- nebula 版本:3.4.0
- 部署方式:分布式
- 安装方式: RPM
- 是否上生产环境:Y
- 问题的具体描述
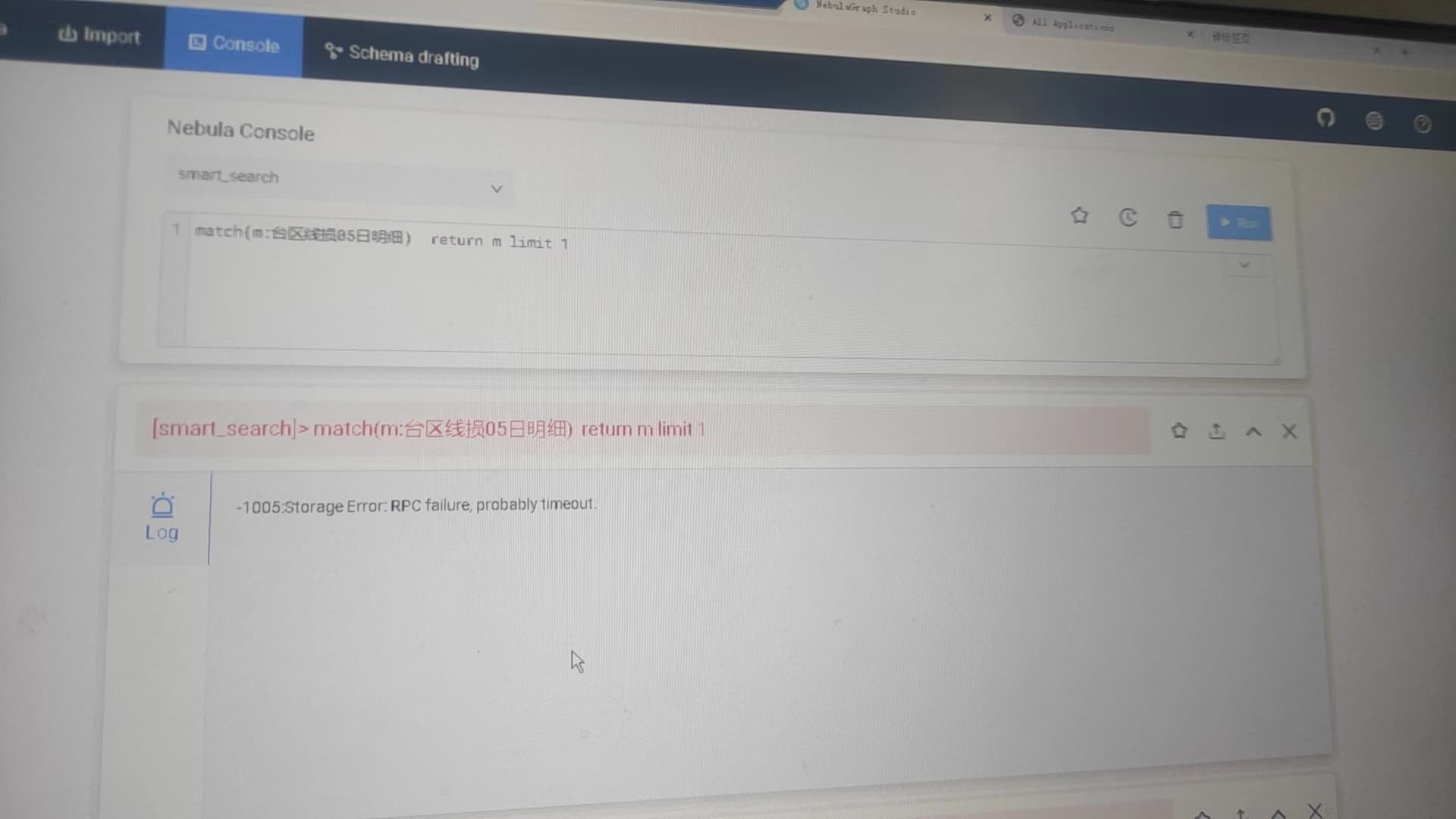
storage服务会频繁挂掉,导致查询失败。该怎么解决来避免这种问题呢?
