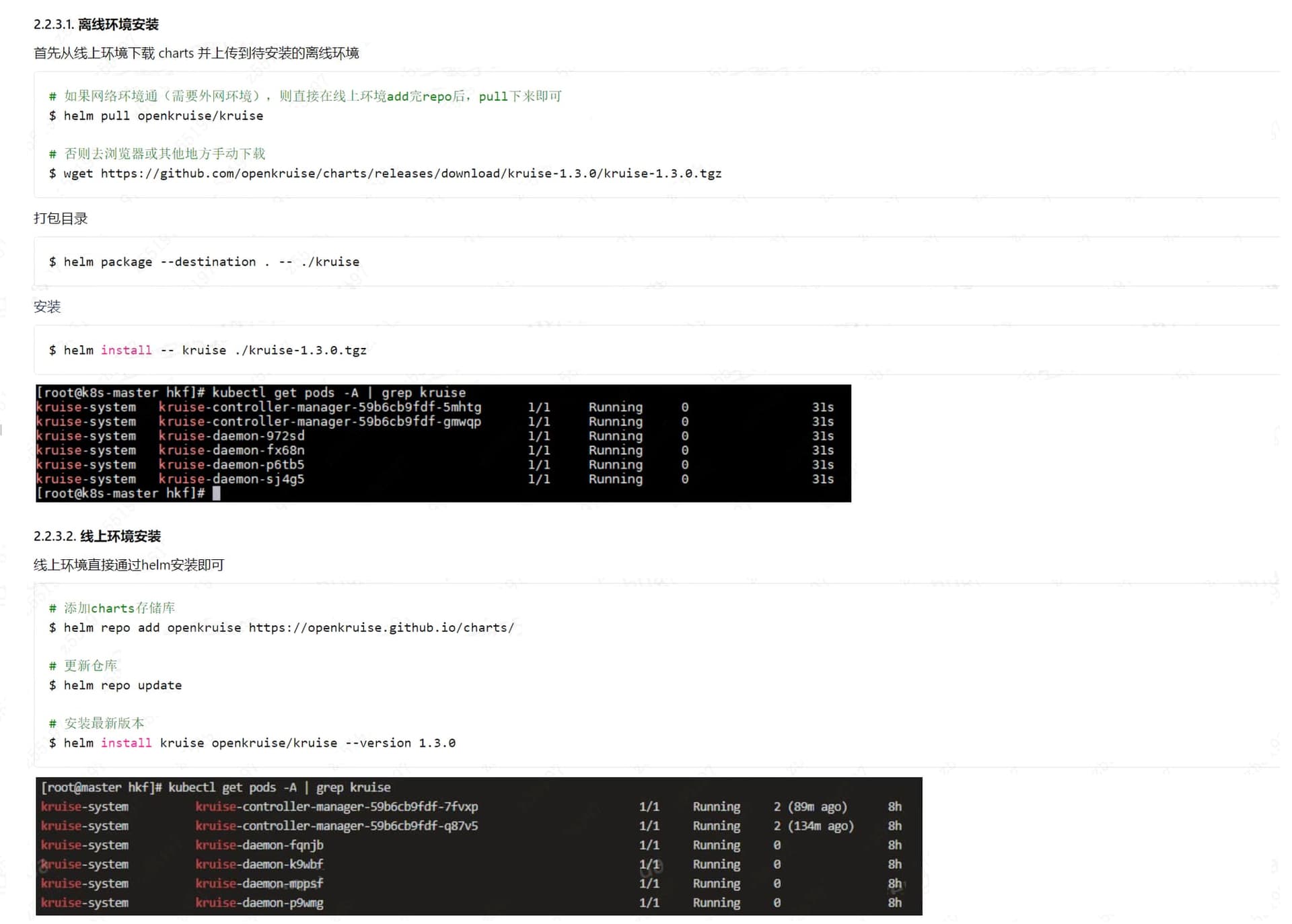
