在执行类似下图语句的时候,总是会宕机。 推测是oom了,在哪儿可以调大参数呢?
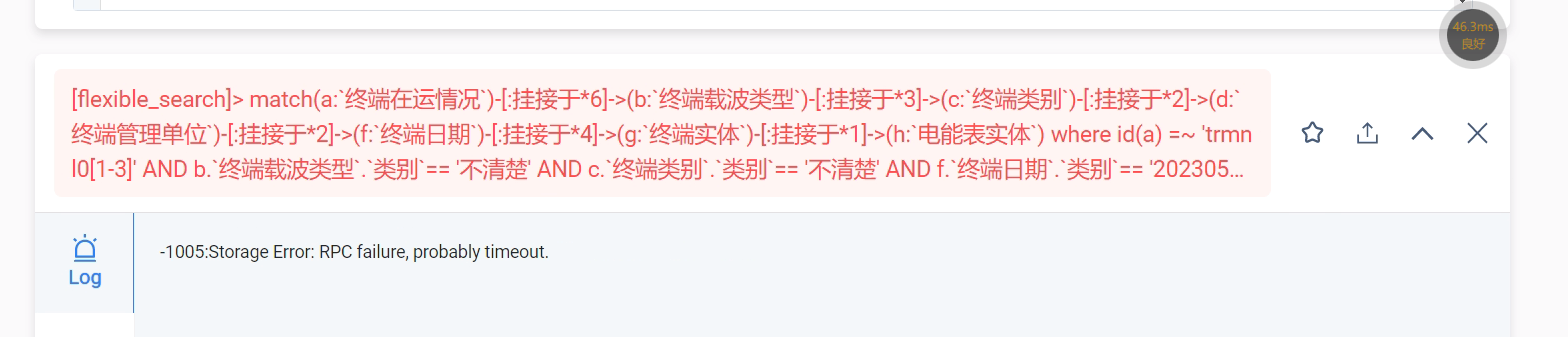
这个参数,我们这边之前就优化过了,由4MB 优化到了 32G,还是会宕机
Graphd 里的 storage client 超时时间调大了么?
目前的值是 360000 需要再调大吗
E20230506 08:45:40.934612 121455 PeekingManager.h:115] Received SSL connection on non SSL port
E20230506 08:45:40.946657 121456 PeekingManager.h:115] Received SSL connection on non SSL port
E20230506 08:45:40.951867 121457 PeekingManager.h:115] Received SSL connection on non SSL port
E20230506 08:45:40.957320 121458 PeekingManager.h:115] Received SSL connection on non SSL port
E20230506 08:45:40.959630 121459 PeekingManager.h:115] Received SSL connection on non SSL port
E20230506 08:45:40.969884 121460 PeekingManager.h:115] Received SSL connection on non SSL port
E20230506 08:45:40.984835 121461 PeekingManager.h:115] Received SSL connection on non SSL port
有什么东西在扫描 storaged 么?
此外,你这里有巨量数据传输,应该是查询有全扫描,你把 query 文本贴一下
E20230506 08:45:41.006647 121463 HeaderServerChannel.cpp:100] Received invalid request from client: apache::thrift::transport::TTransportException: Header transport frame is too large: 2157838595 (hex 0x809e0103) (transport apache::thrift::PreReceivedDataAsyncTransportWrapper, address ::ffff:26.51.227.28, port 41252)
这个query 之前查询没问题,重启后查询也没有问题
query 文本
什么意思,这个查询不是触发 storage exception 的条件?
