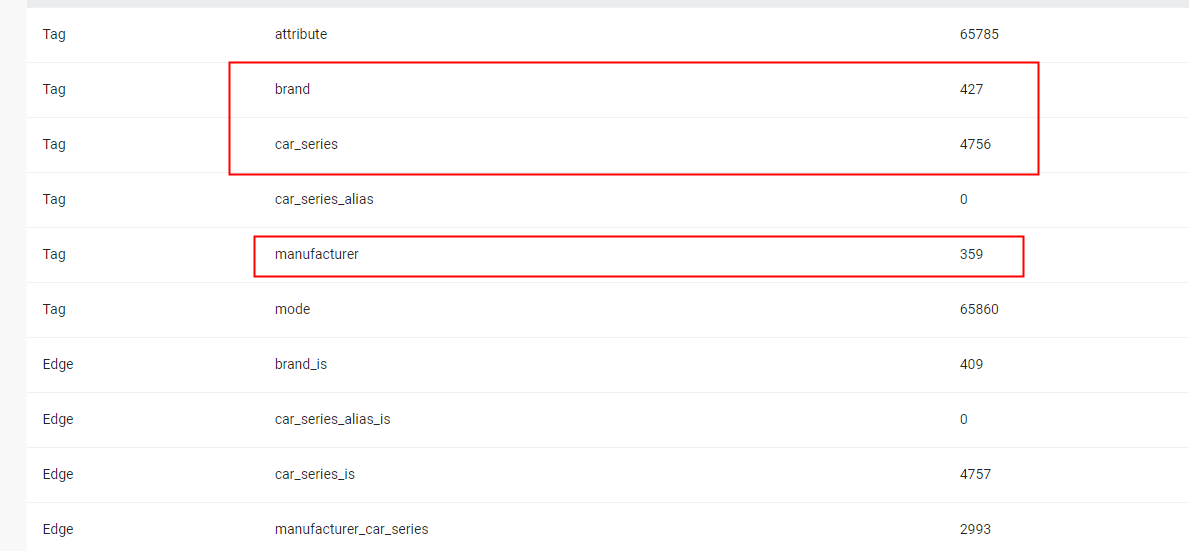
- nebula 版本:V3.3.0
- 部署方式: 单机
- 安装方式:RPM
- 是否上生产环境:N
- 硬件信息
- 磁盘500G
- CPU、内存信息 16核32G
- 问题的具体描述
- 使用exchange导入数据报错,已经尝试调小batch,fetchSize,partition参数。

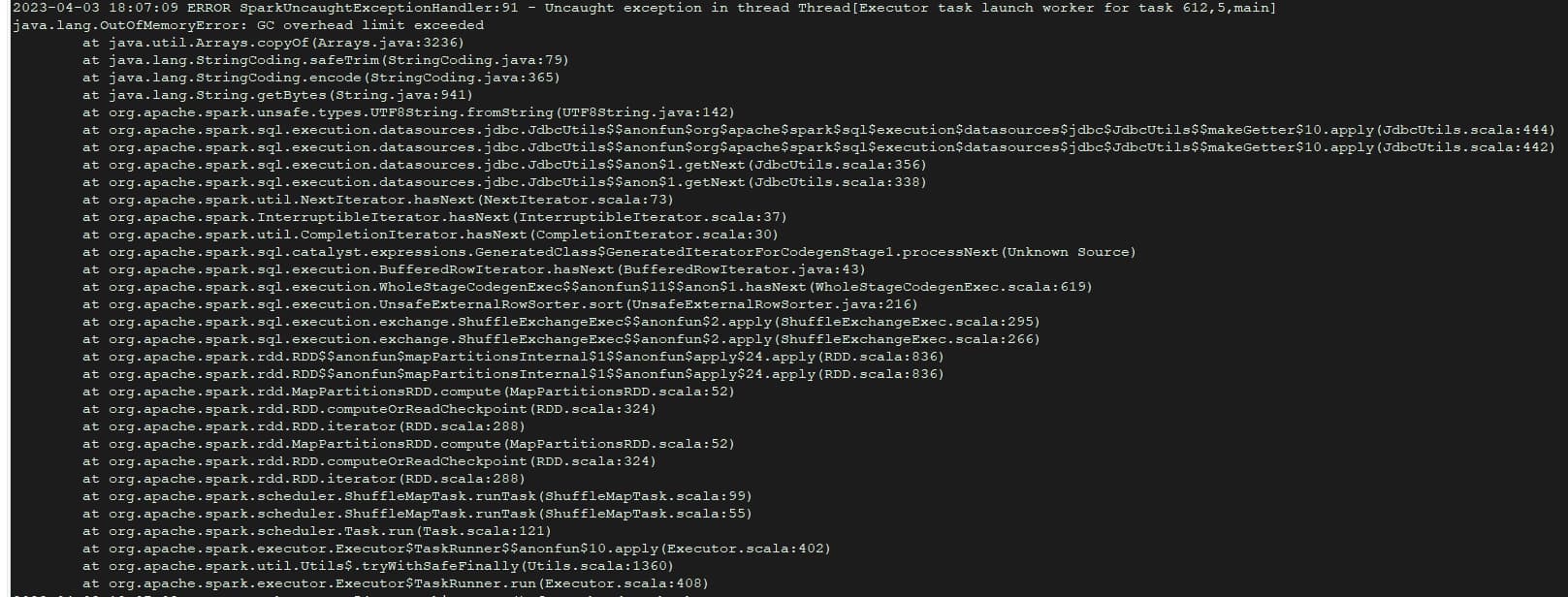
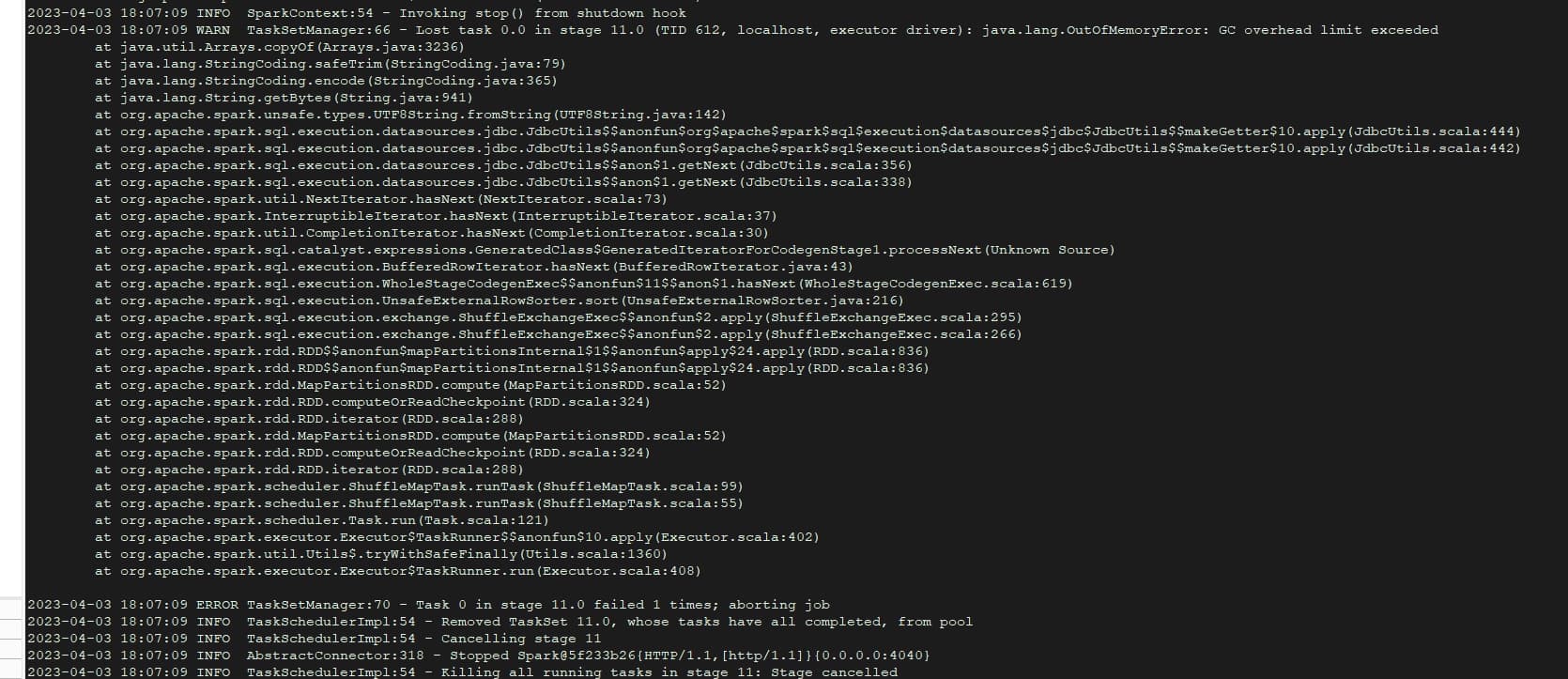
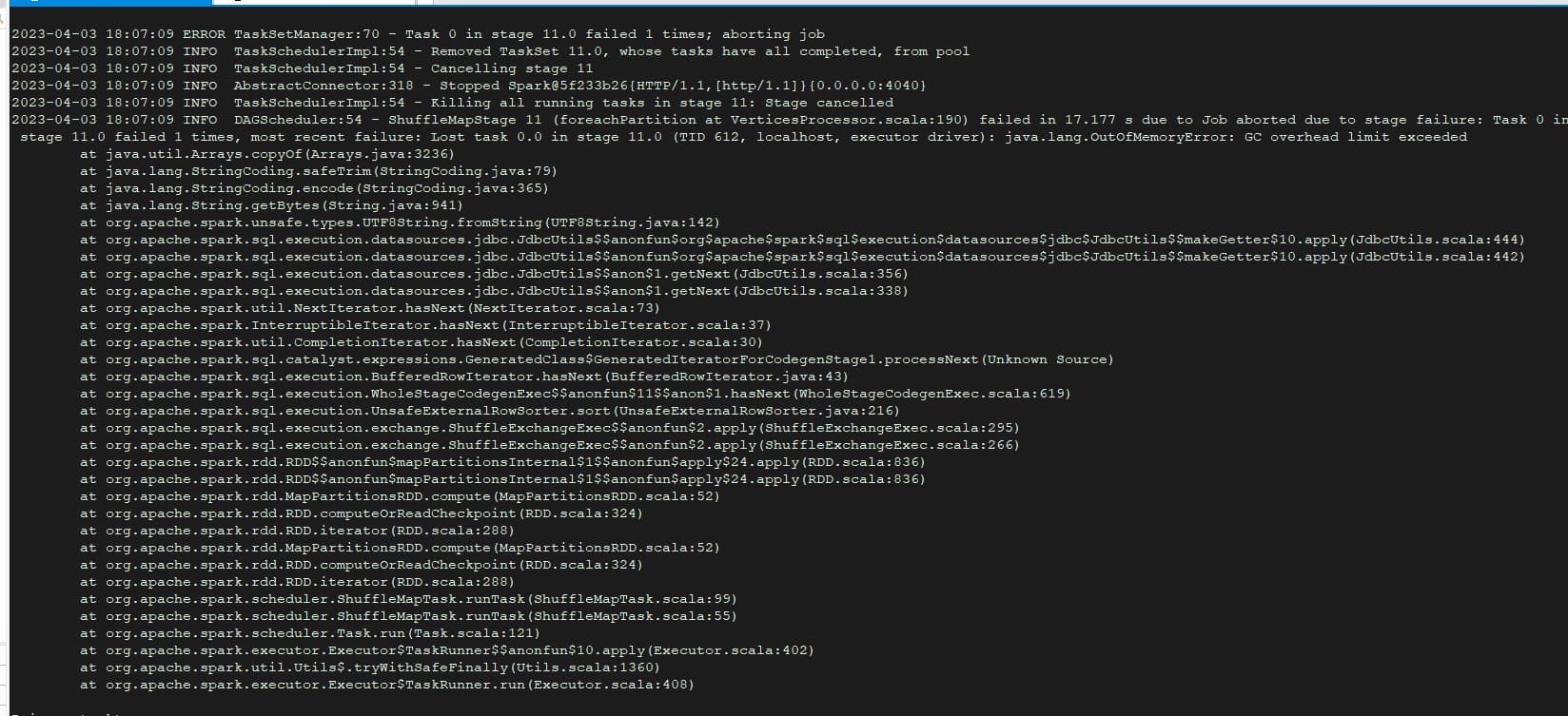
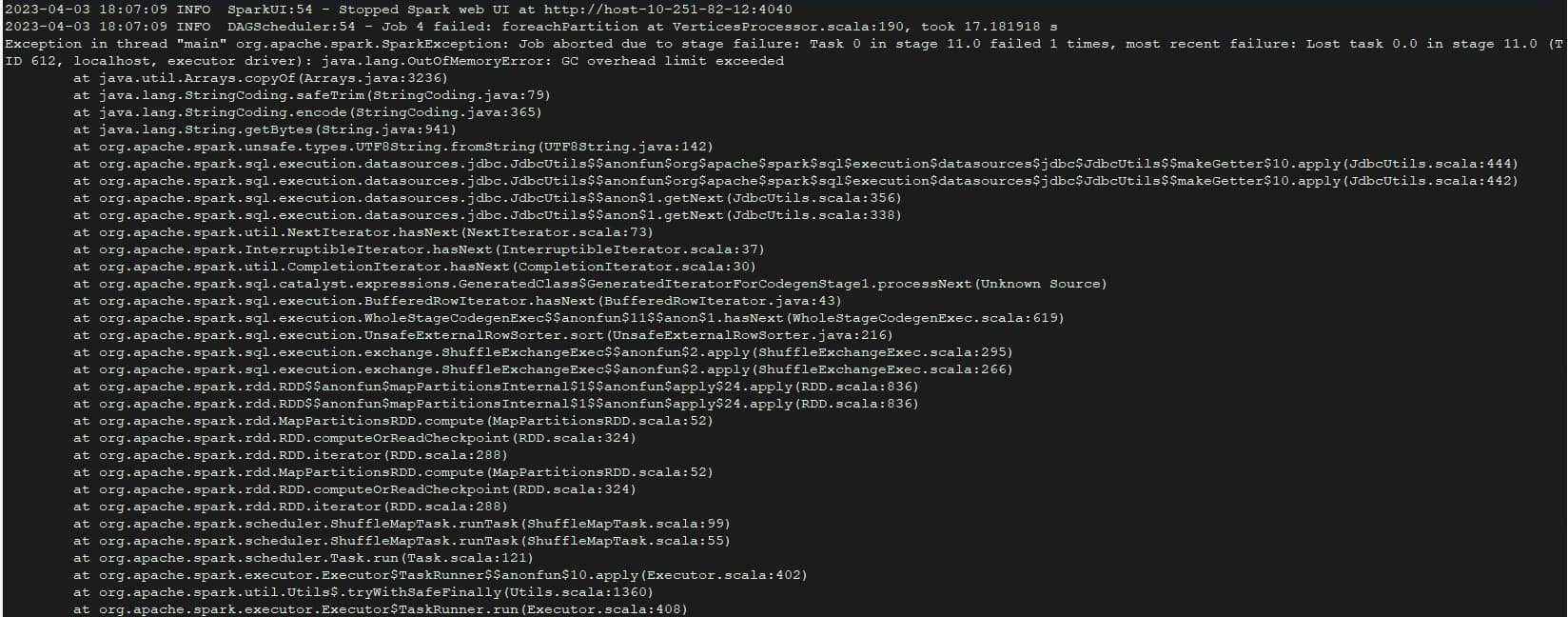
部分conf配置文件如下
{
# Spark 相关配置
spark: {
app: {
name: NebulaGraph Exchange 3.3.0
