-
brew install cmake
-
brew install glog gflags
-
安装 gtest,参考: macos - How to install GTest on Mac OS X with homebrew? - Stack Overflow
-
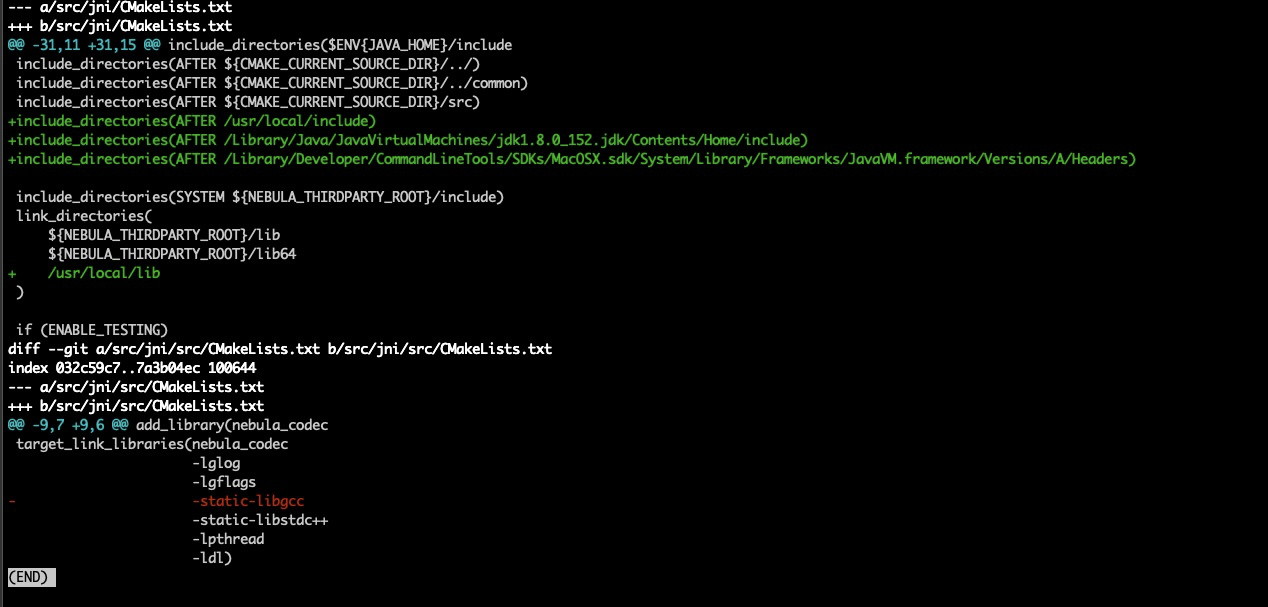
修改
nebula/src/jni/CMakeLists.txt和nebula/src/jni/src/CMakeLists.txt
-
编译 libnebula_codec.so https://github.com/vesoft-inc/nebula/tree/master/src/jni