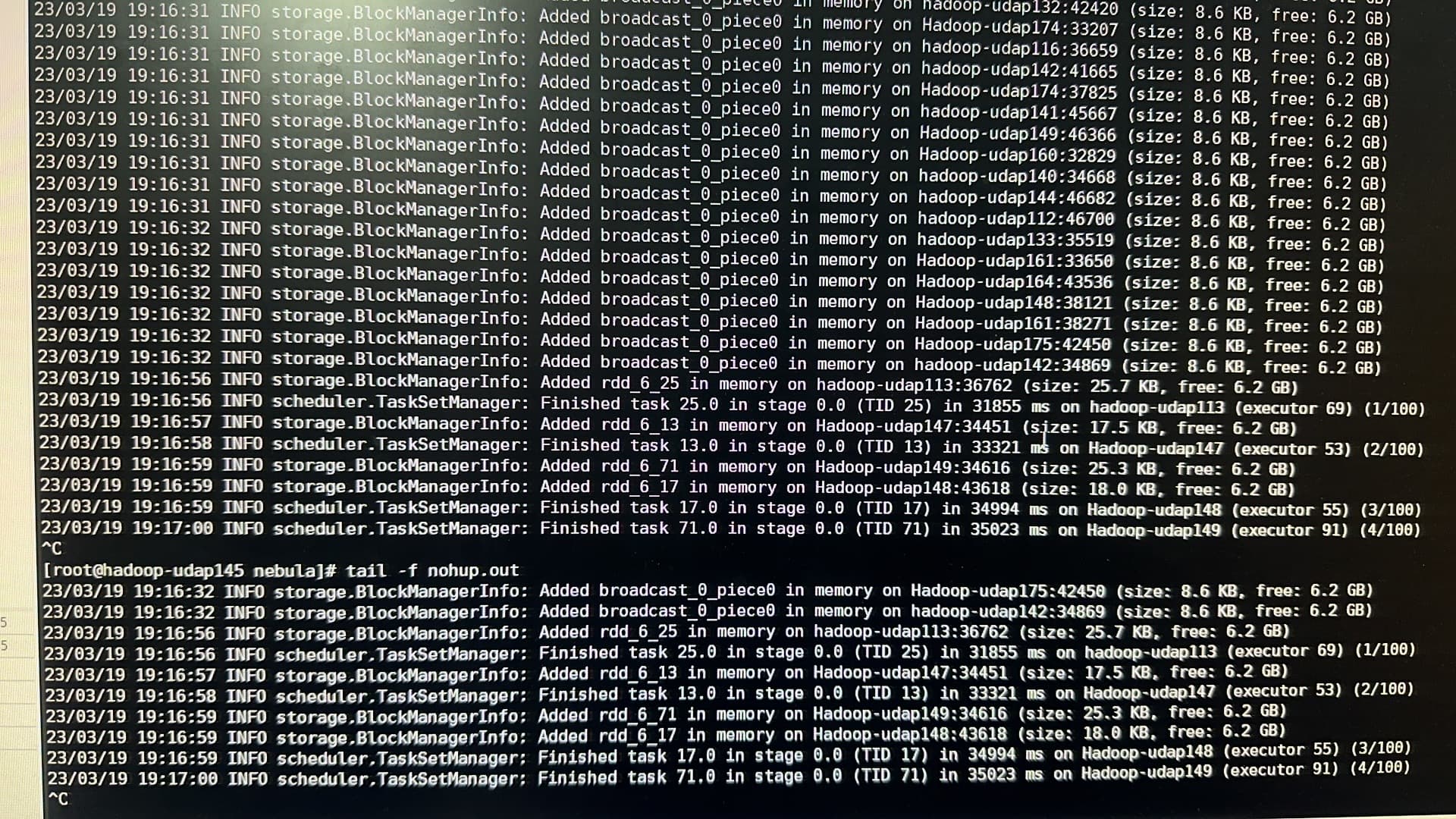
这个问题好难搞,刚才跑了一下10分钟跑完,再跑就一直这样,偶尔才会跑通。这是所谓的数据倾斜吗?一个执行器分配了大的数据量而导致卡死吗?下面是卡到(4/100)不动了。
配置文件中有一项配置是nebula.partitionNumber,可以修改该参数。 这个参数对应的文档说明有误,不是指NebulaSpace的partition数,是指spark的分区数。
我需要更改配置文件中的分区数吗?目前我的图空间分区是400,算法包配置文件中partitionNumber是100
user82
2023 年3 月 20 日 03:34
11
配置文件中的partitionNumber由100改为800后,还是卡住,应该怎么改呢?
