king
2023 年5 月 24 日 03:29
1
语句逻辑是这样的:
发现如果边后面指定两个类型,则type(e)显示:BAD_TYPE
而我的要求类似这样的条件:
请教该如何写呢
wey
2023 年5 月 24 日 10:55
2
king
2023 年5 月 26 日 03:16
3
@wey 非常感谢大佬,完美解决!!!
另外个case需要请教,需求是这样:从a00000001出发,1~4条内任意一个t_uid节点,如果属性满足某条件就返回:
match p=(v0:t_uid)-[e:e_login_sum*1…4]-(v1:t_uid)
报了bad_type,语法上好像不对
之所以这么写是因为,如果途径大节点,全部返回或者判断,会比较耗时;
king
2023 年5 月 26 日 04:05
5
@wey 感谢,按照你给的说法改写之后,语法上是可以执行了:
match p=(v0:t_uid)-[e:e_login_sum*1…4]-(v1:t_uid)
但我还有点疑问是:1~4步内相邻的节点可能有成百上千个,我希望是遍历时:只要有一个满足立刻返回,因为将来是打算做线上实时查询的,期望耗时在20ms内;
试了多种写法,包括以下:
match p=(v0:t_uid)-[e:e_login_sum*1…4]-(v1:t_uid)
发现总体耗时都比较大,应该是查询到全部满足的v1后,再对结果进行遍历了,是否有更优解呢
wey
2023 年5 月 29 日 08:55
7
这样的查询,GO 会更快一些,不过确实没有表达能做到如果已经有结果了,就停止
king
2023 年5 月 29 日 09:03
