nebula 版本:3.4.0
部署方式:单机
安装方式: tar.gz
是否上生产环境:Y
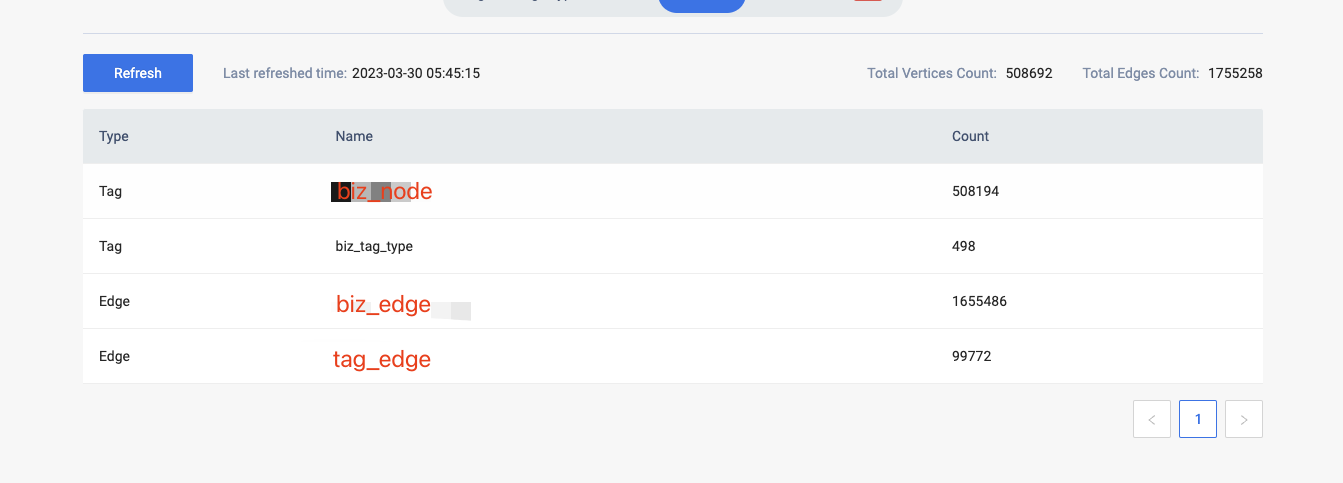
硬件信息
磁盘( 推荐使用 SSD): 阿里云ESSD
CPU、内存信息:16核(vCPU) 128 GiB
问题的具体描述
查询任务需求:
数据情况统计:
查询方式:
MATCH p=(v:biz_node)-[e:`biz_edge`*1..3]->(v2:biz_node)-[e1:`tag_edge`*1]->(v3:biz_tag_type)
WHERE id(v) == "ID-jwhE5Y9CSJ1zCbiNMvTW4U1mxwgrvX" and id(v3) == "user_tag-1"
RETURN p
LIMIT 5;
执行时间消耗 53.348948 (s)
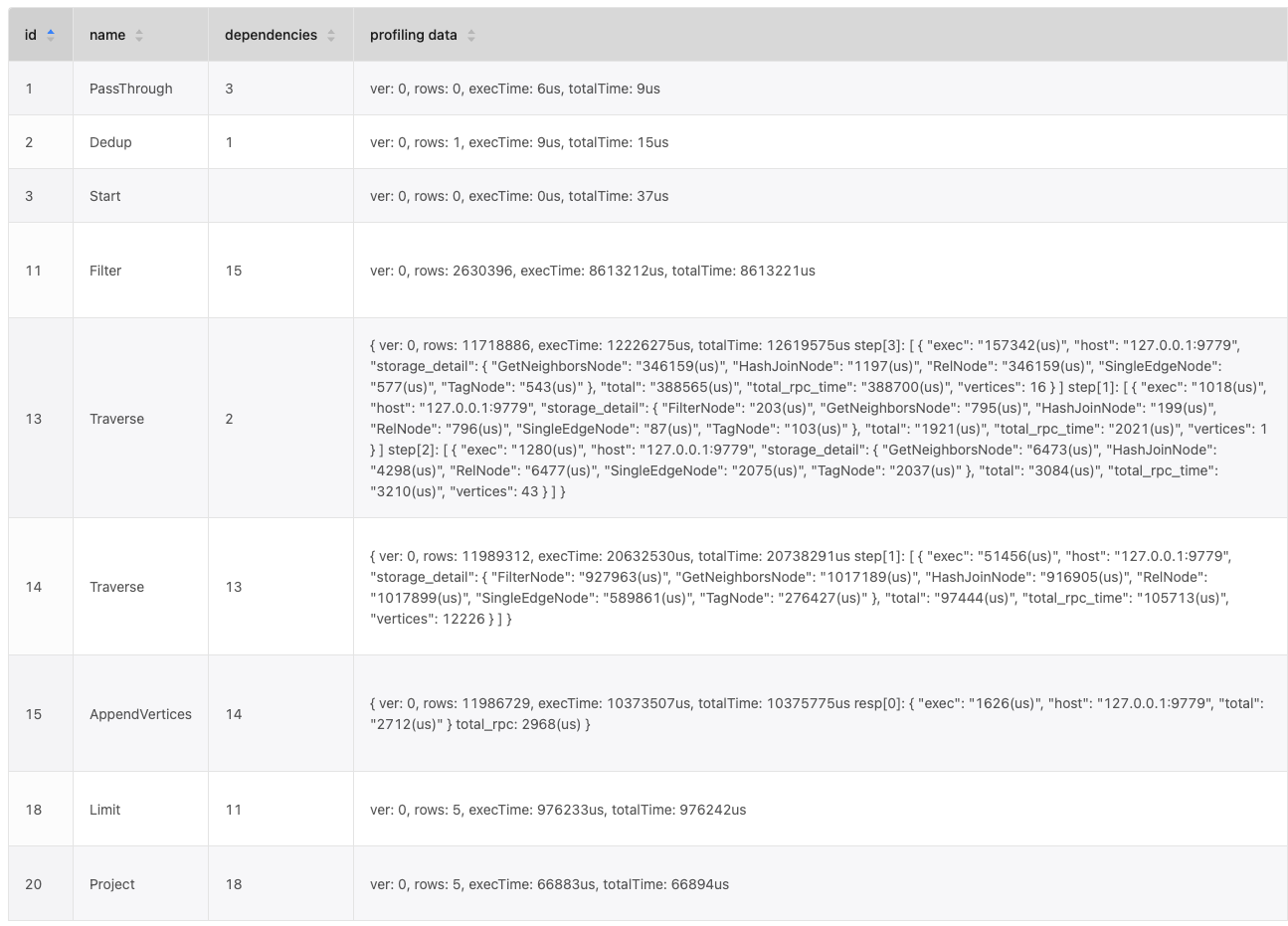
Profile语句情况:
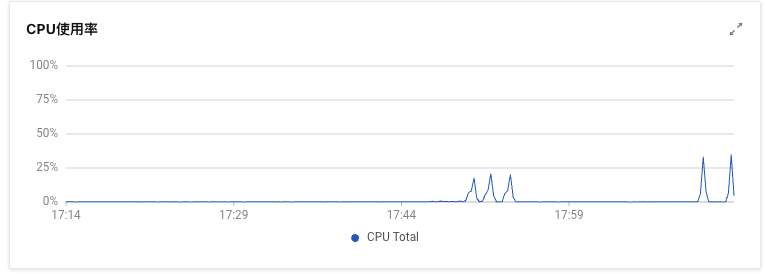
服务器资源监控:
补充说明:
根据之前的建议把业务标签作为Tag进行设计的MVP,这个你现在是怎么做的?
yee
2023 年3 月 30 日 08:19
4
查询中一定要用路径 p 吗?因为现在 nebula 中对路径 p 的实现比较重,这也是比较耗性能的地方。如果知道点边就可以,你可以试试下面的查询:
MATCH (v:biz_node)-[e:`biz_edge`*1..3]->(v2:biz_node), (v3:biz_tag_type)<-[e1:`tag_edge`*1]-(v2)
WHERE id(v) == "ID-jwhE5Y9CSJ1zCbiNMvTW4U1mxwgrvX" and id(v3) == "user_tag-1"
