- nebula 版本:3.4.0
- 部署方式:分布式
- 安装方式:源码编译
- 是否上生产环境: N
- 硬件信息
- 磁盘:HDD
MATCH (v) RETURN v limit 3; 以这个查询语句为例子,match过程中最终是怎么通过从 rocksDB上取到数据的?对ScanVertexProcessor之后的逻辑不太明白
如果没有索引的话是如下的逻辑, 类型为ScanVertices,执行ScanVertexProcessor的runInSingleThread方法后,之后的逻辑是执行哪个node.cpp,可能是IndexLimitNode.cpp?
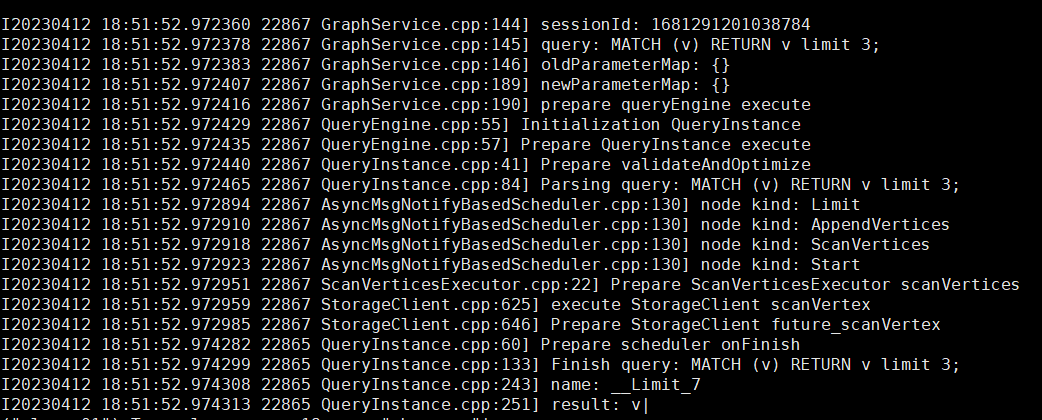

如果有索引的话,类型为IndexScan,会执行IndexNode.cpp的doNext方法,猜测是通过getBaseData读取数据,getBaseData()只有IndexVertexScanNode这个类有,插入了日志,但是这个方法并没有执行,是为什么?
哪个查询会执行 IndexVertexScanNode 的getBaseData方法,试了match、fetch、lookUp(更不会执行这个方法)都没执行。