本文整理自中国移动算法工程师——汪海涛在 NebulaGraph 2022 年度用户大会上的分享,现场视频见 B 站:https://www.bilibili.com/video/BV1Ae4y127a8/
各位朋友上午好,我是来自中国移动的算法工程师汪海涛。接下来我主要聊一聊图数据库在中国移动,特别是金融风控场景的落地应用。
为什么中国移动要建设图平台?
全国 9 亿用户,每天产生大量数据
中国移动有非常多的数据,全国的用户每天都会产生海量的数据。如何从这么大数据量里面挖掘出有用的信息,然后用到金融风控场景?这就是我们需要做的事情。
之前,我们是以手机号为维度去提取特征,然后去做一些模型或规则判断一个手机号是否是有违约风险。但仅仅基于手机号很难综合去考虑风险情况,因此我们就想采用图计算技术去综合看一个手机号以及周围的其他手机号的信息,然后共同评判它的风险。
最开始是基于消费金融的场景,从比如说像蚂蚁金服、微信以及京东白条这样一些产品切入,通过用户通话数据、短信数据、设备等多维度的一些信息,去判断用户风险。但中国移动数据量这么大,不管我们要做什么,最大的诉求就是需要有一个非常高性能的平台去支撑数据分析。
为什么选择 NebulaGraph 图数据库?
JanusGraph vs TigerGraph vs NebulaGraph
我们最早是采用了 JanusGraph 加上 Spark 去建设我们平台,但是通过一些测试,我们发现 JanusGraph 的查询性能以及导入性能都比较一般,然后 GraphX 的话,它的计算性能其实也比较一般,特别是它需要的内存量特别大,因此我们后来又开始去调研了市场上很多的图产品,并且对一些图产品做了测试,包括国外的产品,像 TigerGraph 之类的等等,但是因为一些特殊原因,中国移动是在美国商务部的实体清单上,所以很多外国的产品我们是没法去采购和使用的。
因此最后,我们是选择国内的几家厂商进行了一些测试和比较,最后选择了以 NebulaGraph 作为图数据库,然后以 Plato 作为图计算引擎这样一个整体的架构。
中国移动是如何搭建图平台的?
图平台建设概况
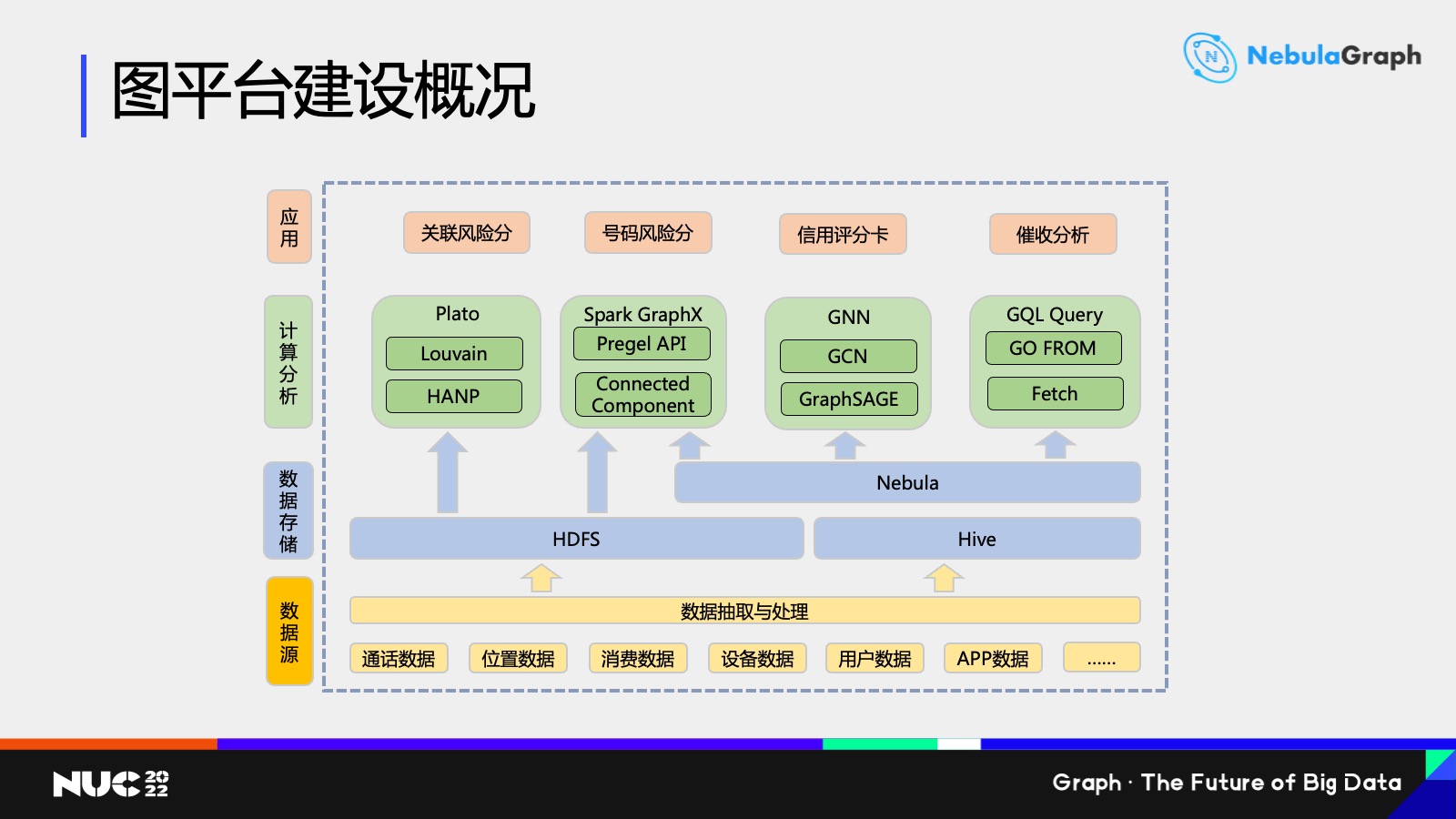
我们整体的架构大概是这样的——