RETURN v,e,v2, e1, v3
LIMIT 5
不用p路径,执行时间消耗 54.085143 (s),还有一个问题就是limit下推这么多版本还是没有走到存储层么
现在还存在资源没打上来,不了解为啥nebula查得慢时还不消耗资源的原因
yee
2023 年3 月 30 日 09:38
7
在 nebula-graphd.conf 修改一下 graph 如下的配置看看:
--max_job_size=12
估计是 graph 的并发执行没有利用上。limit 的优化这个涉及到执行模式的修改,像现在这种多步拓展是不能简单的直接将 limit 下推到存储层的。后面再考虑其他的优化方式
这个参数加上后,执行时间消耗 44.677033 (s),但是我double size,执行时间并没有变化了
我把v->v2->v3 拆分成您建议的v->v2, v3<-v2之后,执行时间消耗来到了 39.861758 (s);
yee
2023 年3 月 30 日 11:17
11
如果数据中没有悬挂边的话,可以在 nebula-graphd.conf 中再加上下面的配置:
--optimize_appendvertices=true
然后再看看 profile 的结果
yee
2023 年3 月 31 日 02:02
13
好,多谢反馈。
想再问一下,上述查询中写了 LIMIT,这个限制是表示业务中只要随便 5 条路径就可以吗?还是因为性能的原因才加的这个约束?之前提了 issue ,想再进一步了解看看怎么在 nebula 中做些优化。
1 个赞
之前性能考虑,也担心样本的数据可能偏离一般情况太多导致结果集很大,但是如果limit仅在计算最后才处理,好像加不加也没啥关系
system
2023 年4 月 30 日 05:45
16
此话题已在最后回复的 30 天后被自动关闭。不再允许新回复。