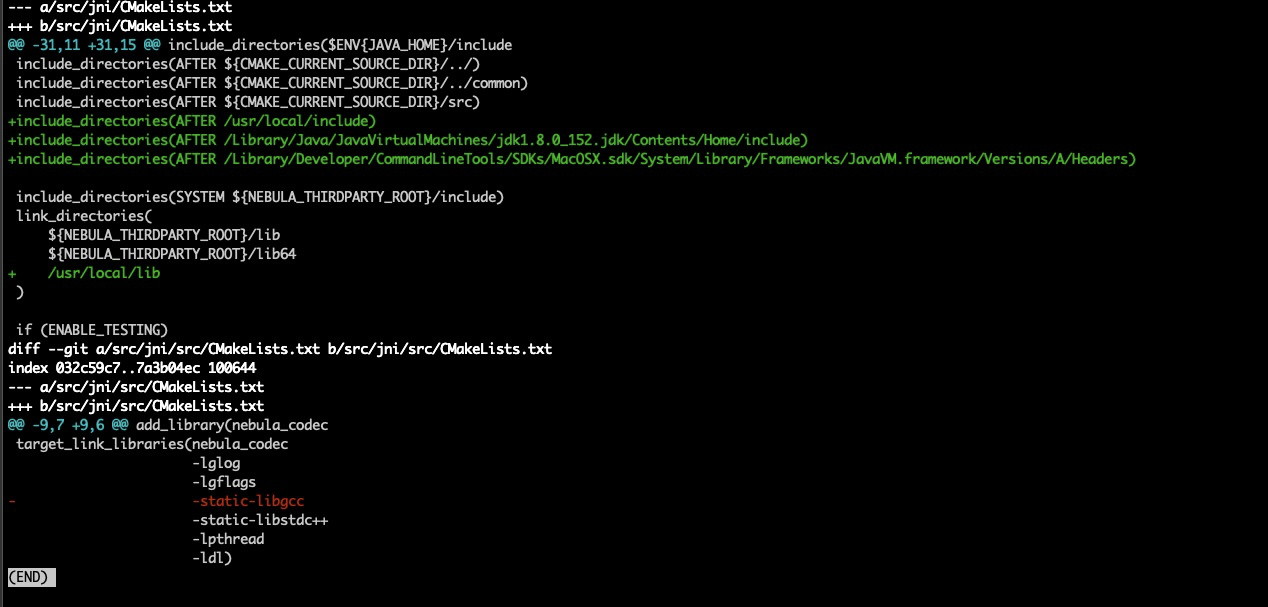
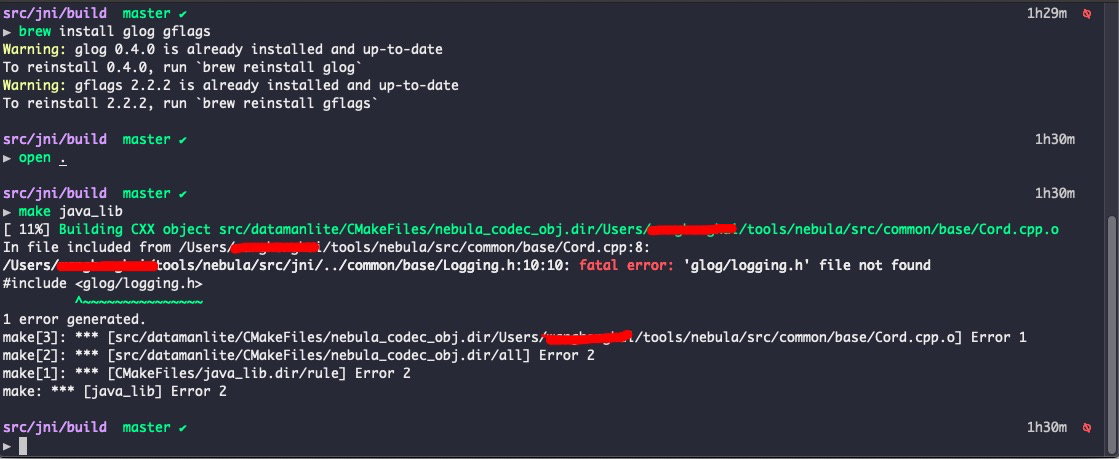
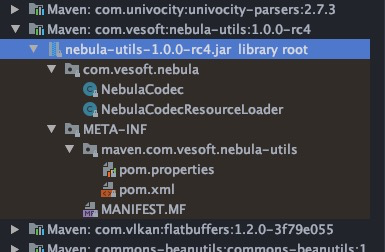
使用master分支的NebulaReaderExample运行报错如下:
ERROR [Executor task launch worker for task 0] - Exception in task 0.0 in stage 0.0 (TID 0)
java.lang.UnsatisfiedLinkError: /private/var/folders/vx/tsqg0pgs7mbdf_wjd2t88_ch0000gn/T/nativeutils235051160004036/libnebula_codec.so: dlopen(/private/var/folders/vx/tsqg0pgs7mbdf_wjd2t88_ch0000gn/T/nativeutils235051160004036/libnebula_codec.so, 1): no suitable image found. Did find:
/private/var/folders/vx/tsqg0pgs7mbdf_wjd2t88_ch0000gn/T/nativeutils235051160004036/libnebula_codec.so: unknown file type, first eight bytes: 0x7F 0x45 0x4C 0x46 0x02 0x01 0x01 0x03
/private/var/folders/vx/tsqg0pgs7mbdf_wjd2t88_ch0000gn/T/nativeutils235051160004036/libnebula_codec.so: unknown file type, first eight bytes: 0x7F 0x45 0x4C 0x46 0x02 0x01 0x01 0x03
at java.lang.ClassLoader$NativeLibrary.load(Native Method)
at java.lang.ClassLoader.loadLibrary0(ClassLoader.java:1934)
at java.lang.ClassLoader.loadLibrary(ClassLoader.java:1817)
at java.lang.Runtime.load0(Runtime.java:809)
at java.lang.System.load(System.java:1086)
at com.vesoft.nebula.utils.NativeUtils.loadLibraryFromJar(NativeUtils.java:56)
at com.vesoft.nebula.data.RowReader.<clinit>(RowReader.java:35)
at com.vesoft.nebula.client.storage.processor.ScanVertexProcessor.process(ScanVertexProcessor.java:47)
at com.vesoft.nebula.client.storage.processor.ScanVertexProcessor.process(ScanVertexProcessor.java:26)
at com.vesoft.nebula.reader.ScanVertexIterator.hasNext(ScanVertexIterator.java:60)
at scala.collection.Iterator$$anon$10.hasNext(Iterator.scala:458)
at org.apache.spark.sql.catalyst.expressions.GeneratedClass$GeneratedIteratorForCodegenStage1.processNext(Unknown Source)
at org.apache.spark.sql.execution.BufferedRowIterator.hasNext(BufferedRowIterator.java:43)
at org.apache.spark.sql.execution.WholeStageCodegenExec$$anon$2.hasNext(WholeStageCodegenExec.scala:636)
at org.apache.spark.sql.execution.SparkPlan.$anonfun$getByteArrayRdd$1(SparkPlan.scala:255)
at org.apache.spark.rdd.RDD.$anonfun$mapPartitionsInternal$2(RDD.scala:836)
at org.apache.spark.rdd.RDD.$anonfun$mapPartitionsInternal$2$adapted(RDD.scala:836)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:52)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:324)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:288)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:52)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:324)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:288)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:90)
at org.apache.spark.scheduler.Task.run(Task.scala:123)
at org.apache.spark.executor.Executor$TaskRunner.$anonfun$run$3(Executor.scala:411)
at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1360)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:414)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)