在进行各种图处理、图计算、图查询的时候,内存或是硬盘中如何存储图结构是一个影响性能的关键因素。本文主要分析了几种常见的内存图结构,及其时间、空间复杂度,希望对你有所启发。
通常来说,对于图结构的几种常见的基础操作:
- 插入一个点
- 插入一个边
- 删除一个边
- 删除一个点的全部邻边
- 找到一个点的全部邻边
- 找到一个点的另一个邻点
- 全图扫描
- 获取一个点的入度或者出度
这些图相关的操作,除了要关心时间复杂度之外,需要考虑空间占用的问题。
对于大多数实时读写型的系统,增删改查的性能问题会比较重要,它们比较关注上面 1-6 的操作;对于部分密集计算的系统,对批量读取的性能会比较重视,侧重上面 5-8 的操作。
不过遗憾的是,无论是常规的图查询,还是进阶的图计算,根据 RUM 猜想[1],读快、写快、又省空间这样”既要又要也要”的好事是不存在的。
下面,我们介绍几个数据结构并给出少量的定量分析。
我们先从三个典型的方案(邻接矩阵、压缩稀疏矩阵和邻接表)说起,再介绍几种近几年的研究的变种结构 PCSR、VCSR、CSR++。
邻接矩阵 Adjacency Matrix
用矩阵来表示图结构是大学里数据结构课程中都学过的知识,也是一种非常直观的办法。
点 i 与点 j 之间有一条边,等价对应于矩阵上 $M_{ij}$ 为 1。当然,这里的点 ID 是需要连续排列无空洞。
用矩阵来表示图结构有明显的好处,可以复用大量线性代数的研究成果:比如图上模式匹配类的问题等价于矩阵的相乘。
下面是一个模式匹配问题,它的大体意思是在全图上寻找这样一种图结构:
Match (src)-[friend * 2..4]->(fof)
WHERE src.age > 30
RETURN fof
对于这样一个问题可以直接对应右边的矩阵操作:

比如,2 跳遍历等价于矩阵 F 自乘;2 - 4 跳遍历分别等价于 F^2、F^3、F^4;取属性等价于乘以一个过滤矩阵。


更进一步,由于矩阵操作是天生可以分块并行加速,这在性能上有极大的优势。
下面,我们对邻接矩阵操作进行一个简单的定量分析
| 操作 | 时间复杂度 | 备注 |
|---|---|---|
| 插入一个点 | O(n^2) | 对于矩阵来说,增加一个点意味着整个矩阵的维度增加,通常需要另外开辟一块空间 |
