提问参考模版:
nebula 版本:3.4.1
部署方式: 分布式
安装方式:源 RPM
是否上生产环境:N
硬件信息
问题的具体描述
相关的 meta / storage / graph info 日志信息(尽量使用文本形式方便检索)
graph 的配置如下,但是发现,现在不生效,会出现OOM 系统杀掉graph, 而不是high watermark error
########## memory ##########
# System memory high watermark ratio, cancel the memory checking when the ratio greater than 1.0
--system_memory_high_watermark_ratio=0.9
########## metrics ##########
--enable_space_level_metrics=true
--meta_client_timeout_ms=200000
--num_operator_threads=16
--timezone_name=UTC+08:00
########## experimental feature ##########
# if use experimental features
--enable_experimental_feature=true
# if use balance data feature, only work if enable_experimental_feature is true
--enable_data_balance=true
########## session ##########
# Maximum number of sessions that can be created per IP and per user
--max_sessions_per_ip_per_user=300
########## memory tracker ##########
# trackable memory ratio (trackable_memory / (total_memory - untracked_reserved_memory) )
--memory_tracker_limit_ratio=0.8
# untracked reserved memory in Mib
--memory_tracker_untracked_reserved_memory_mb=50
# enable log memory tracker stats periodically
--memory_tracker_detail_log=false
# log memory tacker stats interval in milliseconds
--memory_tracker_detail_log_interval_ms=60000
# enable memory background purge (if jemalloc is used)
--memory_purge_enabled=true
# memory background purge interval in seconds
--memory_purge_interval_seconds=10
[96462.068504] [ pid ] uid tgid total_vm rss nr_ptes swapents oom_score_adj name
[96462.068511] [ 452] 0 452 9860 98 24 0 0 systemd-journal
[96462.068513] [ 482] 0 482 11350 129 23 0 -1000 systemd-udevd
[96462.068515] [ 586] 0 586 13883 111 27 0 -1000 auditd
[96462.068517] [ 694] 0 694 6653 158 18 0 0 systemd-logind
[96462.068519] [ 698] 999 698 153085 2394 62 0 0 polkitd
[96462.068521] [ 699] 81 699 14529 163 34 0 -900 dbus-daemon
[96462.068523] [ 704] 32 704 17314 135 38 0 0 rpcbind
[96462.068525] [ 727] 998 727 29483 138 29 0 0 chronyd
[96462.068527] [ 754] 0 754 48802 117 36 0 0 gssproxy
[96462.068529] [ 968] 0 968 25751 516 51 0 0 dhclient
[96462.068531] [ 1035] 0 1035 143572 2833 98 0 0 tuned
[96462.068533] [ 1177] 0 1177 22451 266 43 0 0 master
[96462.068535] [ 1179] 89 1179 22494 251 46 0 0 qmgr
[96462.068537] [ 1281] 0 1281 56680 177 46 0 0 rsyslogd
[96462.068539] [ 1291] 0 1291 6477 51 19 0 0 atd
[96462.068540] [ 1292] 0 1292 31598 162 18 0 0 crond
[96462.068543] [ 1303] 0 1303 27552 32 10 0 0 agetty
[96462.068544] [ 1304] 0 1304 27552 33 10 0 0 agetty
[96462.068546] [ 1387] 0 1387 28250 258 56 0 -1000 sshd
[96462.068548] [ 1621] 0 1621 109230 149 25 0 0 AliSecGuard
[96462.068550] [ 1754] 0 1754 6897 95 17 0 0 argusagent
[96462.068552] [ 1756] 0 1756 355054 3408 84 0 0 /usr/local/clou
[96462.068554] [ 2137] 0 2137 39572 511 80 0 0 sshd
[96462.068556] [ 2139] 0 2139 29107 324 13 0 0 bash
