在社区中找到过这个问题,但是现象与我的不同:
https://discuss.nebula-graph.com.cn/t/topic/6736
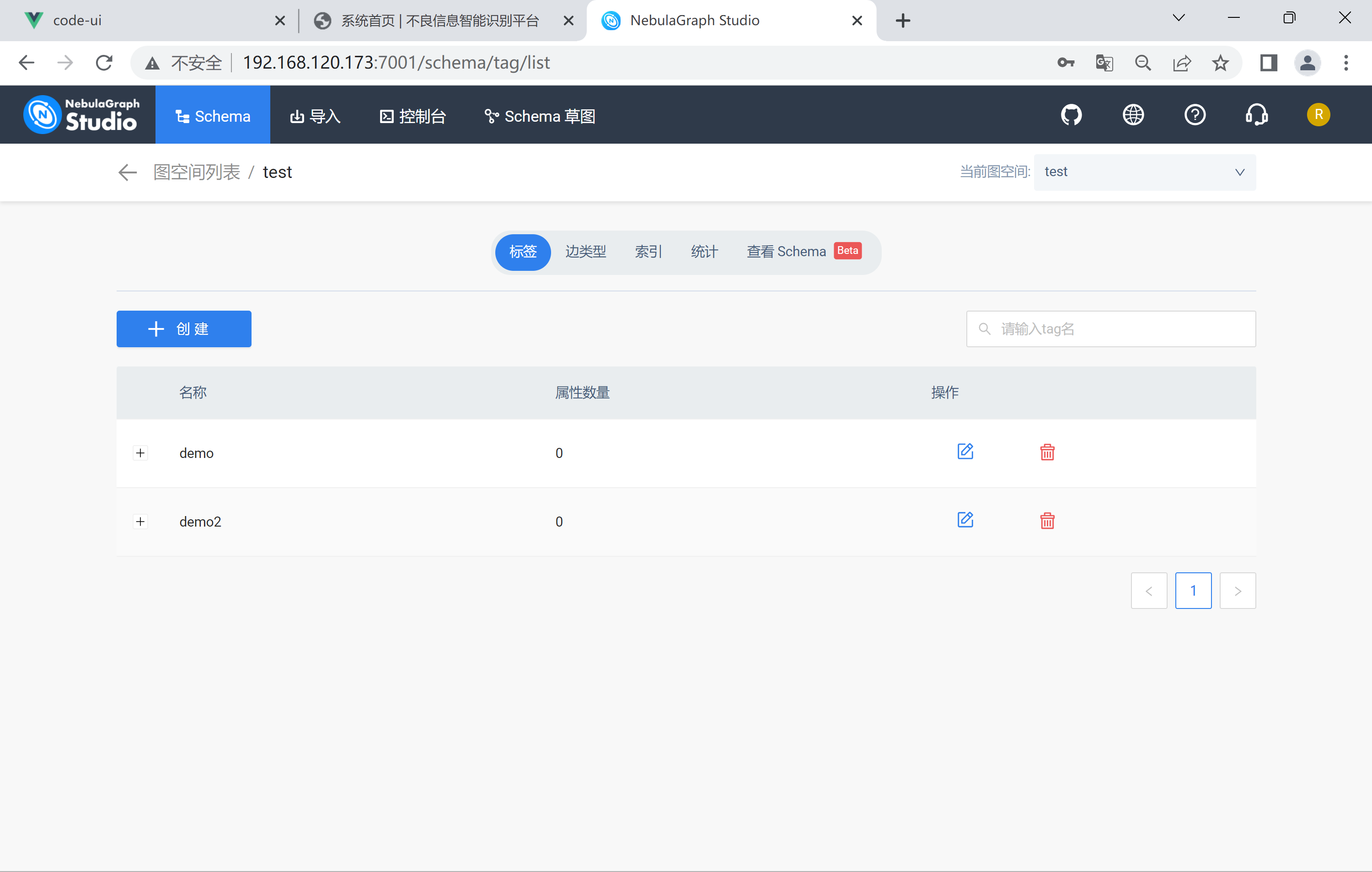
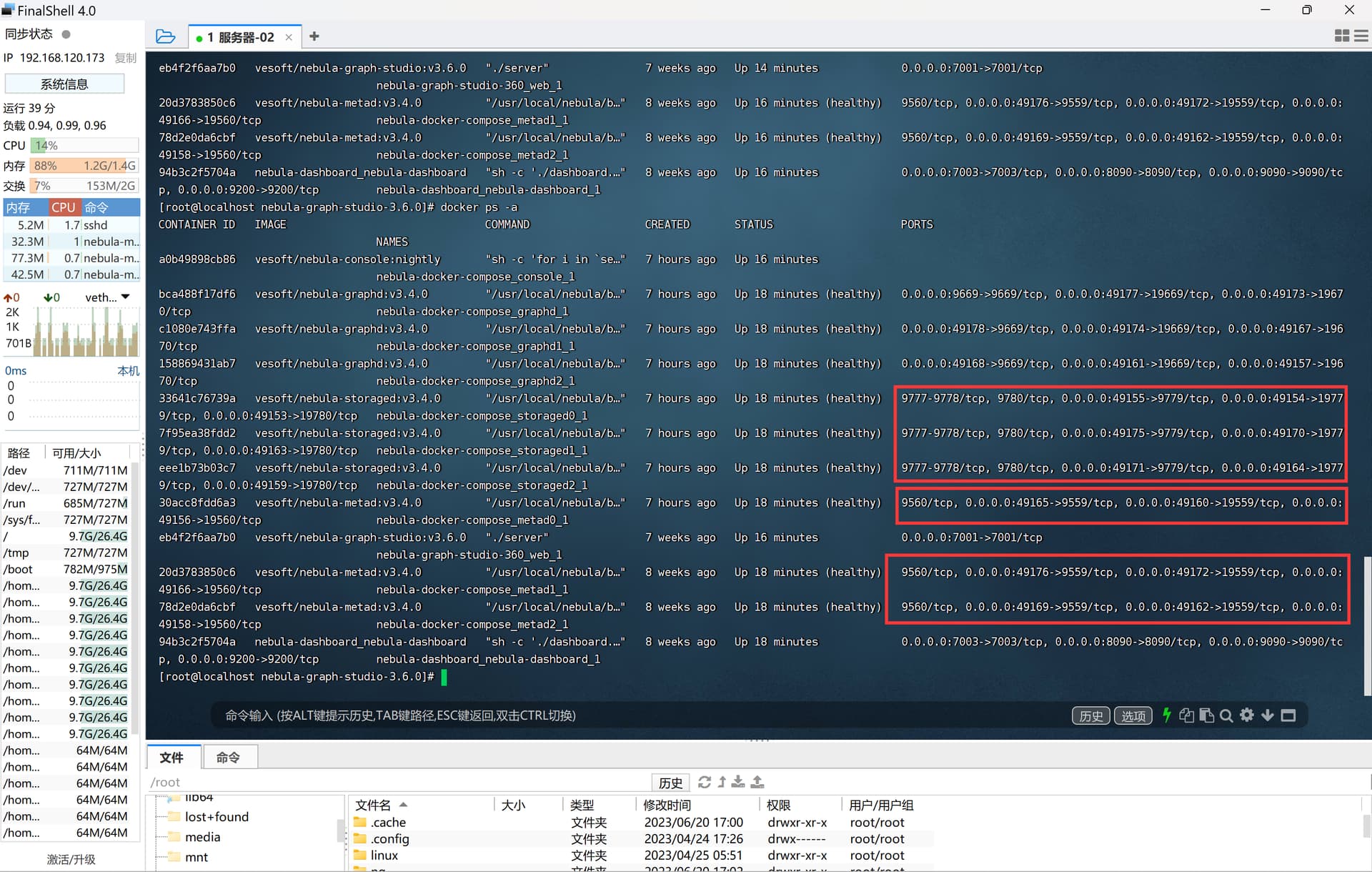
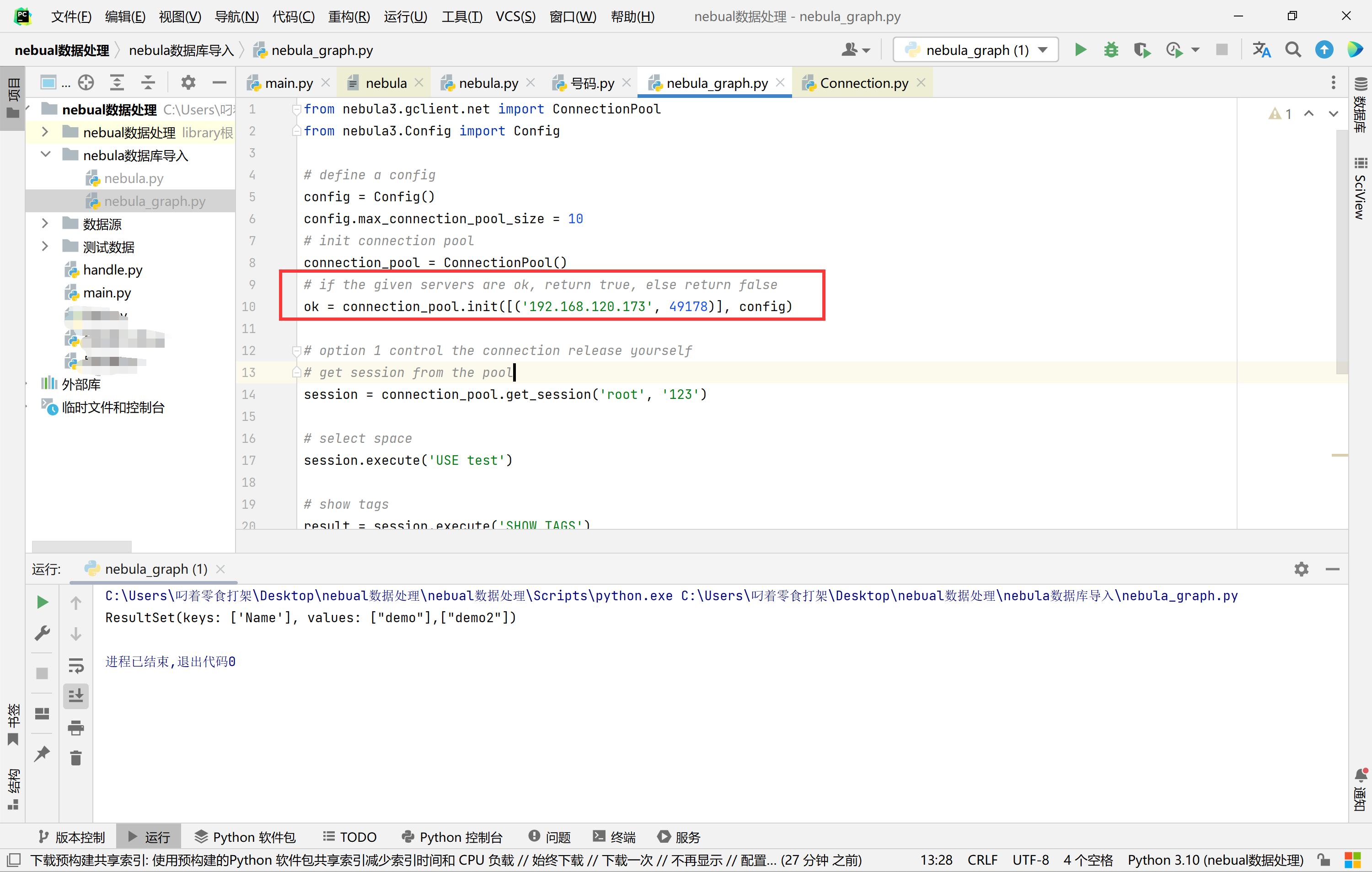
使用Python连接虚拟机上docker运行的nebula时报错,程序如下:
from nebula3.mclient import MetaCache, HostAddr
from nebula3.sclient.GraphStorageClient import GraphStorageClient
# the metad servers's address
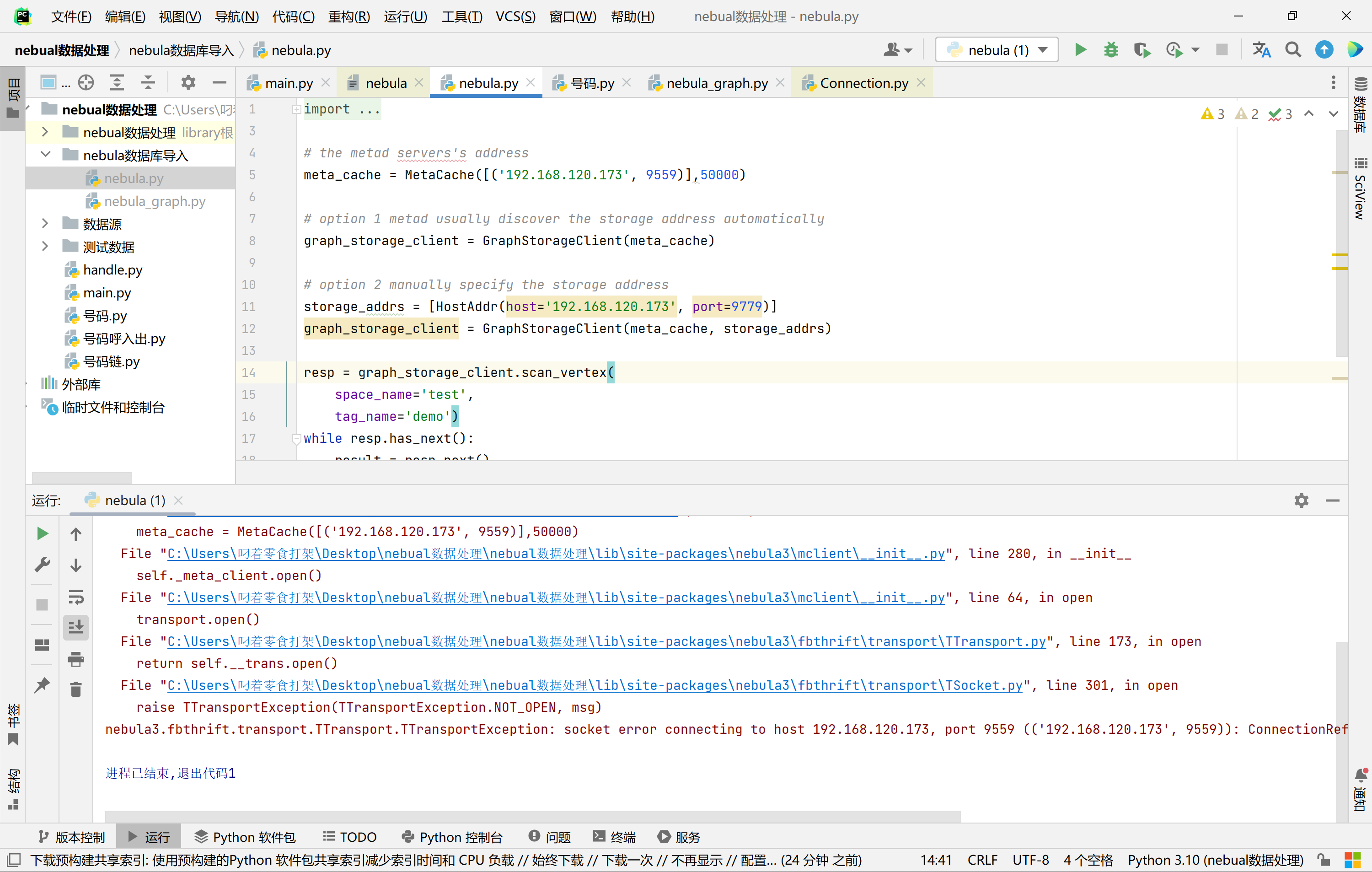
meta_cache = MetaCache([('192.168.120.173', 9559)],50000)
# option 1 metad usually discover the storage address automatically
graph_storage_client = GraphStorageClient(meta_cache)