| 插入一个边 | O(1) | 增加一个边只是将对应的位置置 1 |
| 删除一个边 | O(1) | 置0 |
| 删除一个点的全部邻边 | O(n) | 对于某个点所有出边的删除对应某一行的置0。入边对应某一列,可以批量操作 |
| 找到一个点的全部邻边 | O(n) | |
| 找到一个点的给定邻点 | O(1) | |
| 全图扫描 | O(n^2) |
其中,n=|V|,m=|E|。
优化上,批量操作(CPU Cache/SSD block)可以线性增加性能,例如 O(n) 可以降低到 O(n/B),但不影响定量分析。
由于绝大多数图结构是极其稀疏的,因此简单用邻接矩阵来表示图结构,其内存会有夸张的浪费。更为严重的是,当有多种边类型时,每种边类型各需要一个邻接矩阵。这使得裸用矩阵在实际情况中只能处理很小数据量的场景。当然,对于现代服务器动辄几百 G 的内存,如果只有几亿点边的数据量,像是 twitter2010,这并不会是很严重的问题。但大多数情况下,条件允许的话,大家还是希望找到一些更加经济的结构。
压缩稀疏矩阵 CSR/CSC
压缩稀疏矩阵是一种非常流行和紧凑的图结构表示方式,大多数图计算系统都采用 CSR。
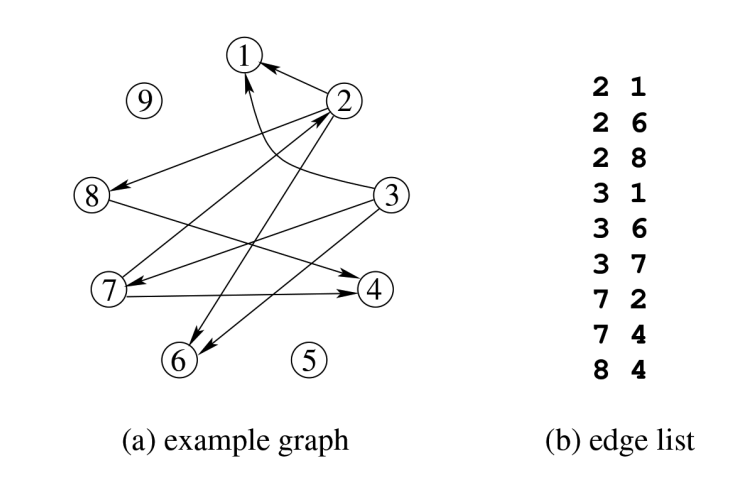
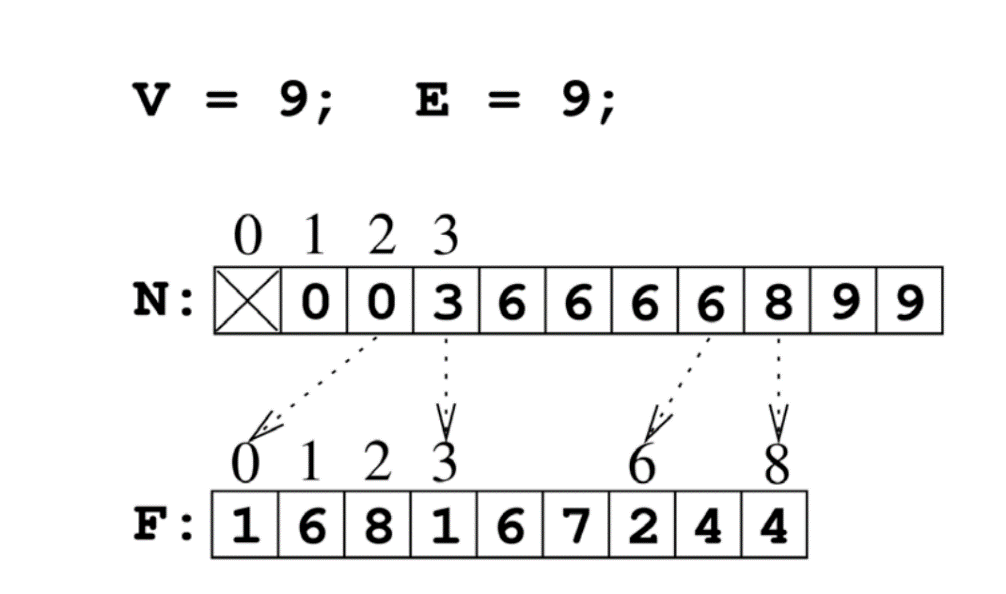
这里简单介绍一下 CSR 的结构:
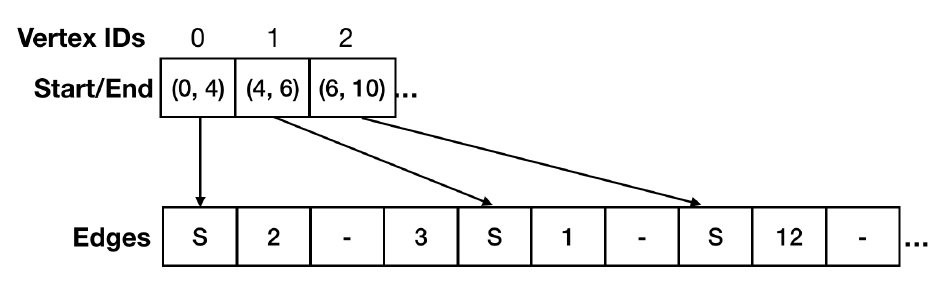
对于点 IDx,取邻居 ID 就是 F[N[x]] 到 F[N[x+1]-1]。
例如,查找点 ID2 的邻居,对应为 F[N[2]] 到 F[N[2+1]-1],对应到上图也即 1 6 8。查找点 ID7 的邻居,对应为 F[N[7]] 到 F[N[7+1]-1],也就是 2 和 4。
另外,CSR 记录的仅是出边的信息,如果要考虑入边就使用 CSC,其原理是类似的。
| 操作 | 时间复杂度 | 备注 |
|---|---|---|
| 插入一个点 | O(1) | 在点矢量尾部增加 |
| 插入一个边 <u,v> | O(m+n) | 边矢量,从 u 对应的邻居开始,都向后移动一位;点矢量,从 u 对应位置开始每个值加 1 |
