仅以此文纪念下我和 NebulaGraph 的相遇故事。
我第一次听说NebulaGraph是老板开完会回来跟我讲的。老板告诉我,我有一周的时间,学习NebulaGraph,包括库搭建、配套工具使用、项目整合、SQL编写以及其他相关文档等等。
老板还说,如果以后谁有了与这方面相关的问题,他们都会来问我。我回答道:“好的。”
虽然之前我没有听过这个产品,但对于新技术,我一直都很感兴趣,所以我决定干起来。
新手初试:搞定安装
第一步,我在官网的 NebulaGraph Database 手册上了解了什么是图数据库和图模式,然后我就开始着手搭建数据库了。因为 NebulaGraph 是国产的,所以看文档的时候感觉没什么压力。这个步骤很顺利,我很快就把数据库装好了。
试试高级玩法:企业服务
第二步,申请可视化产品NebulaGraph Explorer和NebulaGraph Dashboard,这里其实有个坑,因为我没看仔细,所以一下子就把两个都申请了。其实可以一个用完再申请另一个,这样免费的工具可以多用一个月。在这个过程中,添加了nebula的活泼有趣努力认真的客服Lisa~(其实一开始以为是机器人的),又进了官方技术交流群,讲道理,这个交流群会是我这次体验最好的亮点。当我遇到问题时,都可以在这里及时得到思路。
第三步,拿到安装包后,我继续照文档上的安装步骤安装。
实战开始:nGQL 语句的编写
第四步,NGql实战。基础工作都差不多了,就开始NGql实战了,去找SJ项目老大(目前公司会用到该技术的一个项目)要了一份需求,至少需要知道自己至少要学到什么程度才行,其中的一部分需求如下:
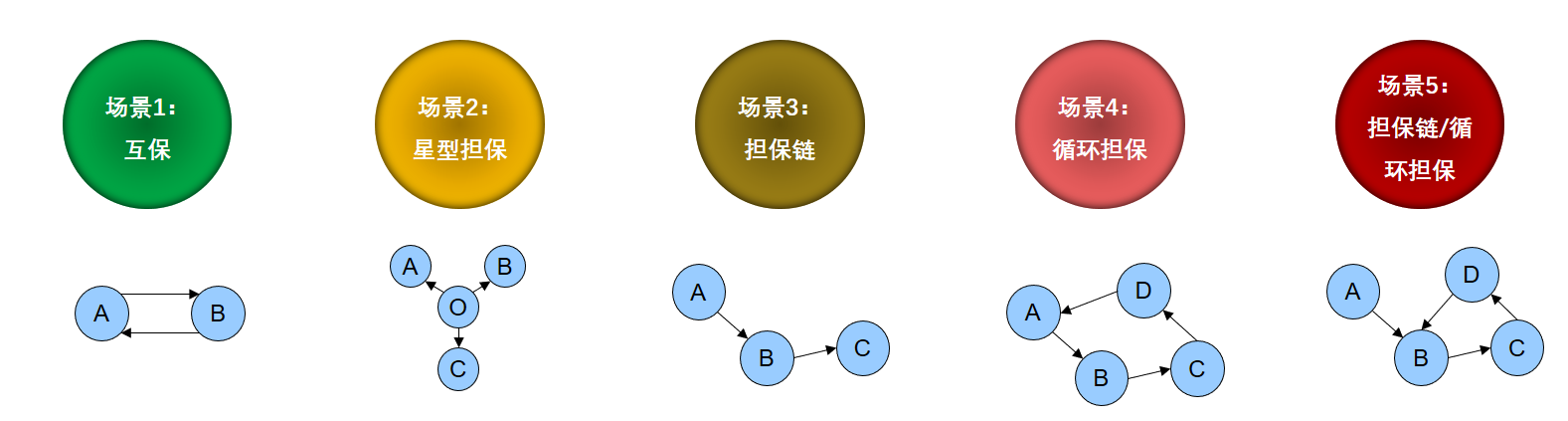
好家伙,几乎都是全图扫描。拿第一个举例,我想找出所有存在“双向边”的路径,我的第一反应是自己跳两次以后跳回到自己。这样就可以判断“场景一”的双向边路径了。
MATCH p=(v:player)-[*2]->(v) RETURN p LIMIT 100
其实上面的NGql是可以查出来的,但是我需要全图扫面,不想用tag属性,比如下面这个
MATCH p=(v)-[*2]->(v) RETURN p LIMIT 100;
就会报错?我不理解,所以去技术群里求教了,可能是写法比较奇怪,所以还引起了一些小的争执,最后是程训焘大佬解释的

好吧 看来不写tag是不行了,那就所有的点都加上一个一致的tag,这样勉强能实现全图扫描的问题,只是效率比较差。
再举一个例子“场景四”环形路径(查询space中所有环形路径的信息列表,一个环形当作一条路径)对于全图扫描环形路径,我没有特别好的想法,所以又去群里寻求了帮助,这次只得到一个“数据导入到spark再计算”的答复,(小小的不满意),最后跟经理沟通以后,我的写法还是用上面的思路,让自己N跳最后回到自己。(大胆的实现了不能解决需求,就改变需求)。当然这次是特殊情况,如果需求不能改变,还是需要去想如何实现,事后我也尝试了几次,奈何实力有限,没有写出来。不知道如果购买了企业版能不能能到技术支持?
第五步是boot整合nebulaGraph,第六步是文档整理。
总结:整体感受
在使用nebulaGraph的整个过程中都是比较顺畅的,很大原因是因为有讨论群的存在,能及时了解到最新技术。还有论坛也很有用,一些问题我都会去论坛里找思路,比如boot整合nebula时,session满了获取新session会报错的处理,知道了session 是完全由用户自己管理,session.release() 会通知服务端把当前 session 移除, 同时在客户端把 connection 返还给连接池的 idle 队列。所以我针对性的修改了部分代码,其实也就是在每次使用完session之后就把它移除了

用完就移除

目前SJ项目关于nebula的部分已经开发完成,正在测试中,希望nebulaGraph越来越好。
本文正在参加 NebulaGraph 征文活动,如果你觉得本文对你有所帮助可以给我点个  以示鼓励~ 谢谢
以示鼓励~ 谢谢
