- nebula 版本:3.4.0
- 部署方式:分布式
- 安装方式: RPM
- 是否上生产环境:Y
- 问题的具体描述
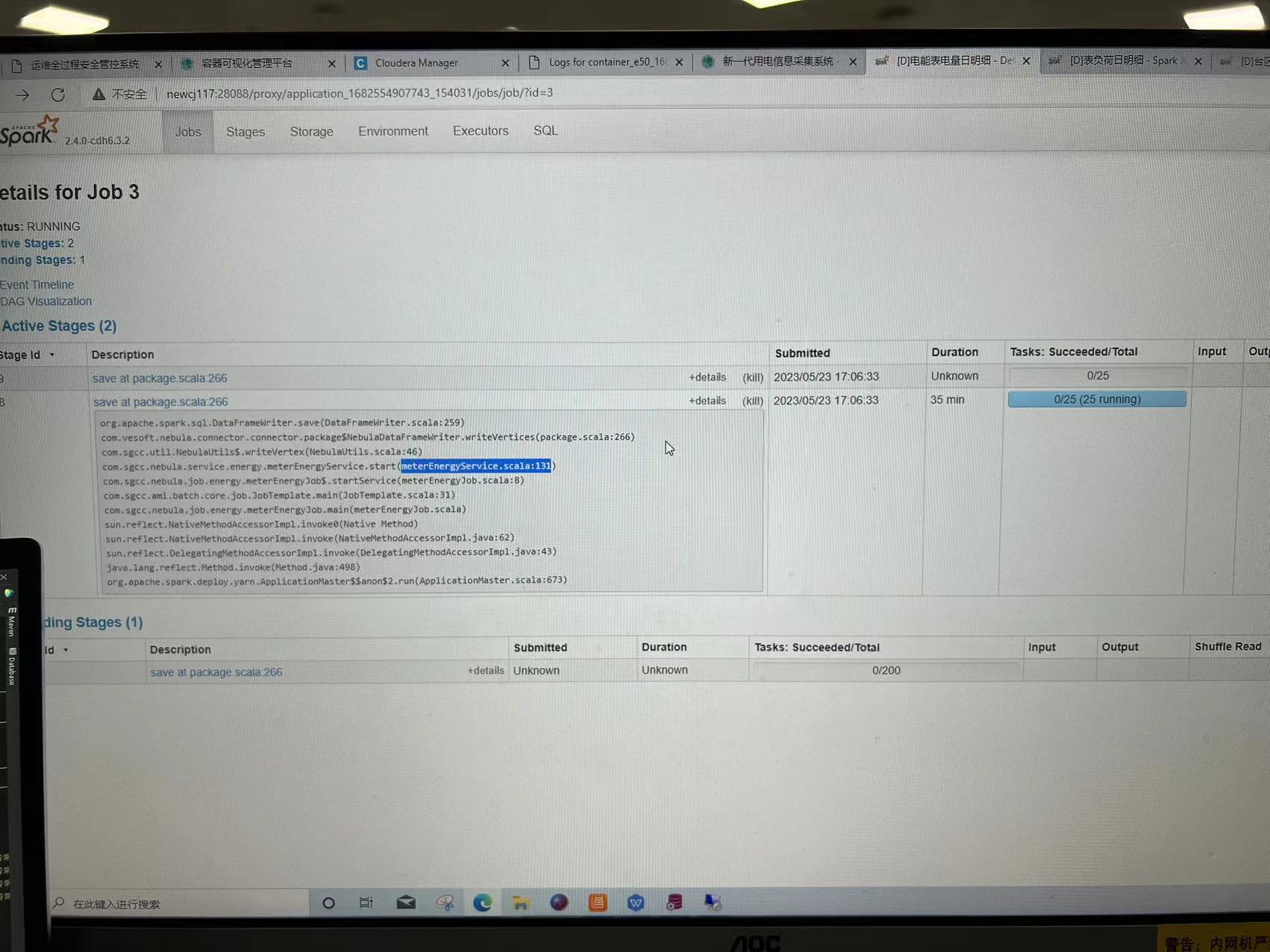
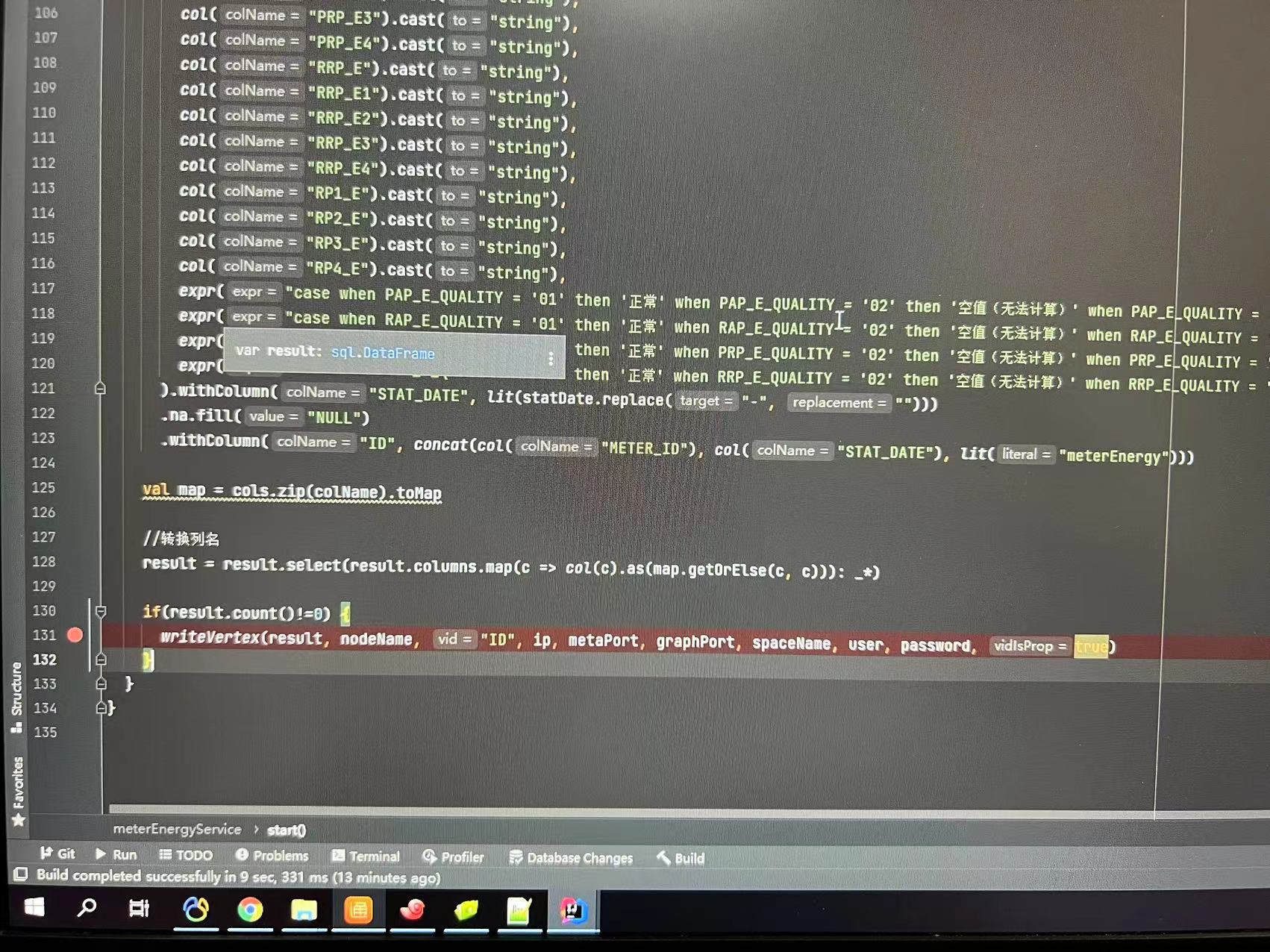