| 删除一个边 | O(m+n) | 插入边的逆过程 |
| 删除一个点 v 的全部邻边 | O(m+n) | 边矢量移动 deg(v) 位,点矢量 u 对应位置置 0 |
| 找到一个点的全部邻边 | O(deg(v)) | |
| 找到一个点的给定邻点 | O(log(deg(v))) | deg(v) 内的排序查找 |
| 全图扫描 | O(m+n) |
CSR 的空间占用是 O(|V|+|E|),在空间节省和顺序查找上是极其高效的。但在大量插入时,压缩稀疏矩阵和邻接矩阵一样,需要重新开辟空间,效率很低。所以,它适合于计算密集场景但不适合增改频繁的场景。
CSR 还有一个显著的优点是可以快速获取每个点的出入度,只要计算 N[x+1]-N[x],这在判断一些点是否为超级节点时很方便。如果不是稀疏矩阵的话,通常会用另外一个单独的结构来记录出入度。
此外,CSR 不容易实现并发修改,其每次插入都需要对两个矢量进行位移,这并不高效。
这里推荐两个相关的开源项目,可以进一步了解下 CSR 的使用:
邻接链表 Adjacency List
和基于矩阵的方式不同,邻接链表 AL 空间上有优势,但对于边的读写上会略微慢一点(指针在内存中不能连续移动)。AL 的做法是把邻边(出边)用 list 或者有序 list 的方式串连起来。由此延伸的一个变种是邻边从 list 改为 array。
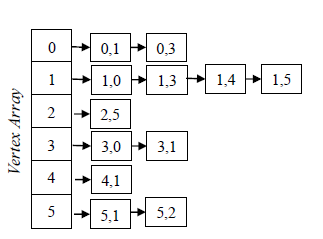
| 操作 | 时间复杂度 | 备注 |
|---|---|---|
| 插入一个点 | O(1) | 尾插入 |
| 插入一个边 <u,v> | O(log(deg(u))) | 有序 list |
| 删除一个边 | O(log(deg(u))) | |
| 删除一个点 v 的全部邻边 | O(1) | |
| 找到一个点的全部邻边 | O(deg(u)) | |
| 找到一个点的给定邻点 | O(log(deg(u))) | |
| 全图扫描 | O(n+m) |
AL 相比 CSR 通常不能直接获得点的出入度,可以通过可以单独维护一个字段实现该功能。
此外,邻接表并不需要 ID 连续排布,对于频繁增删点的场景特别友好。AL 对于并发修改的支持也更友好,天然在点级别有并行度。当然,对于超级节点,直接用 list 的方式,还是会有些性能的问题要考虑;优化上可能会进一步改造成 Blocked list 的方式,可以带来更好的数据局部性和细颗粒度。