[96462.068558] [ 2376] 0 2376 204050 1621 19 0 0 aliyun-service
[96462.068560] [ 2498] 0 2498 4467 135 13 0 0 assist_daemon
[96462.068562] [13086] 0 13086 18114 227 40 0 0 sftp-server
[96462.068564] [17636] 0 17636 1115541 169979 1619 0 0 nebula-metad
[96462.068566] [17807] 0 17807 16473210 10122123 27736 0 0 nebula-storaged
[96462.068568] [ 477] 0 477 181772 2129 24 0 0 node_exporter
[96462.068569] [18520] 0 18520 54186767 21411837 93629 0 0 nebula-graphd
[96462.068571] [ 2933] 0 2933 10866 379 20 0 0 AliYunDunUpdate
[96462.068573] [ 3068] 0 3068 25093 317 49 0 0 AliYunDun
[96462.068574] [ 3078] 0 3078 32213 630 63 0 0 AliYunDunMonito
[96462.068576] [ 8725] 89 8725 22477 255 46 0 0 pickup
[96462.068577] Out of memory: Kill process 18520 (nebula-graphd) score 642 or sacrifice child
[96462.068779] Killed process 18520 (nebula-graphd), UID 0, total-vm:216747068kB, anon-rss:85647348kB, file-rss:0kB, shmem-rss:0kB
部署环境能否描述下, graphd是单独部署在一台机器上, 还是和其他graphd或者storaged混合部署;
memory tracker不会影响system_memory_high_watermark_ratio, memory tracker是比 system_memory_high_watermark_ratio更实时的内存检测方式,建议你将memory tracker以下两个配置改成如下,然后观察下nebula-graph.INFO日志,会输出内存使用的一些信息;
1 个赞
graphd或者storaged混合部署,好的,我看看
又OOM了, 以前nebula2 倒不会出现这个问题
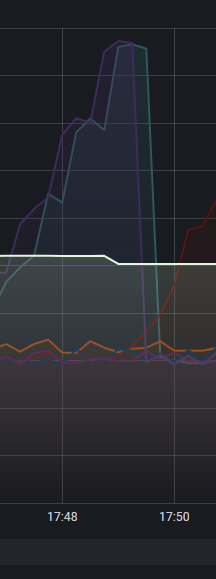
I20230329 17:48:35.794253 10835 MemoryUtils.cpp:227] sys:117.811GiB/123.768GiB 95.19% usr:76.193GiB/98.976GiB 76.98%
I20230329 17:48:36.794435 10835 MemoryUtils.cpp:227] sys:118.389GiB/123.768GiB 95.65% usr:76.193GiB/98.976GiB 76.98%
I20230329 17:48:38.793682 10835 MemoryUtils.cpp:227] sys:118.747GiB/123.768GiB 95.94% usr:76.193GiB/98.976GiB 76.98%
I20230329 17:48:39.793757 10835 MemoryUtils.cpp:227] sys:117.648GiB/123.768GiB 95.06% usr:76.193GiB/98.976GiB 76.98%
I20230329 17:48:40.961853 10835 MemoryUtils.cpp:227] sys:118.037GiB/123.768GiB 95.37% usr:76.194GiB/98.976GiB 76.98%
I20230329 17:48:42.794492 10835 MemoryUtils.cpp:227] sys:118.104GiB/123.768GiB 95.42% usr:76.195GiB/98.976GiB 76.98%
I20230329 17:48:43.795917 10835 MemoryUtils.cpp:227] sys:118.629GiB/123.768GiB 95.85% usr:76.195GiB/98.976GiB 76.98%
I20230329 17:48:44.797200 10835 MemoryUtils.cpp:227] sys:119.142GiB/123.768GiB 96.26% usr:76.195GiB/98.976GiB 76.98%
I20230329 17:48:45.798022 10835 MemoryUtils.cpp:227] sys:119.638GiB/123.768GiB 96.66% usr:76.195GiB/98.976GiB 76.98%
I20230329 17:48:47.794288 10835 MemoryUtils.cpp:227] sys:119.998GiB/123.768GiB 96.95% usr:76.197GiB/98.976GiB 76.99%
I20230329 17:48:49.793534 10835 MemoryUtils.cpp:227] sys:120.711GiB/123.768GiB 97.53% usr:76.197GiB/98.976GiB 76.99%
I20230329 17:48:50.793043 10835 MemoryUtils.cpp:227] sys:120.494GiB/123.768GiB 97.35% usr:76.197GiB/98.976GiB 76.99%
W20230329 17:48:50.793076 10835 MemoryUtils.cpp:133] Memory usage has hit the high watermark of system, available: 3.51604e+09 vs. total: 132895182848 in bytes.