最底层是我们的数据源,中国移动建设有一个全国大数据中心,主要包括通话数据、位置数据、消费数据、设备数据、用户数据和 APP 数据等等,我们每月把这些数据抽取到 HDFS 里面,然后把其中有用的数据抽取到 NebulaGraph 数据库里面,那么这里用的就是 Nebula 的一个导入工具,这是我们图数据存储这一层。
再上一层是计算分析层,这也是我们建模和业务分析人员主要使用的一些框架。首先第一个是 Plato,它是腾讯之前开源的一个图计算引擎,但是据我所知腾讯现在已经不维护这一套引擎了,因此我们也是专门找一些工程师,然后去维护这里面的一套框架,以及修复一些小 bug 之类的。
那么它包含的算法其实很多的,这里我主要是列举了两个社区发现算法:Louvain 算法和 HANP 算法。它里面还包含一个 LPA 算法,因为 LPA 算法的话是 HANP 算法一个简化版,所以这里我没有列出来。
然后里面还有一个我们有可能后面会用到的关于随机游走类的算法,主要是基于随机游走得到一个节点序列,会为我们后面用于图神经网络训练做一个前期数据预处理的工作。
第三个是 GNN,就是图神经网络。图神经网络是最近几年兴起的一个领域,我们现在主要是基于这些模型做一些简单的产品,看看能不能取得比以往的方法更好的一些效果。最后就是基于 NebulaGraph 查询语言,主要就是 GO 语句和 FETCH 语句做一些简单查询。
再上一层的话就是应用层。首先是关联风险分,关联风险分主要是基于配套的社区发现算法来做的。第二个号码风险分和最后一个催收分析主要是基于 Nebula 的查询语句来做的,主要就是查询用户跟一度、二度联系人以及一些违约用户,或是催收专用号码进行一些主动或被动的呼叫。第三个信用评分卡是基于图神经网络来做的,主要是用逻辑回归或者决策树之类的模型,希望通过图神经网络做一些提高。
图数据结构介绍

- 点数据
点数据主要是有四类,第一个是手机号,手机号也是我们最重要的点数据,主要是包括比如这手机号它是属于哪个市的,是否发生过停机等等,还有一些消费信息。第二个是地理位置,主要基于基站。第三个身份证,作为唯一身份证识别,可能也会有年龄或学历之类的标志。最后是设备信息,一般手机会有一个设备值,有对应的型号、设备系统等。
- 边数据
目前边数据的话,一个是用户跟用户的通话数据,第二个是手机号和身份之间的对应关系,第三个是手机号和设备之间对应关系,第四个是手机号跟地理位置之间对应关系,那么这些是我们在图数据库里面保存的一些数据。
图技术在中国移动有哪些应用?
