还是这个帖子上提到的问题,我输入的边数据中涉及到的点有一百多万,最终返回的结果只有4万多
你的内核和对应工具的版本号呢?
没用图数据库,计算结果返回到csv文件了,spark版本是2.4.0,scala版本是2.11.8,nebula-algorithm的版本是3.1.0
没用图数据库,计算结果返回到csv文件了,spark版本是2.4.0,scala版本是2.11.8,nebula-algorithm的版本是3.1.0
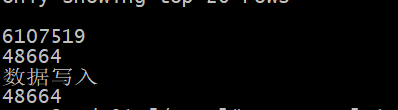
这是结果,输入了600万左右,输出了四万多,我分别试了3.0版本和3.1版本,都是这个结果
最搞笑的是,我又换了2.5版本的nebula-algorithm包跑了一下同一份数据返回的结果是这个

你的600多万输入是点还是边
600多万是边,但是点也有500多万,我在库里算过了
2.5版本的algorithm 对louvain算法的输出格式是 社区信息,返回结果是45说明有45个社区。
在2.6版本及以后版本中将 louvain算法的输出格式改成了 节点及节点所属社区, 返回结果=图中节点数量。
版本之间的差异可以看release说明 https://github.com/vesoft-inc/nebula-algorithm/releases
这也不对啊,2.5返回有45个社区,3.0和3.1返回68个社区?我输入的是同样的参数
你在库里算的点 确保所有点都在你的边数据中吗,最准确的算法是 根据边抽取源点+目的点 再去重,这才是如图的真实的点数量。
你这是拿输入的边和输出的点来对比数量
68个社区哪来的,边数据是一模一样的吗
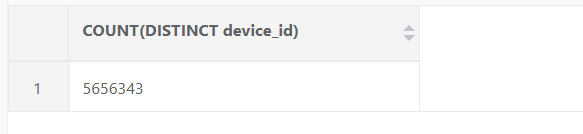
这是点的数量
一模一样的,3.0版本和3.1版本跑出的结果
不知道你咋用的,2.5和3.0 louvain算法逻辑代码没变动。
SQL我还是会写的,谢谢

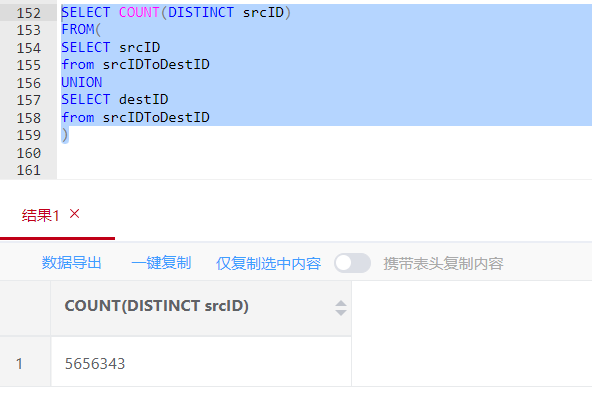
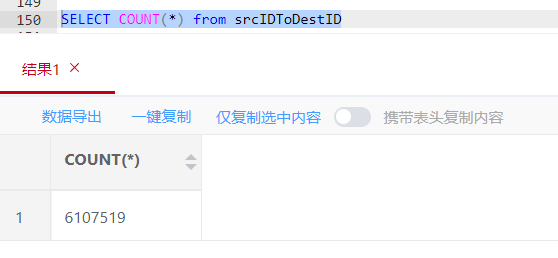
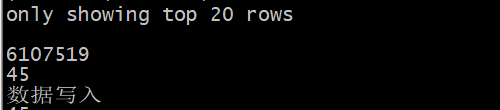
我又跑了一遍,用3.0版本跑的,

这是结果,上面那个显示的是点的数量
是这么算的
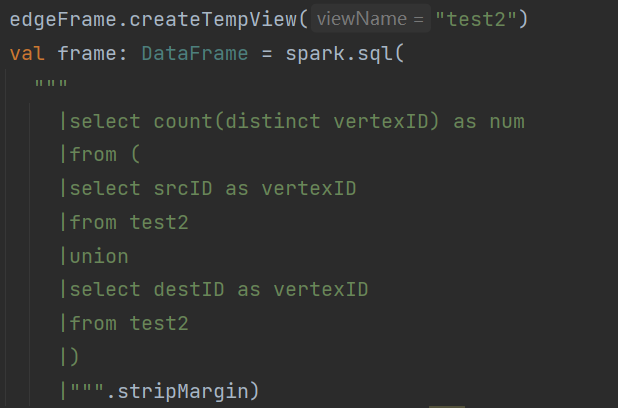
没问题吧,但是他就是只返回四万多的数据