8
king:
| LIMIT 1;
@wey
好的,所以即使是go的写法,加了limit 1,也仅是对最终结果取limit 1,
没有更优解了是吗
wey
2023 年5 月 29 日 09:17
9
确实没有了,除非拆分多个query,在应用层实现,否则现有的优化规则 LIMIT 没法做到“短路”,但是似乎不符合你的 SLO(20 ms)
理论上这个可以是非常复杂的优化的点,让 condition filter + limit 下推,提前结束,现在还没有这样的优化。
不过如果我能想到一个 mitigation 是,用 GO 的 LIMIT 限制扫过的数据量,但是不适用于 v1.column == 1 这种带条件的(因为 LIMIT SAMPLE 是无视条件的)
king
2023 年5 月 29 日 12:01
10
@wey 非常感谢,在多数情况下,没有碰到大节点时,都能满足20ms的要求,但复杂度一上来耗时就上去了;
接楼上再问一个问题,下午刚刚碰到的,觉得非常匪夷所思的问题:
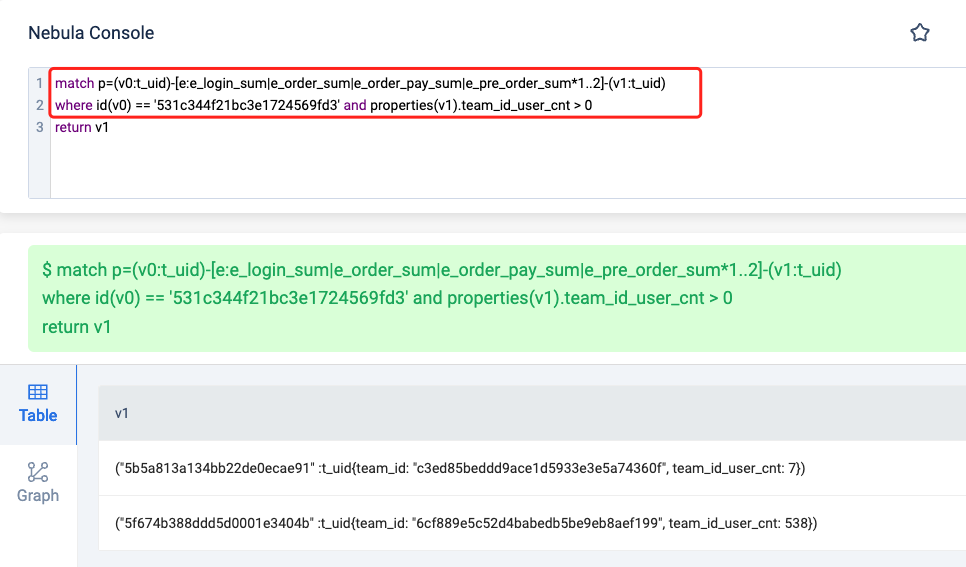
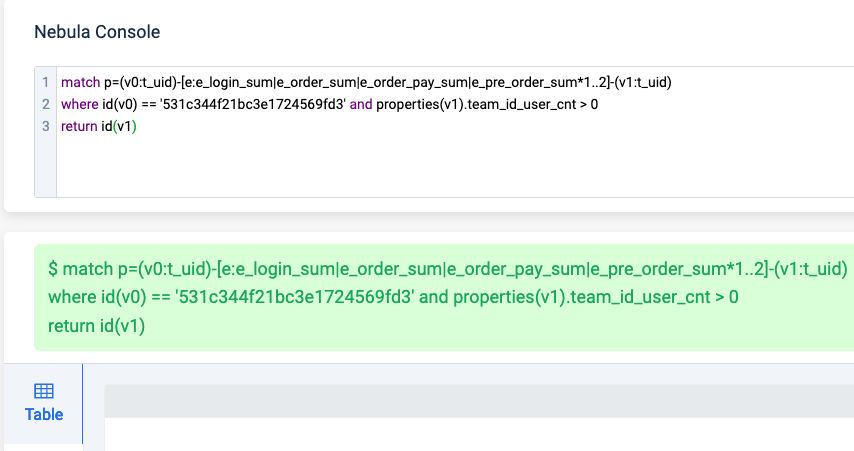
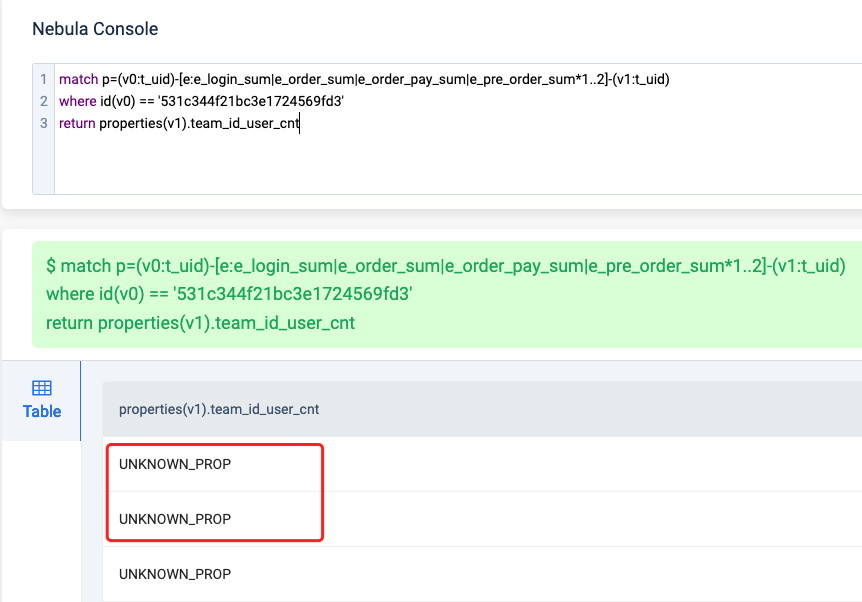
以下三个查询唯一的区别就是return后面的结果不同:当单独返回id(v1)时,居然完全没有返回结果;
而最后这个查询,直接返回了:UNKNOWN_PROP
system
2023 年6 月 28 日 12:02
11
此话题已在最后回复的 30 天后被自动关闭。不再允许新回复。