应用1:号码风险分
首先是号码风险分模型,主要用在羊毛党识别这个场景。我们会根据用户的通话流量位置以及手机行为信息去判断一个号码有没有可能是个羊毛党,主要通过四个模块——
第一个是接码模块,我们会跟一些外面数据公司合作,判断一个号码有没有可能是一个接码号码,如果是,我们会认为这个号码是薅羊毛的可能性就很大。
第二个行为异常号码,比如说这个手机号是否当月一次通话都没有,然后是不是每月都基本只有固定的月租这样的消费。这种号码我们认为它可能是一个小号,或者是专门用来去薅羊毛的号码。
第三个是位置异常,比如说这个手机是否一个月下来就是在一个位置从来没有动过,可能只是放在家里偶尔用一下,不会带出去这种。对于这种号码的话,我们认为它的风险也是相对比较大的。
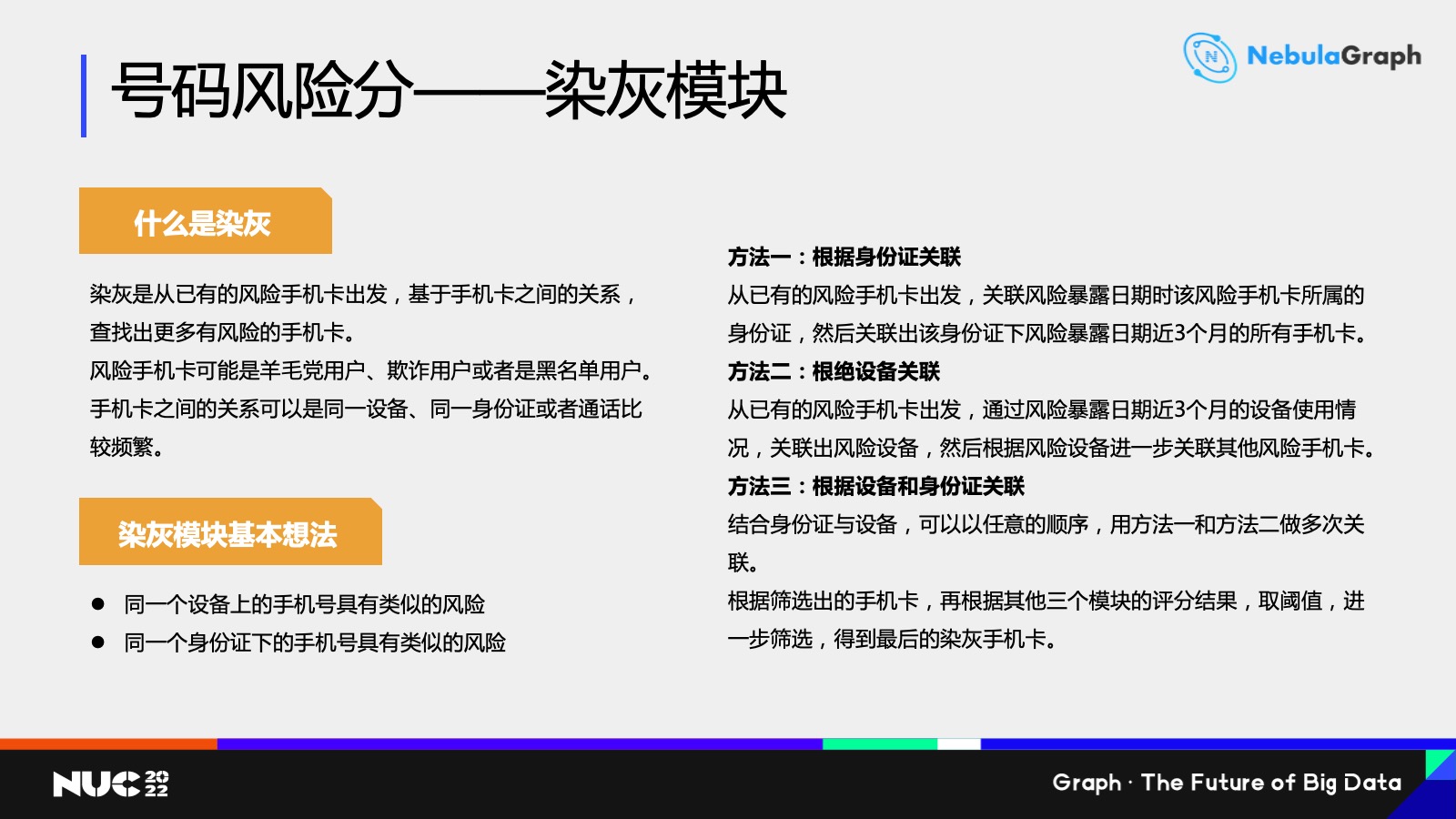
第四个是染灰模块,图技术主要就是用于这个模型。基于前三个模块的结果,我们首先获得了一批已经确定的羊毛党用户,那么我们可不可以发现他的一些共同特征?比如说可能有几个羊毛党(号码)是属于同一个用户的,那么我们是不是可以看看这个用户下面其他手机号是不是也可能是羊毛党?