user82
2023 年3 月 20 日 07:25
13
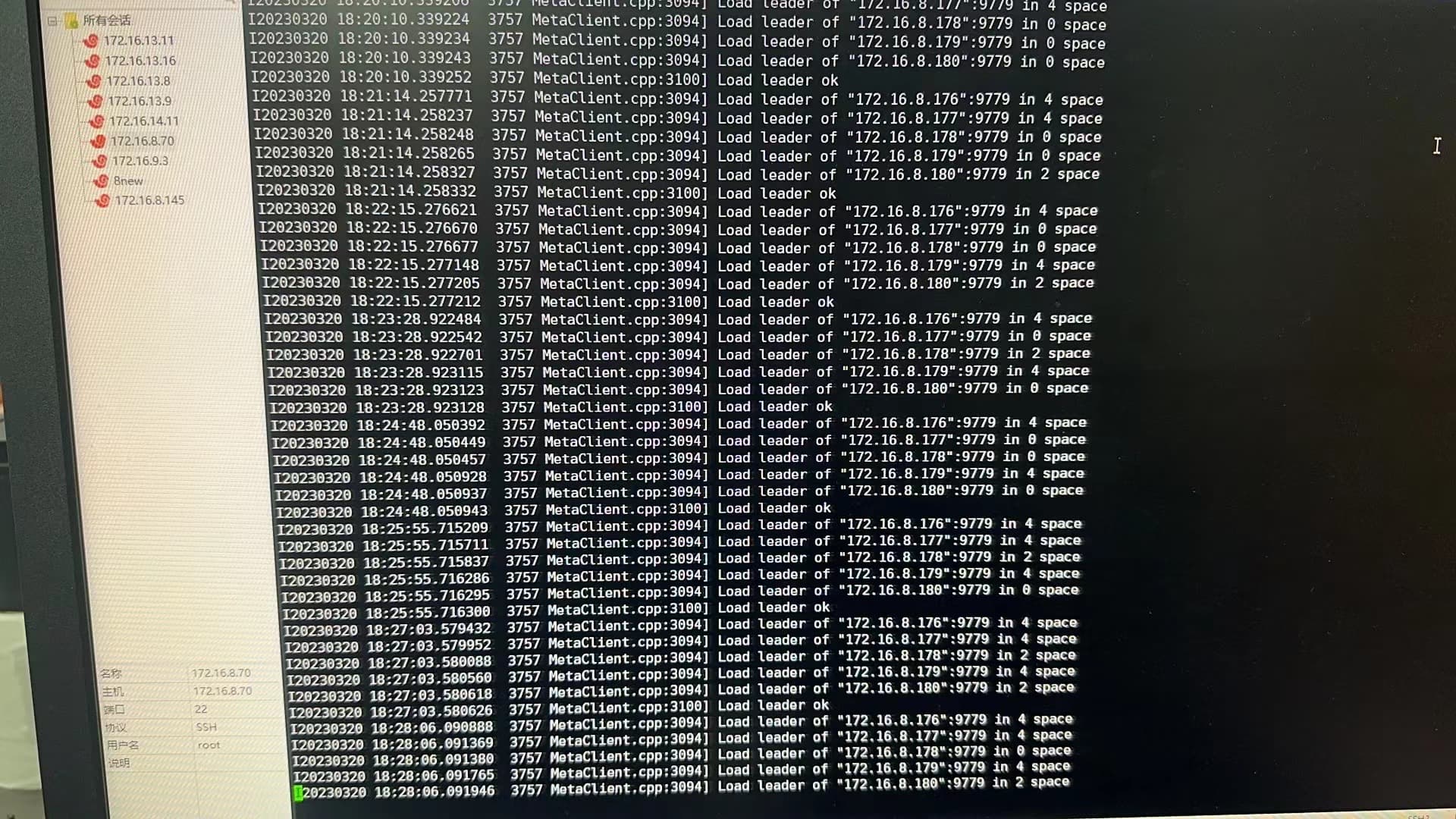
汤圆姐,我在submit的时候增加了--conf spark.sql.shuffle.partitions=400,(总结就是图空间分区为400,算法包application文件中partitionNum也是400,spark-submit中也是400)。此外,louvain算法encodeId设置为True(图中VID是13位数字,但是是string类型)。no parts succeed,error message,然后报错storage hosts is empty。
我show hosts storage是有ip的:
记得上次我的storage服务起来要好久,有时起不来,清蒸让我add hosts ,我还没添加,因为我看上图中可以查出来。是这个问题吗?