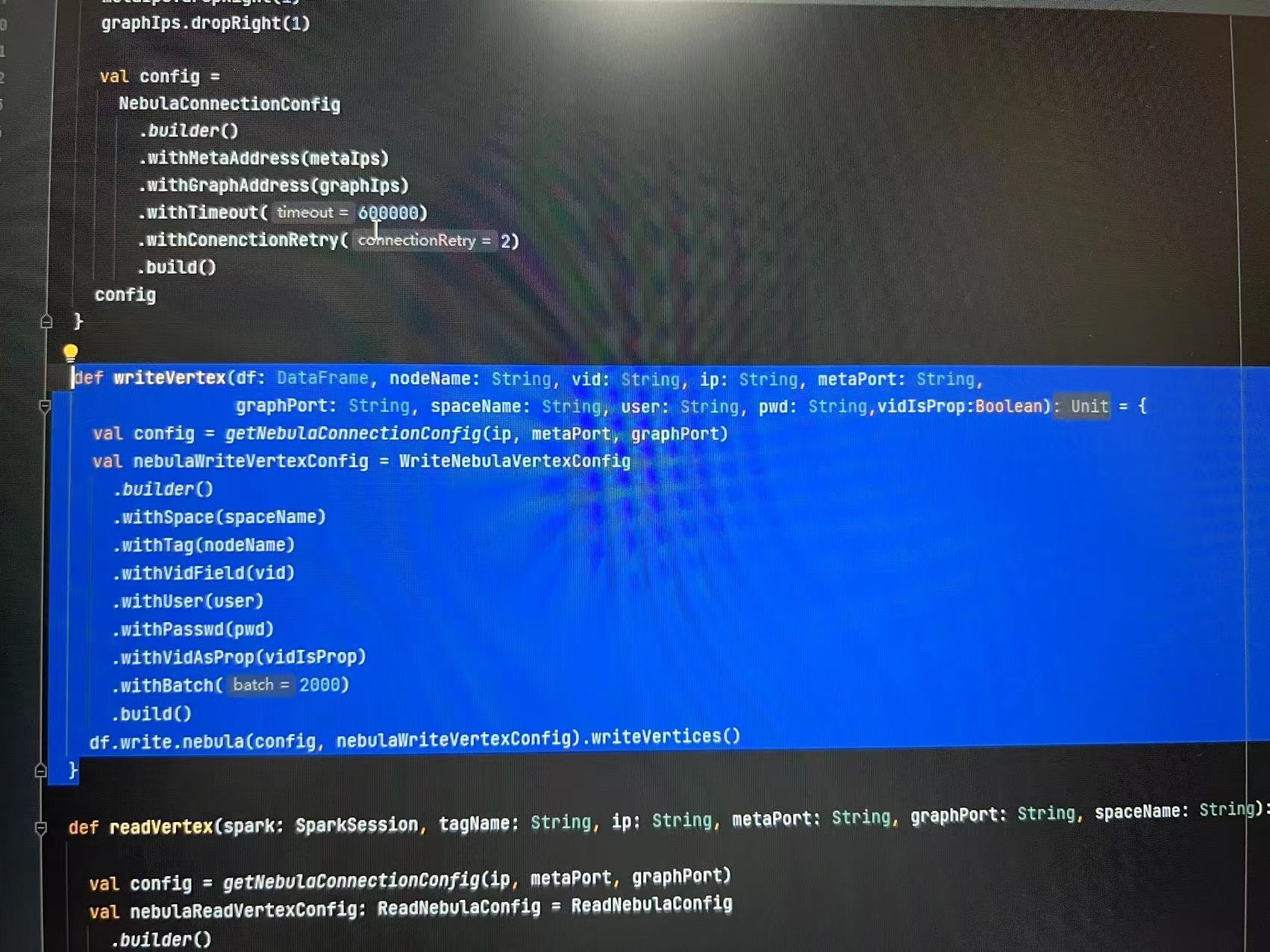
大批量数据,通过spark代码写入图数据库时,速度缓慢,截至发帖时 42分钟,进度仍然是0。 在数据量没这么大时,写入没问题,以下是运行信息和关键代码。
关闭auto_compact 试试
1 个赞
你的数据是spark从哪里读取的,看是不是数据还没读出来。
可以在写入之前对数据做一下cache和action操作
写入之前cache了,看sparkUI的界面,在 saveAt的那一行代码很慢,没有gc
将disable_auto_compaction 设置为true之后,写入速度反而会更慢
此话题已在最后回复的 30 天后被自动关闭。不再允许新回复。