另外,如果发现有一堆手机号是之前在同一个设备上使用过,我们可能也会认为这个设备上对应的其他手机号也可能会是一些羊毛党。专业的羊毛党会采用卡池这种设备专门去薅羊毛,用图技术就可以快速发现并识别。
应用2 :关联风险分
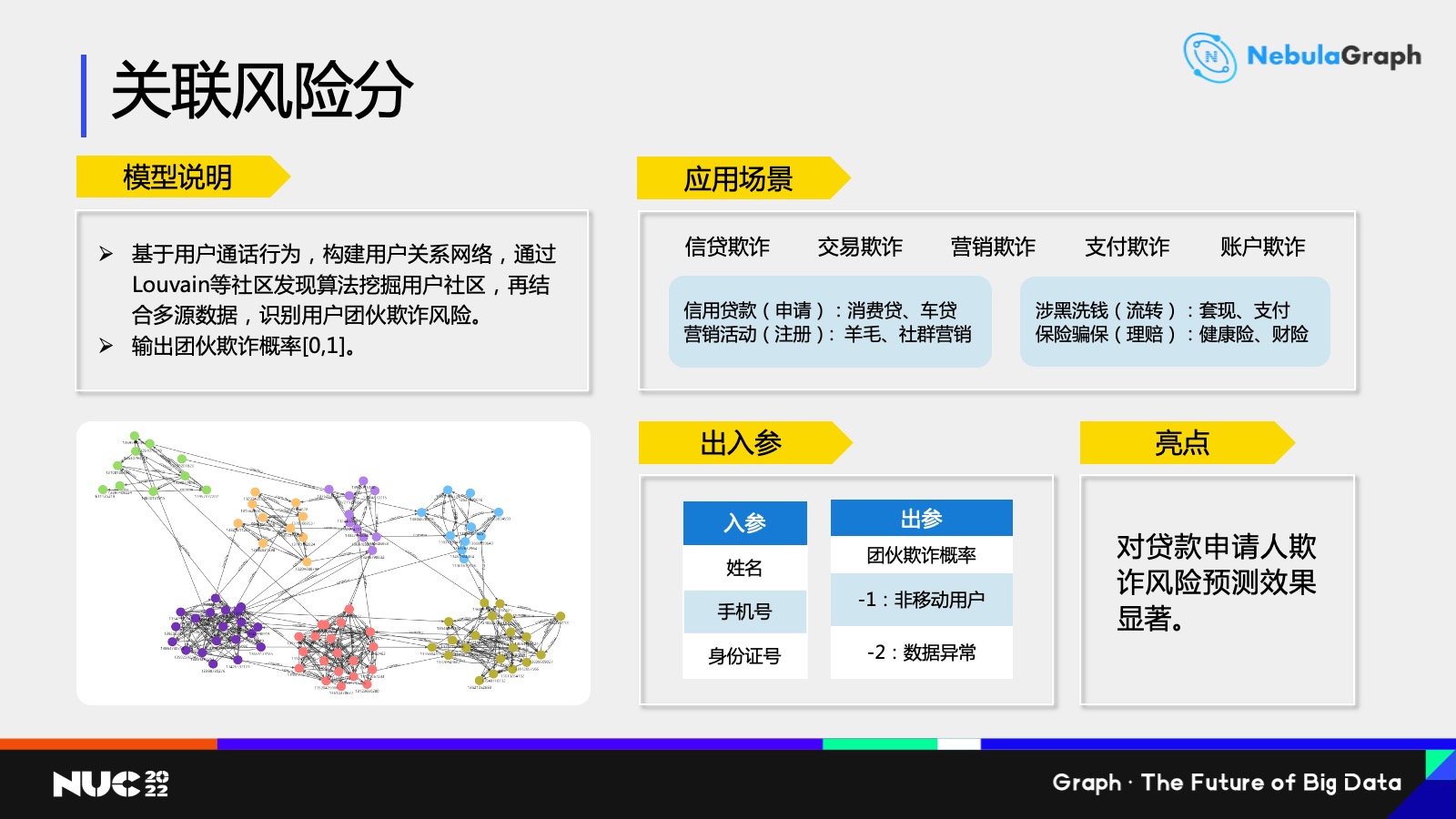
然后是关联风险分,通俗来说就是「近朱者赤近墨者黑」。
在平时交际圈,如果你的违约可能性比较低,那么周围人可能违约性也会比较低。基于这样一种想法,我们主要做法就是首先基于移动所有用户构建一个关系网络,然后采用一些社区发现类的算法去挖掘这个社区中个人的评分以及个人之间的关系,通过对这个社区打分,去识别出这个社区是否是欺诈或低信用社区。
关联风险分的主要应用场景就是欺诈领域,比如信贷欺诈、交易欺诈、营销欺诈、支付欺诈以及账户欺诈等等多个方面。
应用3:图神经网络(GNN)