I20230329 17:48:51.794507 10835 MemoryUtils.cpp:227] sys:119.365GiB/123.768GiB 96.44% usr:76.197GiB/98.976GiB 76.99%
I20230329 17:48:52.794596 10835 MemoryUtils.cpp:227] sys:118.743GiB/123.768GiB 95.94% usr:76.197GiB/98.976GiB 76.99%
I20230329 17:48:53.793732 10835 MemoryUtils.cpp:227] sys:117.343GiB/123.768GiB 94.81% usr:76.197GiB/98.976GiB 76.99%
I20230329 17:48:54.793874 10835 MemoryUtils.cpp:227] sys:117.091GiB/123.768GiB 94.61% usr:76.302GiB/98.976GiB 77.09%
I20230329 17:48:55.794014 10835 MemoryUtils.cpp:227] sys:117.646GiB/123.768GiB 95.05% usr:76.818GiB/98.976GiB 77.61%
I20230329 17:48:56.794164 10835 MemoryUtils.cpp:227] sys:117.982GiB/123.768GiB 95.32% usr:76.947GiB/98.976GiB 77.74%
I20230329 17:48:57.794296 10835 MemoryUtils.cpp:227] sys:118.082GiB/123.768GiB 95.41% usr:77.278GiB/98.976GiB 78.08%
I20230329 17:48:59.794512 10835 MemoryUtils.cpp:227] sys:118.154GiB/123.768GiB 95.46% usr:77.380GiB/98.976GiB 78.18%
I20230329 17:49:00.793670 10835 MemoryUtils.cpp:227] sys:118.595GiB/123.768GiB 95.82% usr:77.376GiB/98.976GiB 78.18%
I20230329 17:49:01.796144 10835 MemoryUtils.cpp:227] sys:118.906GiB/123.768GiB 96.07% usr:77.328GiB/98.976GiB 78.13%
I20230329 17:49:02.849840 10835 MemoryUtils.cpp:227] sys:119.443GiB/123.768GiB 96.51% usr:77.328GiB/98.976GiB 78.13%
I20230329 17:49:04.794605 10835 MemoryUtils.cpp:227] sys:120.177GiB/123.768GiB 97.10% usr:77.328GiB/98.976GiB 78.13%
I20230329 17:49:06.793864 10835 MemoryUtils.cpp:227] sys:121.893GiB/123.768GiB 98.48% usr:77.589GiB/98.976GiB 78.39%
请帮忙看下这个是为啥,sys 显示 98%, usr 78% 这个是配置哪里不对吗
sys: 系统层面的进程内存使用情况;
usr: MemoryTracker track的内存使用情况; (当usr的使用率达到100%时, 触发这个阈值的查询会失败报错);
举例:
你这种情况,要调小 memory_tracker_limit_ratio, 因为是混合部署环境, 需要规划一下, 几个服务进程的内存, 比如, 把30%分配storaged, 50%分给graphd;
memory tracker的一些配置参考:
sys: 系统层面的进程内存使用情况 这个因为服务器只有nebula 的服务可以简单介绍下sys 哪些东西会使用这么高内存吗
把30%分配storaged, 50%分给graphd;
同时还有个问题是,–rocksdb_block_cache 这个设置了1/3 总内存,这个算做memory tracker 管理的内存吗?
sys就是操作系统层面看到的, 所有进程的内存使用都会算进去;你可以通过top看进程的内存占用情况;
是的,你理解没错;
rocksdb_block_cache 会算到memory tracker 管理的内存;
1 个赞
非常感谢!
目前有什么设置建议嘛? 总共128G, storage 和 graph 使用内存大小哪个更大点?逻辑上查询层结果要汇总到某个节点的leader 返回给客户端,是不是graph 应该更高点?
同时对这个触发还有个疑问?
原来的 system_memory_high_watermark_ratio 是对graph 设置的,这个看起来是sys 层面,看上面的 log 应该超过了90% 一直没触发high watermark,导致系统kill 了graph 这个和之前的版本表现不一致了吧?