# option 2 manually specify the storage address
storage_addrs = [HostAddr(host='192.168.120.173', port=9779)]
graph_storage_client = GraphStorageClient(meta_cache, storage_addrs)
resp = graph_storage_client.scan_vertex(
space_name='test',
tag_name='test')
while resp.has_next():
result = resp.next()
for vertex_data in result:
print(vertex_data)
C:\Users\叼着零食打架\Desktop\nebual数据处理\nebual数据处理\Scripts\python.exe C:\Users\叼着零食打架\Desktop\nebual数据处理\nebula.py
Traceback (most recent call last):
File "C:\Users\叼着零食打架\Desktop\nebual数据处理\nebual数据处理\lib\site-packages\nebula3\fbthrift\transport\TSocket.py", line 286, in open
handle.connect(address)
ConnectionRefusedError: [WinError 10061] 由于目标计算机积极拒绝,无法连接。
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "C:\Users\叼着零食打架\Desktop\nebual数据处理\nebula.py", line 5, in <module>
meta_cache = MetaCache([('192.168.120.173', 9559)],50000)
File "C:\Users\叼着零食打架\Desktop\nebual数据处理\nebual数据处理\lib\site-packages\nebula3\mclient\__init__.py", line 280, in __init__
self._meta_client.open()
File "C:\Users\叼着零食打架\Desktop\nebual数据处理\nebual数据处理\lib\site-packages\nebula3\mclient\__init__.py", line 64, in open
transport.open()
File "C:\Users\叼着零食打架\Desktop\nebual数据处理\nebual数据处理\lib\site-packages\nebula3\fbthrift\transport\TTransport.py", line 173, in open
return self.__trans.open()
File "C:\Users\叼着零食打架\Desktop\nebual数据处理\nebual数据处理\lib\site-packages\nebula3\fbthrift\transport\TSocket.py", line 301, in open
raise TTransportException(TTransportException.NOT_OPEN, msg)
nebula3.fbthrift.transport.TTransport.TTransportException: socket error connecting to host 192.168.120.173, port 9559 (('192.168.120.173', 9559)): ConnectionRefusedError(10061, '由于目标计算机积极拒绝,无法连接。', None, 10061, None)