}
driver: {
cores: 1
maxResultSize: 0
}
executor: {
memory: 1G
}
#cores: {
#max:
#}
}
# NebulaGraph 相关配置
nebula: {
address: {
# 指定 Graph 服务和所有 Meta 服务的 IP 地址和端口。
# 如果有多台服务器,地址之间用英文逗号(,)分隔。
# 格式:"ip1:port","ip2:port","ip3:port"
graph: ["127.0.0.1:9669"]
meta: ["127.0.0.1:9559"]
}
# 指定拥有 NebulaGraph 写权限的用户名和密码。
user: root
pswd: nebula
# 指定图空间名称。
space: Insight_test_json_1
connection: {
timeout: 3000
retry: 3
}
execution: {
retry: 3
}
error: {
max: 32
output: /data/nebula-exchange/error
}
rate: {
limit: 32
timeout: 500
}
}
# 处理点
tags: [
# 设置 Tag brand 相关信息。
{
# 指定 NebulaGraph 中定义的 Tag 名称。
name: brand
type: {
# 指定数据源,使用 JDBC。
source: jdbc
# 指定如何将点数据导入 NebulaGraph:Client 或 SST。
sink: client
}
# JDBC 数据源的 URL。示例为 MySql 数据库。
url: "jdbc:mysql://*.*.*.*:3306/nebula?useUnicode=true&characterEncoding=utf-8"
# JDBC 驱动。
driver: "com.mysql.cj.jdbc.Driver"
# 数据库用户名和密码。
user:**
password: "**"
table: ***
sentence: "SELECT DISTINCT `brand` FROM `**`"
fetchSize: 500 # 每次请求数据库要读取的行数。
# 在 fields 里指定 gsc_car_model_1 表中的列名称,其对应的 value 会作为 NebulaGraph 中指定属性。
# fields 和 nebula.fields 里的配置必须一一对应。
# 如果需要指定多个列名称,用英文逗号(,)隔开。
fields: []
nebula.fields: []
# 指定表中某一列数据为 NebulaGraph 中点 VID 的来源。
vertex: {
field: brand
}
# 单批次写入 NebulaGraph 的数据条数。
batch: 8
# Spark 分区数量
partition: 2
}
]
最后烦请删掉本模版和问题无关的信息之后,再提交提问,Thx