由于 ID 不用严格连续排布,AL 的一个常见变种就是 Tree。
Tree
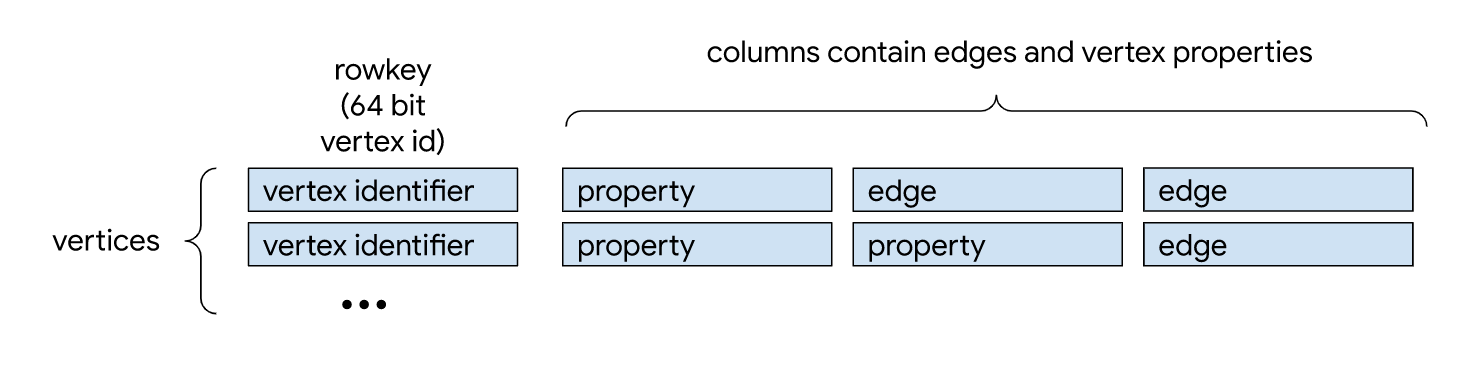
在这种结构中,一个点和其所有的邻边被建模成了 key-value,key 是点 ID,value 是所有邻边的编码。Key 通过 Tree 的方式组织在一起。这里的树可以是 B-Tree 等各变种 Tree。虽然本文没有讨论图属性,但 value 中也是可以存放 value。
| 操作 | 时间复杂度 | 备注 |
|---|---|---|
| 插入一个点 | O(log(n)) | |
| 插入一个边 <u,v> | O(deg(u) log(n)) | |
| 删除一个边 | O(deg(u) log(n)) | |
| 删除一个点 v 的全部邻边 | O(log(n)) | |
| 找到一个点的全部邻边 | O(deg(u) log(n)) | |
| 找到一个点的给定邻点 | O(log(n deg(u)) | |
| 全图扫描 | O(n+m) |
为了控制访问颗粒度,每个叶子通常会被限定为固定的大小(页)。这就是在数据库类系统里面最常见的办法 B-tree。为了增改方便,也可以把每页的 in-place update 改成 Copy-On-Write 的方式;一个典型的代表就是 LLAMA[2],但这种多版本的读取通常会需要更多的空间,并且当有大量累积修改时,需要定期的多版本合并以降低跨快照读。某种程度上,它和 LSM-Tree 的思路有些接近。
基于 CSR 的变种 PCSR 和 VCSR
由于 CSR 在空间和读性能上有很大的优势,但在插入时的耗时和空间上都很弱,因此本节几个变种的主要目的都是为了改善其弱项,大体思路都是分块和 buffer。
在 CSR 的边矢量进行增删时可以注意到,主要耗时是在对于矢量的元素位移上。因此,一个直观的思路是预留一些插入空白位,在删除时也不立刻回收这些空白。
而分块思想,是指将一些局部数据放在同一个分块内,例如 Tree 中每个 page 就是一种分块的方式。与此对应的是,buffer 空白之间的连续区域。