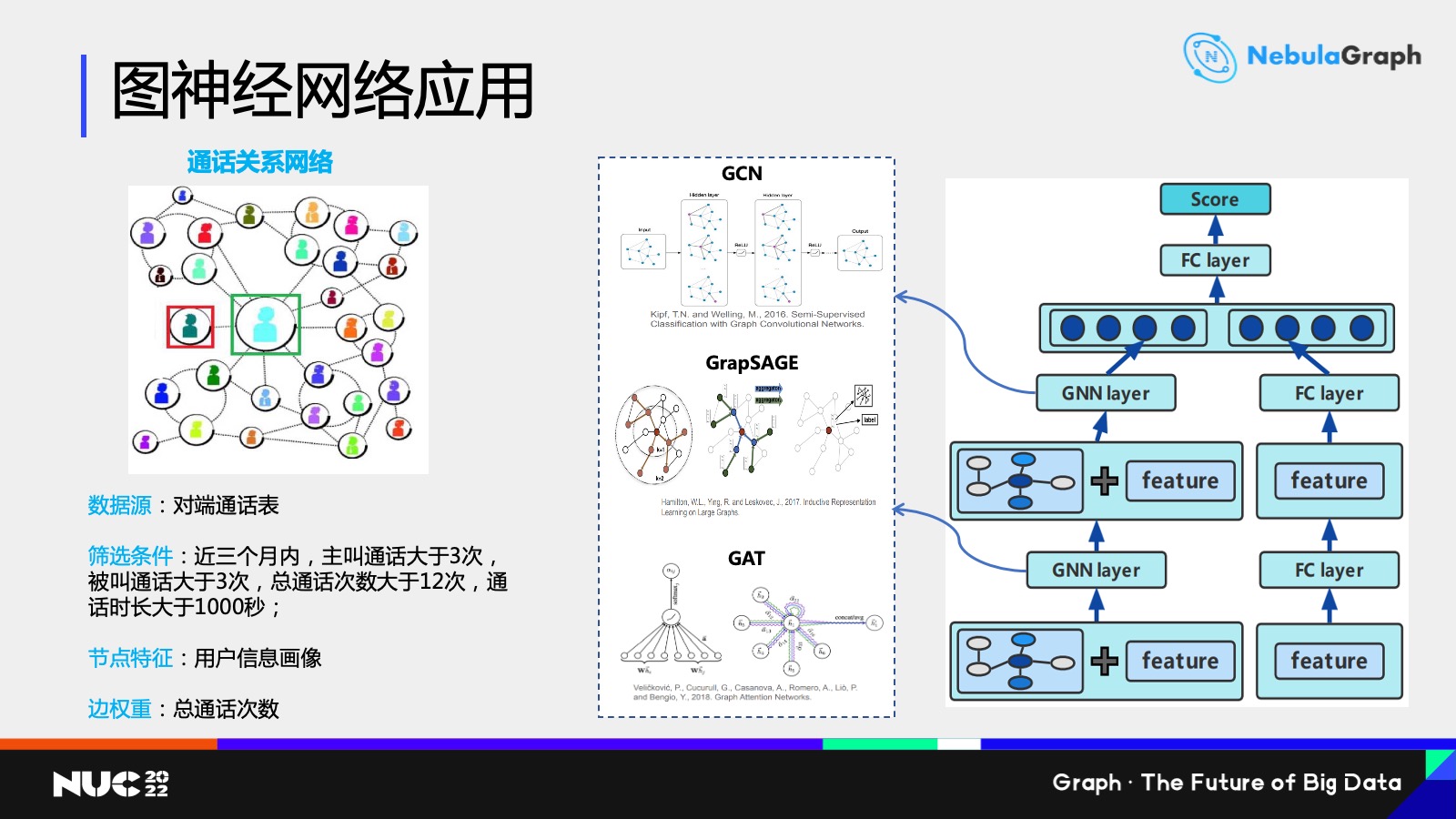
最后是关于图神经网络的一些应用,主要是用于金融风控信用评分卡的场景。过去我们用做信用评分卡大部分都是先提取用户特征,再训练一个逻辑回归模型或者是角色数字类的模型。
那么现在,我们想通过图神经网络做一些模型,通过用户之间通话数据,比如近三个月主动通话、被动通话以总通话次数是否达到要求,去判断要不要保留这样一条边。
我们大概提取 100 多个主要的特征去录模,这里的模型相对来说比较简单,目前是尝试了一个双塔的模型,左边的是关于图神经网络聚合的这样一个模型,右边用户特征本身的一个全连接网络做了这样 MLP 的模型。左边的神经网络聚合,是比较简单也是最常用的——GCN、GraphSAGE 和 GAT 这三个模型。
另外我们现在采用的是一个同构图的网络建模,后面可能会考虑异构图,比如说考虑用 HAN 这样的一些异构图的模型去建模,把用户的身份证和设备以及位置信息这些点都归纳进来,然后一起进行建模。
图数据应用的未来展望

1.数据血缘
中国移动大数据中心会提供给大概 30 多家客户的 50 多个项目进行共同的建模,建模工作里包含的数据维表会特别多,因为我们会给每个用户都匹配数据,然后帮他们生成特征,最后会把结果表也保存在数据库里面,大概现在有 1000 多张数据表,平时基本靠人工管理,后面看看能不能通过数据血缘的方式去做一个归纳。
2.图神经网络
中国移动除了大数据中心,还有人工智能中心,那里有很多的 GPU 资源进行人工神经网络的训练,但是目前模型训练效率比较低下,所以后面看看怎么用图数据技术去解决这个问题。
谢谢你读完本文 (///▽///)
NebulaGraph Desktop,Windows 和 macOS 用户安装图数据库的绿色通道,10s 拉起搞定海量数据的图服务。通道传送门:http://c.nxw.so/blVC6
想看源码的小伙伴可以前往 GitHub 阅读、使用、(^з^)-☆ star 它 → GitHub;和其他的 NebulaGraph 用户一起交流图数据库技术和应用技能,留下「你的名片」一起玩耍呢~