附上 查询报错截图,报错之后show hosts 截图 以及 nebula-storaged.conf配置信息
nebula-storaged.conf (5.7 KB)

3.4 版本的话,请确认下你进行过 add hosts 操作,此外把你的语句的执行计划贴一下,explain 加在语句前面执行下就能得到执行计划。
这边进行过了 add hosts操作了;执行计划 应该和宕机没关系,nebula部署在内网,往外网传文件比较麻烦。
不,执行计划可以看到你这条语句是如何执行的,是不是走的是索引还是全盘扫数据。
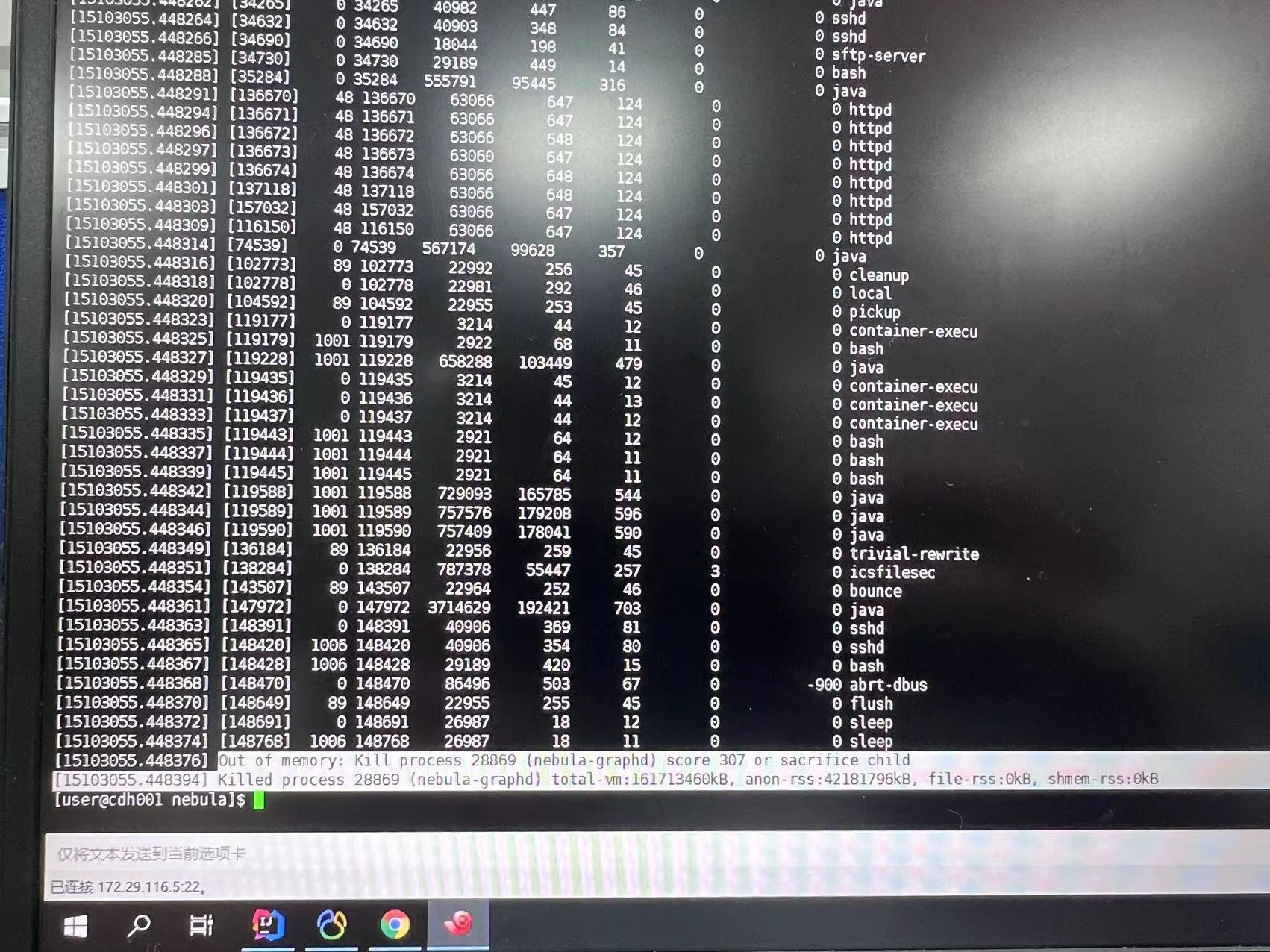
match 的limit目前没有下推到storage,看下storage的内存,dmesg看下storage是不是oom了
1 个赞
语句:
match (n:XXX) return n limit 100
执行过程:
limit → AppendVertices → IndexScan → Start
storage要是oom了之后,不会出现重启后就可以吧,目前重启后就恢复了
试试这个,加一个 id 限制看看呢?
你可以看下思为写的执行计划,用来以后进行语句调优用。
有时候业务需要全扫描查询,或者storage oom 有什么解决办法吗
你这个是kill的graph吧,不是kill的storage
请问storaged log 在哪儿看呢
从storaged log也定位不到原因。 请问storage服务的内存值在哪儿更改呢,默认是多少呢?
贴一下 log 里的信息呢,要先知道发生了什么
附上运维同事提供的日志,麻烦您帮忙看下
nebula-storaged.newcj176.root.log.ERROR.20230509-150242.254995 (133.0 KB)
nebula-storaged.newcj176.root.log.ERROR.20230306-095534.39664 (330.5 KB)
nebula-storaged.newcj176.root.log.ERROR.20230426-125213.121187 (173.3 KB)
nebula-storaged.newcj176.root.log.ERROR.20230511-180151.227366 (658 字节)