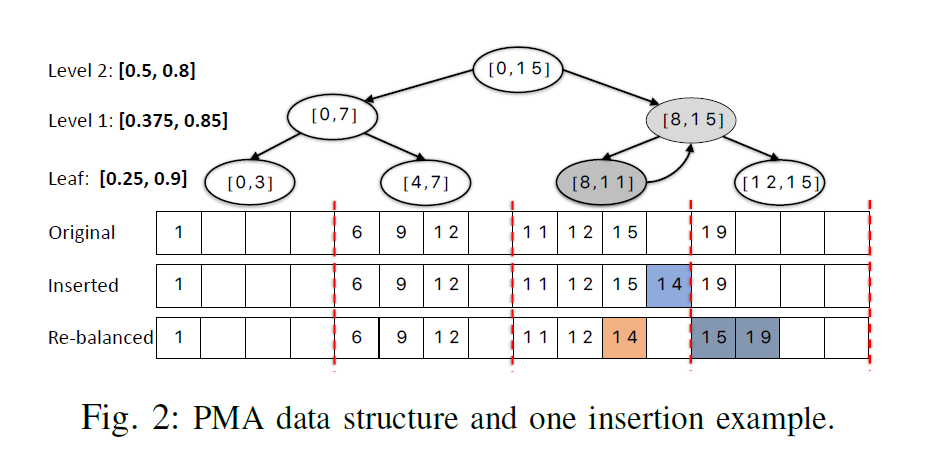
PCSR
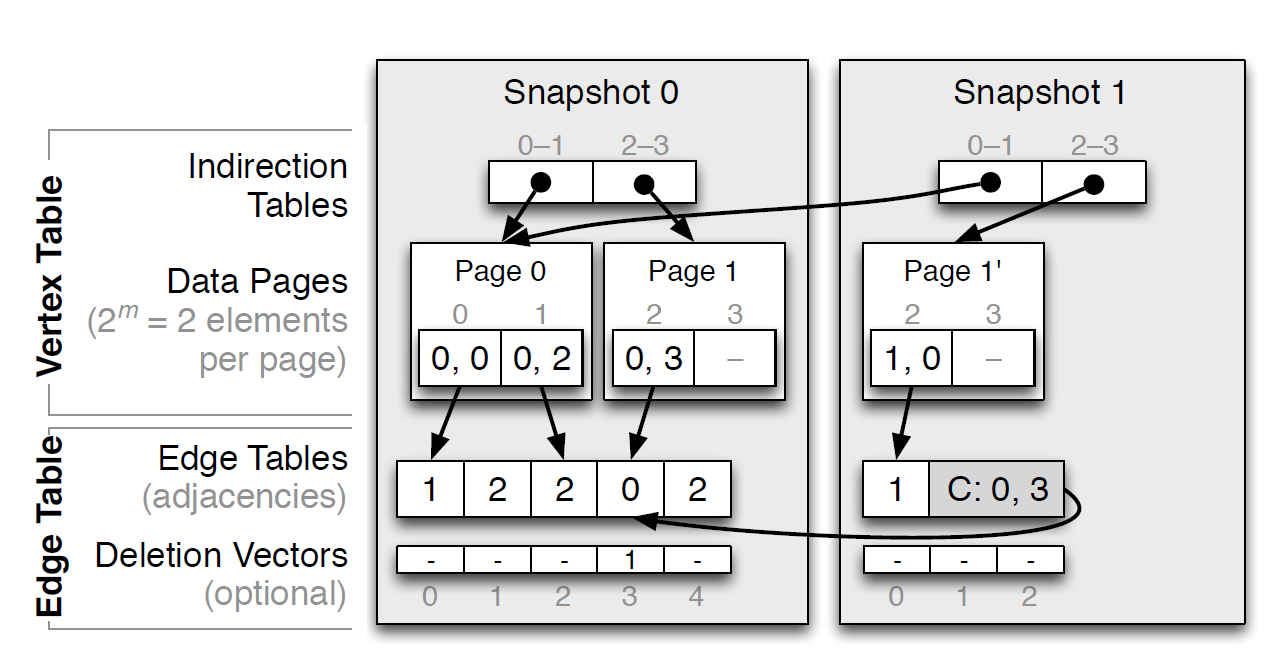
PCSR [3]的基本思想是:对于点矢量,其元素从一个值改为对应边矢量中对应邻边位置的 <起点,终点>。而对于边矢量,在这些分块所对应边界放置哨兵 sentinel,上图中的 S,上图的 “-“ 对应预留插入位置留空。
事实上,原文中,对于边矢量,其本质是实现为一个 B-Tree,本文先简化成一个 Array。
| 操作 | 时间复杂度 | 备注 |
|---|---|---|
| 插入一个点 | O(1) | 直接在点矢量和边矢量的尾插入 |
| 插入一个边 <u,v> | O(log(deg(u)) | 边矢量对应分片的二分+空位查找 |
| 删除一个边 | O(log(deg(u)) | |
| 删除一个点v的全部邻边 | O(1) | 边矢量对应分片置空,点矢量对应 ID 位置置空 |
| 找到一个点的全部邻边 | O(deg(u)) | |
| 找到一个点的给定邻点 | O(log(deg(u)) | |
| 全图扫描 | O(n+m) |
可以看到,PCSR 的预留位置多少都是需要重平衡,不能过多也不能不足。特别是大批量增删时,对预留位置的处理会是一个较重的操作。
此外,如果把 PMA 的 B-Tree 以及需要 rebalance 的本质考虑进去,其和前述 Tree 方式的区别并不是很大。
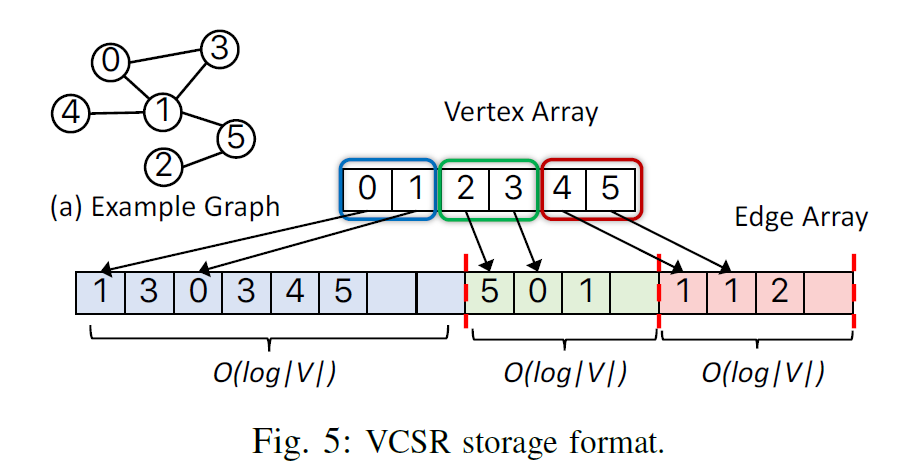
VCSR
VCSR[4]主要是对 PCSR 的一个改进,其朴素思想是 PCSR 的留空是均匀的,而大多数图结构的出入度,是存在 20-80 这样的幂率特征,而 PCSR 的一个主要痛点是频繁的 rebalance。VCSR 的做法是为每个分块预留空间正比于其分块内的点的数量,即:边矢量中,一个分块内,如果点的数量多,就多预留一些空位。在直觉上,点数量多时,其分块对应的边插入会更多一些,这样可以减少 rebalance 的频率。
此外,VCSR 还有些版本号之类的优化。
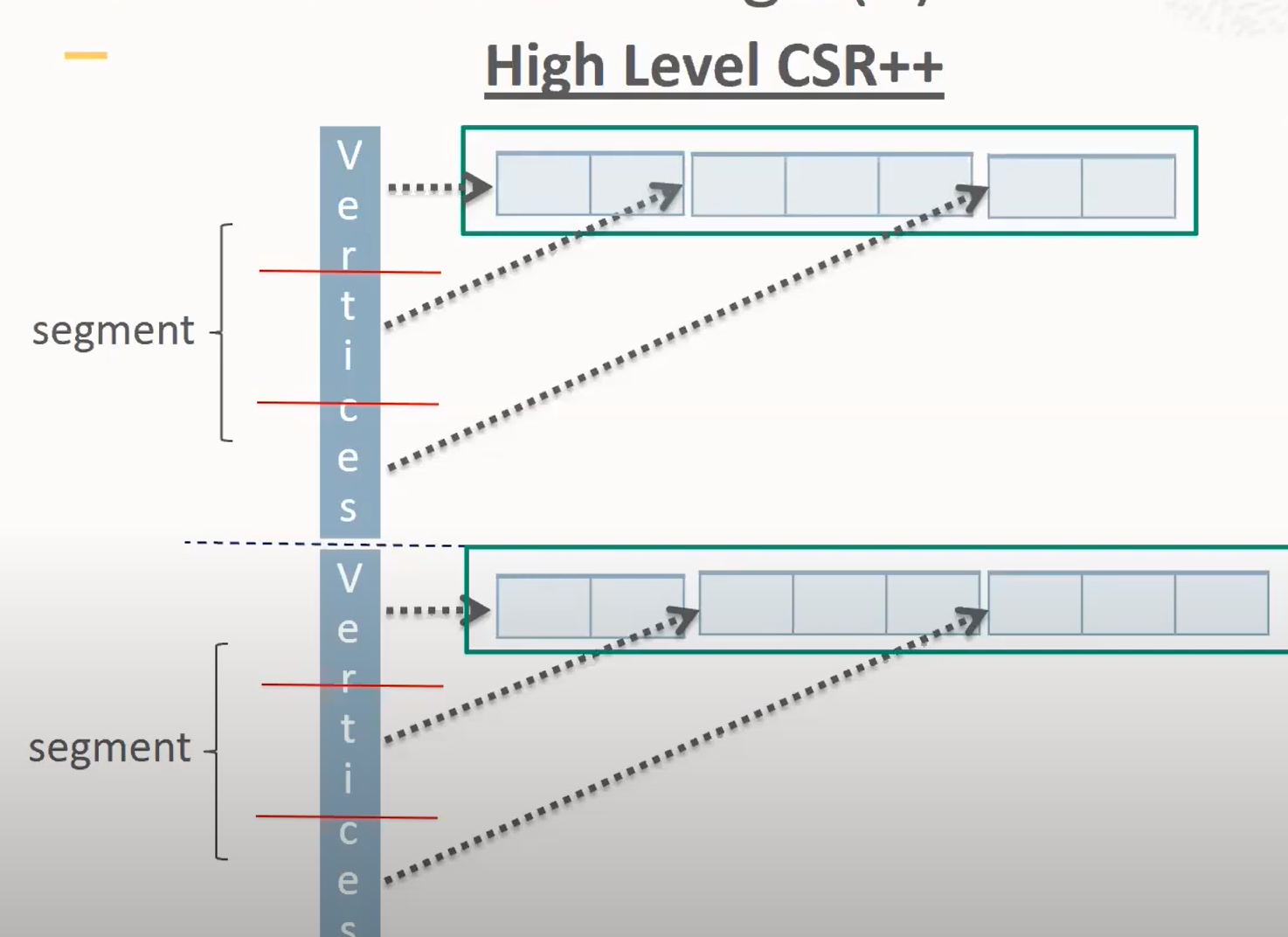
CSR++