@coder_Xing 你观察一下出这个 RPC failure 的时间点,storage、graph 上的日志是什么,贴上来。
nebula-graphd.cdh001.root.log.ERROR.20230516-093803.77250 (4.9 MB)
nebula-storaged.cdh001.root.log.ERROR.20230516-093803.77326 (1.1 KB)
昨天的报错日志,看内容报错的都是 连接失败 和 超时。
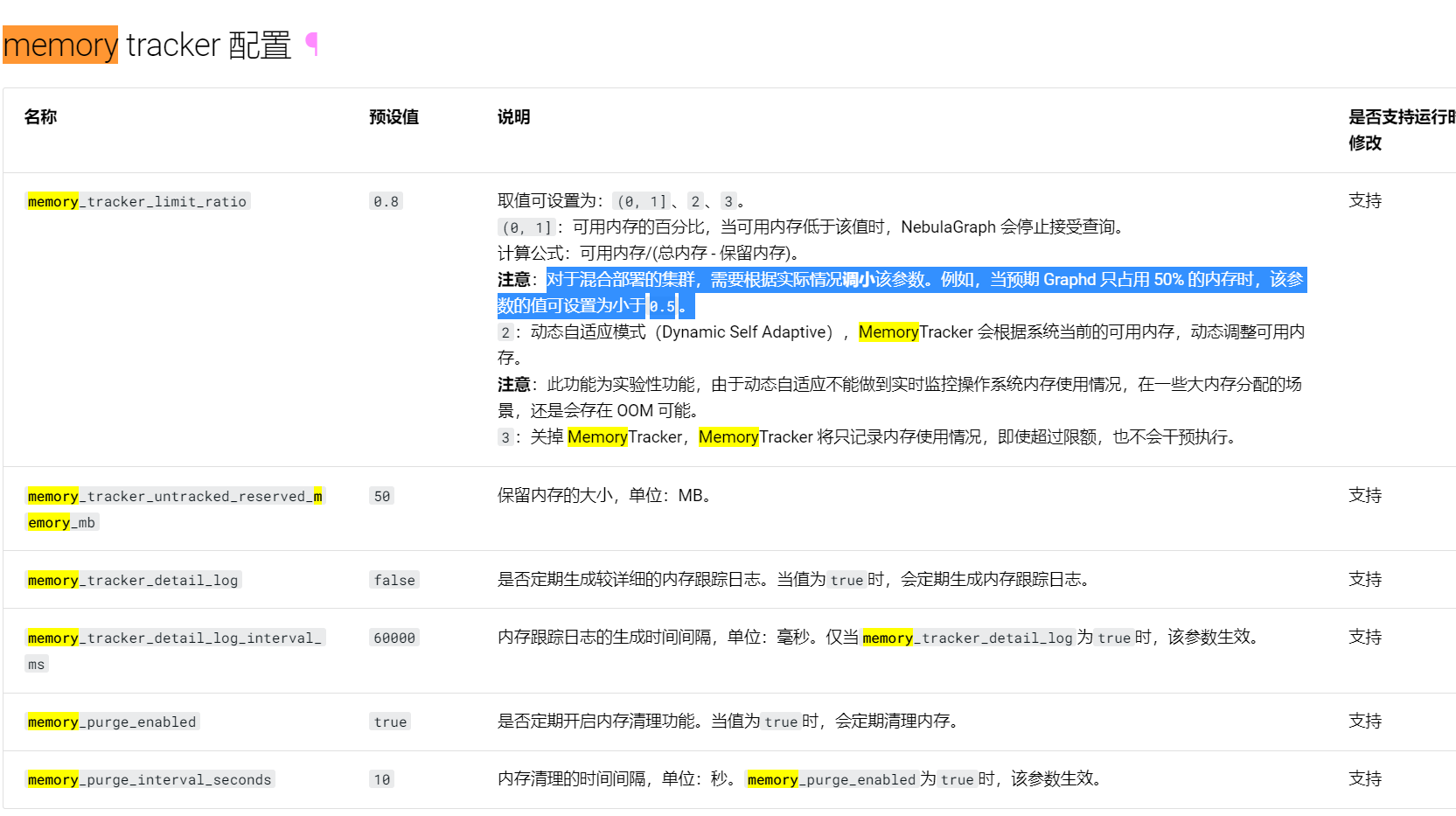
把 WHERE id(a) =~ ‘xxx’ 改成 WHERE id(a) IN [“xx0”, “xx1”] 会避免全扫描