user82
2023 年3 月 20 日 10:51
14
补充一下在studio中show hosts的结果:
这是先后两次点击运行的结果。我有疑问是:为什么status有online也有offline呢?前后两次查询是变动的。还有就是为什么每个distribution中图空间个数不一样呢?这和我上面的我问题是不是有联系呢?实验室环境的
show hosts中的status一直是online状态,且每个distribution中的图空间是一样的。
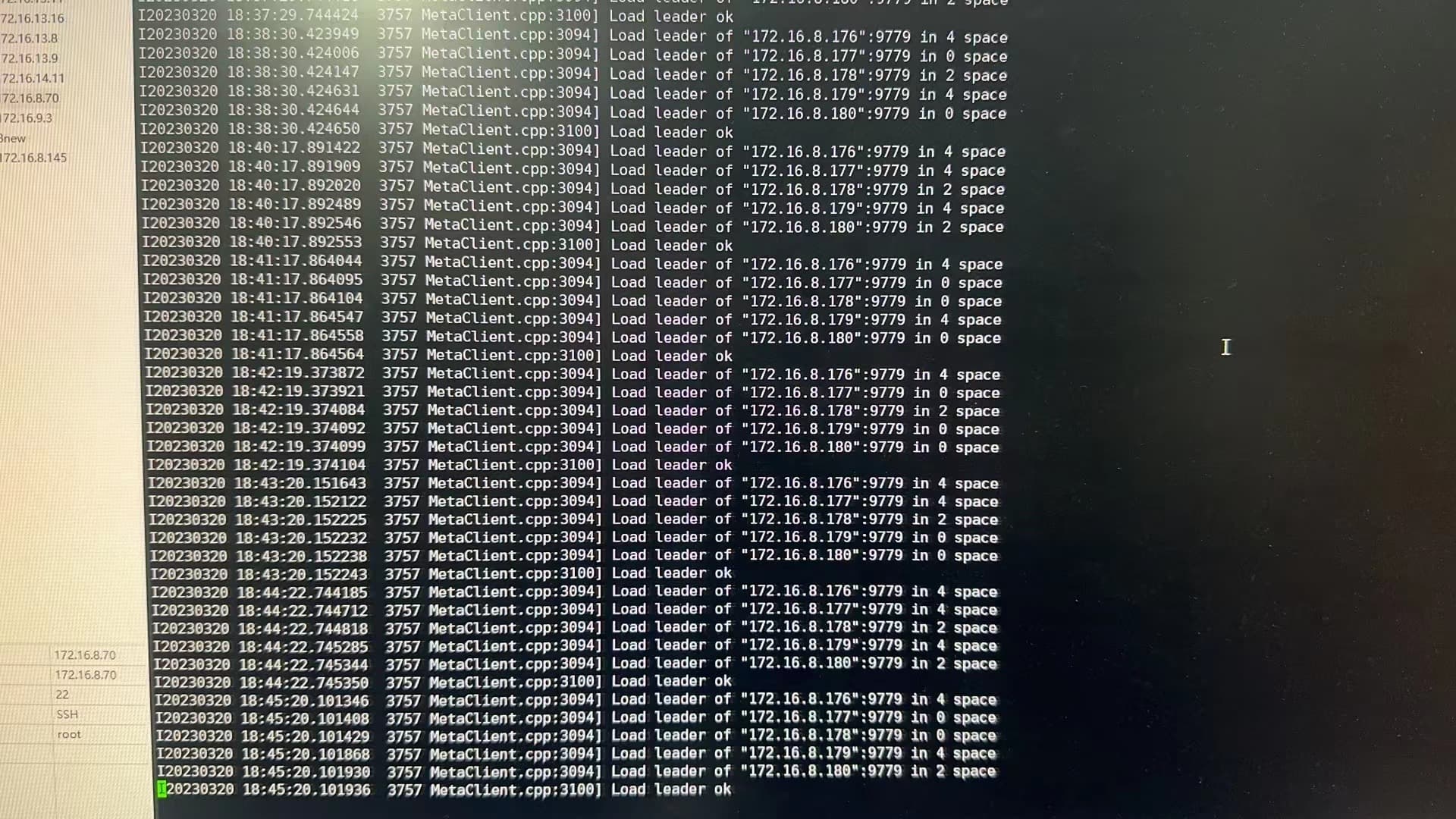
我看了176上的nebula-storaged.graph-node176.root.log.INFO.20230317-200123.3273日志:
下面是176上的nebula-storaged.INFO的日志:
system
2023 年4 月 19 日 10:52
15
此话题已在最后回复的 30 天后被自动关闭。不再允许新回复。