事实上,CSR++[5]在设计上其实更接近一种 AL/Tree 的变种,而不是 CSR。它主要有三个方面的优化:
第一,对于 Vertex Array 再分段,将一个大的 Array 拆成多段,这样可以有更细的读写颗粒度。通过 段 ID + 点 ID 来定位每个点和其邻边。
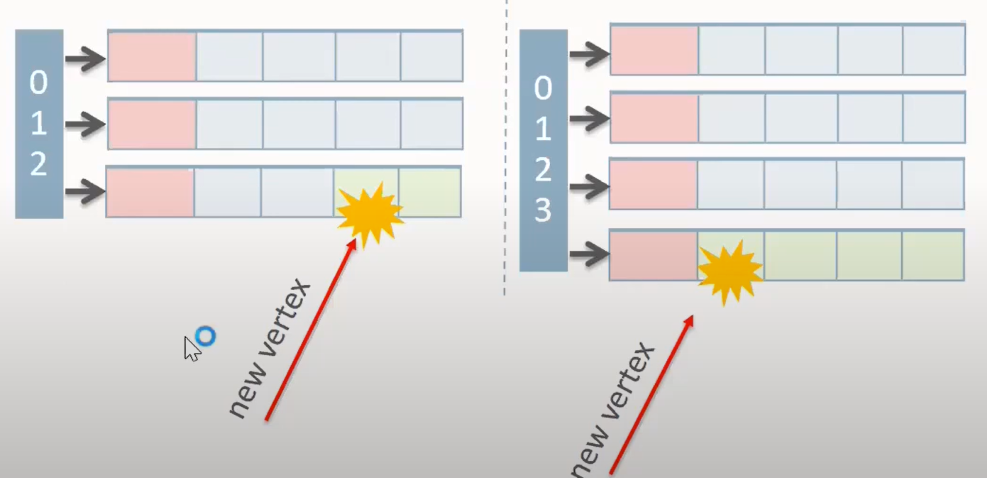
第二,Vertex Array 中每个元素,除了记录点 ID 之外,对于邻边数量很少的点,直接把邻居 ID 也对齐地塞 inline 进去。
![]()
对于大多数的点,其邻边就不需要单独的 Edge Array 来存储了。

可以看到这种方式在图比较稀疏的时候,对于 CPU Cache 扫描是很友好的。
第三,对于每个点的邻边,采用copy-on-write、标记删除等常见的优化办法,构建成类似 std::vector 结构。
小结
最后,由于在图查询、图存储和图计算不同场景下,对于图结构的读写扫描和生命周期都有些不同的要求,不同的数据结构也有不同的优劣。
当然,本文只是讨论了图结构可以放在内存中的情况。当不得不把部分数据放在硬盘上时,问题就完全不同了。当然本文也没有讨论不同 CPU 对于不同距离内存的性能差异 NUMA,或者跨进程通信带来的影响。
延伸阅读
最后,我们来了解下在图计算/图算法上的图操作。
图算法中的图操作
在图计算中,存在多种图结构算法,可能会涉及多种基础操作。
中心性 Centrality Algorithms,一种衡量一个节点在整个网络图中所在中心程度的算法,包括:度中心性、接近中心性、介数中心性等,会涉及“找到一个点的全部邻边”、“找到一个点的另一个邻点”、“全图扫描”的操作组合。
- 度中心性通过节点的度数,即关联的边数来刻画节点的受欢迎程度,这将会要求找到一个点的所有邻边。
- 接近中心性,通过计算每个节点到全图其他所有节点的路径和来刻画节点与其他所有节点的关系密切程度,这将会要求进行全图扫描,查找点和图中所有点的路径信息。
- 介数中心性,则用于衡量一个顶点出现在其他任意两个顶点对之间最短路径上的次数,从而来刻画节点的重要性,这将会要求进行全图扫描,找到一个点和它的邻点及路径信息