如果system_memory_high_watermark_ratio 是观察系统的,正常起作用,三者都设置了,因为有memory tracker 针对graph 和storage 的,这个system_memory_high_watermark_ratio 参数先graph 到达了ratio 就会kill graphd 的意思吗?
Reid00:
统的,正常起作用,
是的, 按照我们之前的经验, 一般是graph需要的内存会多一些;你可以通过前面的日志观察storage和graph的内存使用情况;酌情配置;
另外不管是system_memory_high_watermark_ratio还是memory tracker都是 “通过使查询失败的方式”, 防止 查询使用内存过多导致被进程被系统OOM kill, 如果你的查询负载会是graph oom, 那你可能还需要优化下query, 或者调整下其他参数, 比如查询并发度 (在workload是并发情况下)’
MemoryTracker的原理可以看这篇文章:https://mp.weixin.qq.com/s/hxs5XZ0XPDpt_a46B6D7Ow
1.system_memory_high_watermark_ratio这个和之前版本一致的, 它原理是在执行过程中打点,在一些情况下防不住oom kill;
2.memory tracker 目前是对 graph 和storage 的配置相对于系统内存的百分比, 它的内存监控会更加精确些, memory_tracker_limit_ratio的配置,参考NebulaGraph Database 手册:
取值可设置为:(0, 1]、2、3。
I20230403 17:14:18.985951 17324 MemoryUtils.cpp:227] sys:34.712GiB/125.754GiB 27.60% usr:28.763GiB/50.282GiB 57.20%
I20230403 17:15:18.986356 17324 MemoryUtils.cpp:227] sys:42.229GiB/125.754GiB 33.58% usr:36.218GiB/50.282GiB 72.03%
I20230403 17:16:19.985954 17324 MemoryUtils.cpp:227] sys:49.830GiB/125.754GiB 39.62% usr:43.767GiB/50.282GiB 87.04%
I20230403 17:17:19.986378 17324 MemoryUtils.cpp:227] sys:57.357GiB/125.754GiB 45.61% usr:51.232GiB/50.282GiB 101.89%
I20230403 17:18:19.985491 17324 MemoryUtils.cpp:227] sys:64.789GiB/125.754GiB 51.52% usr:58.604GiB/50.282GiB 116.55%
I20230403 17:19:19.986600 17324 MemoryUtils.cpp:227] sys:72.368GiB/125.754GiB 57.55% usr:66.142GiB/50.282GiB 131.54%
I20230403 17:20:19.985999 17324 MemoryUtils.cpp:227] sys:79.704GiB/125.754GiB 63.38% usr:73.421GiB/50.282GiB 146.02%
你好,看log storaged 设置的大小50.282, 为啥现在使用为146% 73.421G , 这个最大能使用多少?
理论是超过100会kill, 但有一些情况目前没有覆盖
codesigner:
走到rocksdb的读取路径上时
当时应该是在做Compaction 。
关于MemoryTracker想请教个问题。MemoryTracker是针对具体服务(Graphd、Storage)来做内存管理。参数memory_tracker_limit_ratio是可用内存低于某个值就停止查询。如果混部场景且是物理机部署的情况下。memory_tracker_limit_ratio是不是不能代表服务能占用的内存比例?
SwimSweet:
比例
memory_tracker_limit_ratio是graph/storage可使用内存 / 系统总内存 的 比例;图数据库 NebulaGraph 的内存管理实践之 Memory Tracker Memory Tracker 可用内存章节;
这里说法不正确,Graphd配置了50%, 那么Graphd可使用的内存在50G左右, 有查询来以后, 查询过程中会消耗50G的部分或者全部内存, 查询结束或者失败均会释放该查询占用的内存, 在某一个时间点,某个查询在申请内存时触发了50G内存用完的阈值,该查询就会失败,后续查询如果仍然触发此类情况, 后续查询也因相同原因被kill, 而不是 “可用内存为50G以上才能接受查询”
system
2023 年5 月 7 日 05:52
18
此话题已在最后回复的 30 天后被自动关闭。不再允许新回复。