PageRank,又称网页排名、谷歌左侧排名,是一种由搜索引擎根据网页之间相互的超链接计算的技术作为网页排名的要素之一的排名方法。它以 Google 公司创办人拉里·佩奇 Larry Page 之姓来命名。Google 用它来体现网页的相关性和重要性,在搜索引擎优化操作中是经常被用来评估网页优化的成效因素之一。一般来说,PageRank 的值越高,表示其被很多其他网页链接到,说明它的重要性很高;而如果一个 PageRank 很高的网页链接到其他网页,被链接的网页的 PageRank值也会随之提高。PageRank 的计算过程如下:
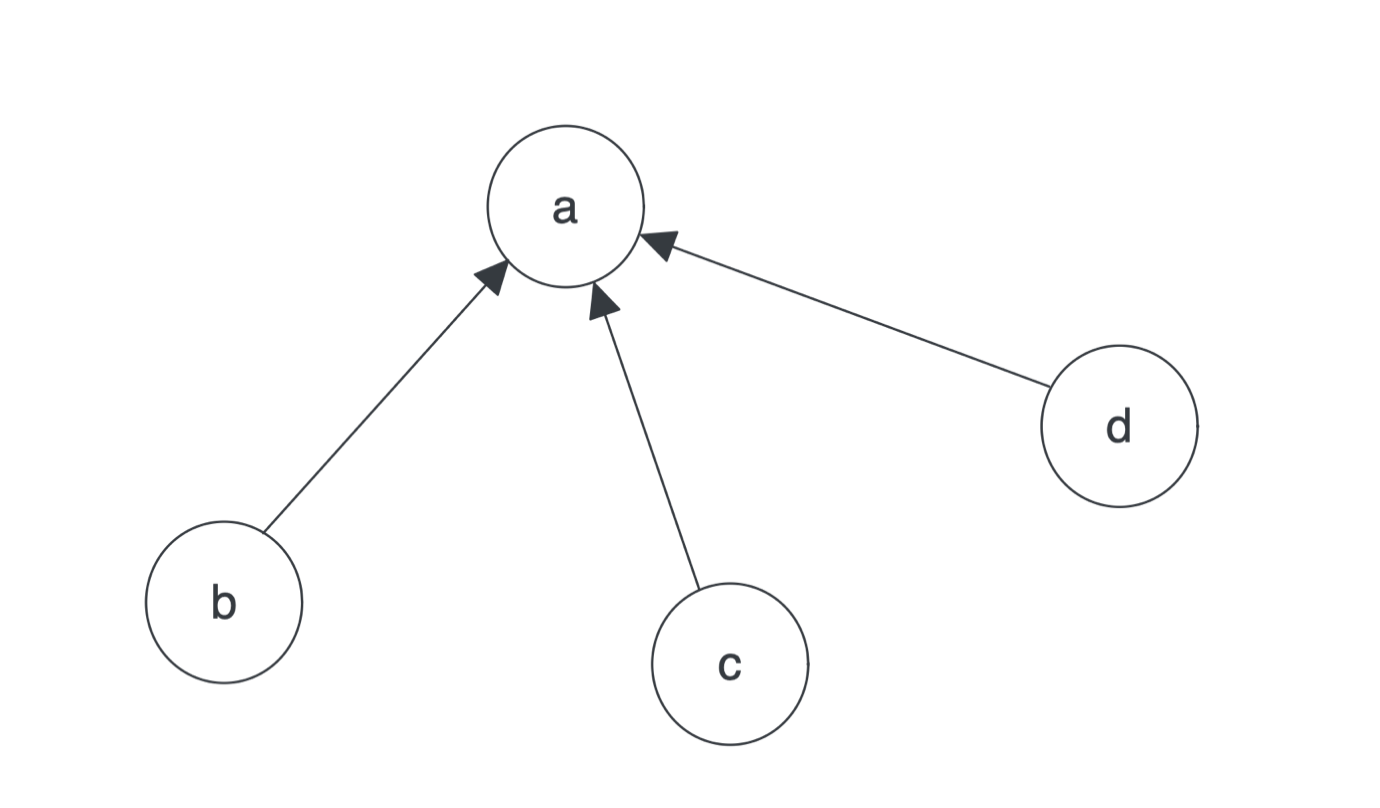
假设由 4 个网页组成的集合:A、B、C、D,每个页面的初始 PageRank 值相同,为了满足概率值为 0-1 之间,假设这个值为 0.25。
如果所有页面都只链接至 A,如下图,则 A 点的值将是 B、C、D 的 PageRank 值的和。
倘若是下图这种图结构:
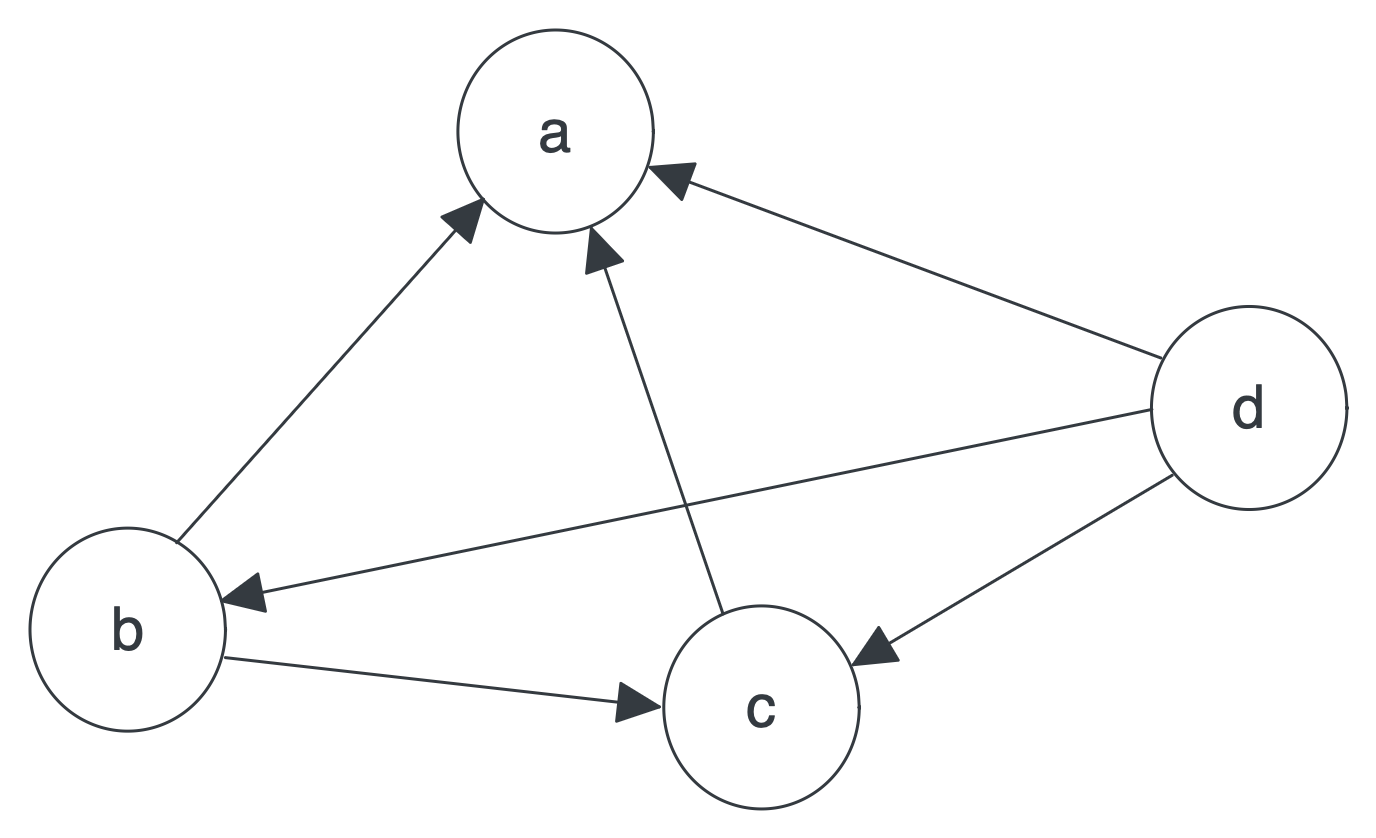
B 链接到 C,D 链接到 B 和 C,A 点的值计算的方式如下:

这里的 2、1、3,分别是 B 点对外链接的 2 条边,C 点对外链接的 1 条边,D 点对外链接的 3 条边。
换句话说,算法将根据每个页面连出总数平分该页面的 PR 值,并将其加到其所指向的页面:
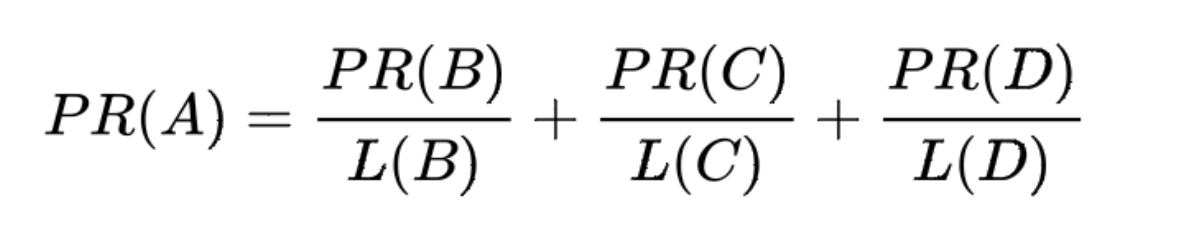
最后,所有这些 PR 值被换算成百分比形式再乘上一个修正系数。
由于“没有向外链接的网页”传递出去的 PR 值会是0,这时候如果递归的话,会导致指向它的页面的 PR 值的计算结果同样为零,所以 PageRank 会赋给每个页面一个最小值。
因此,一个页面的 PR 值直接取决于指向它的的页面。如果在最初给每个网页一个随机且非零的 PR 值,经过重复计算,这些页面的 PR 值会趋向于某个定值,也就是处于收敛的状态,即最终结果。
简单来说,大多数迭代图计算模型都是基于“找到一个点的全部邻边”、“找到一个点的另一个邻点”操作。
AIGC 小课堂
在 AIGC 小课堂部分,我们会用 NebulaGraph 接入的 aibot 来讲解下文中的部分概念。你如果对 chatgpt 或者是 aibot 有兴趣,可以来 https://discuss.nebula-graph.com.cn/ 向 aibot 提出你的要求。


参考文献
- Athanassoulis, M., Kester, M. S., Maas, L. M., et al. (2016). Designing Access Methods: The RUM Conjecture. In EDBT (pp. 461-466).
- Macko, P., Marathe, V. J., Margo, D. W., et al. (2015). Llama: Efficient Graph Analytics Using Large Multiversioned Arrays. In 2015 IEEE 31st International Conference on Data Engineering (pp. 363-374). IEEE.
- Wheatman, B., & Xu, H. (2018). Packed Compressed Sparse Row: A Dynamic Graph Representation. In 2018 IEEE High Performance Extreme Computing Conference (HPEC) (pp. 1-7). IEEE.
- Islam, A. A. R., Dai, D., & Cheng, D. (2022). VCSR: Mutable CSR Graph Format Using Vertex-Centric Packed Memory Array. In 2022 22nd IEEE International Symposium on Cluster, Cloud and Internet Computing (CCGrid) (pp. 71-80). IEEE.
- Firmli, S., Trigonakis, V., Lozi, J. P., et al. (2020). CSR++: A Fast, Scalable, Update-Friendly Graph Data Structure. In 24th International Conference on Principles of Distributed Systems (OPODIS’20).