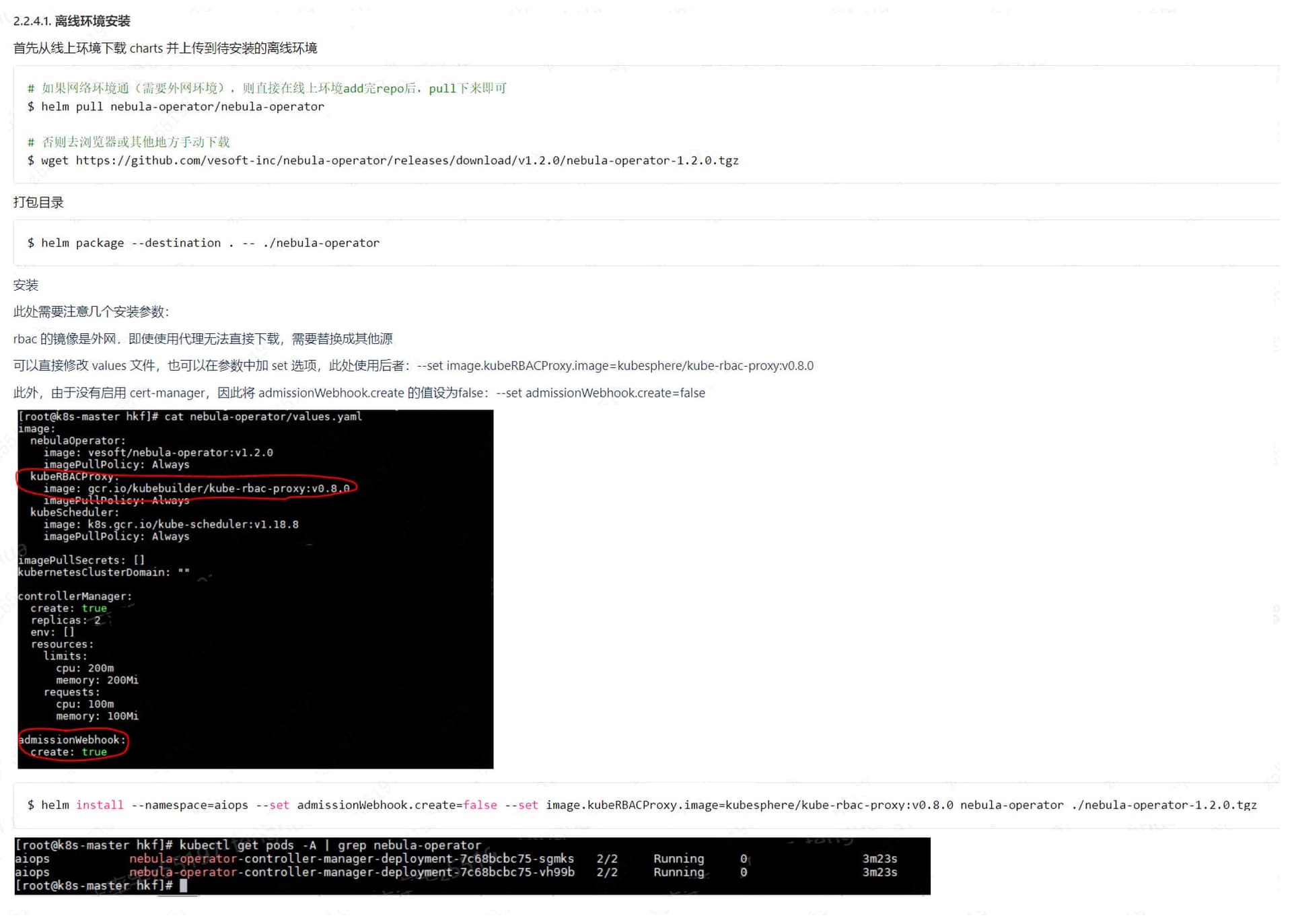
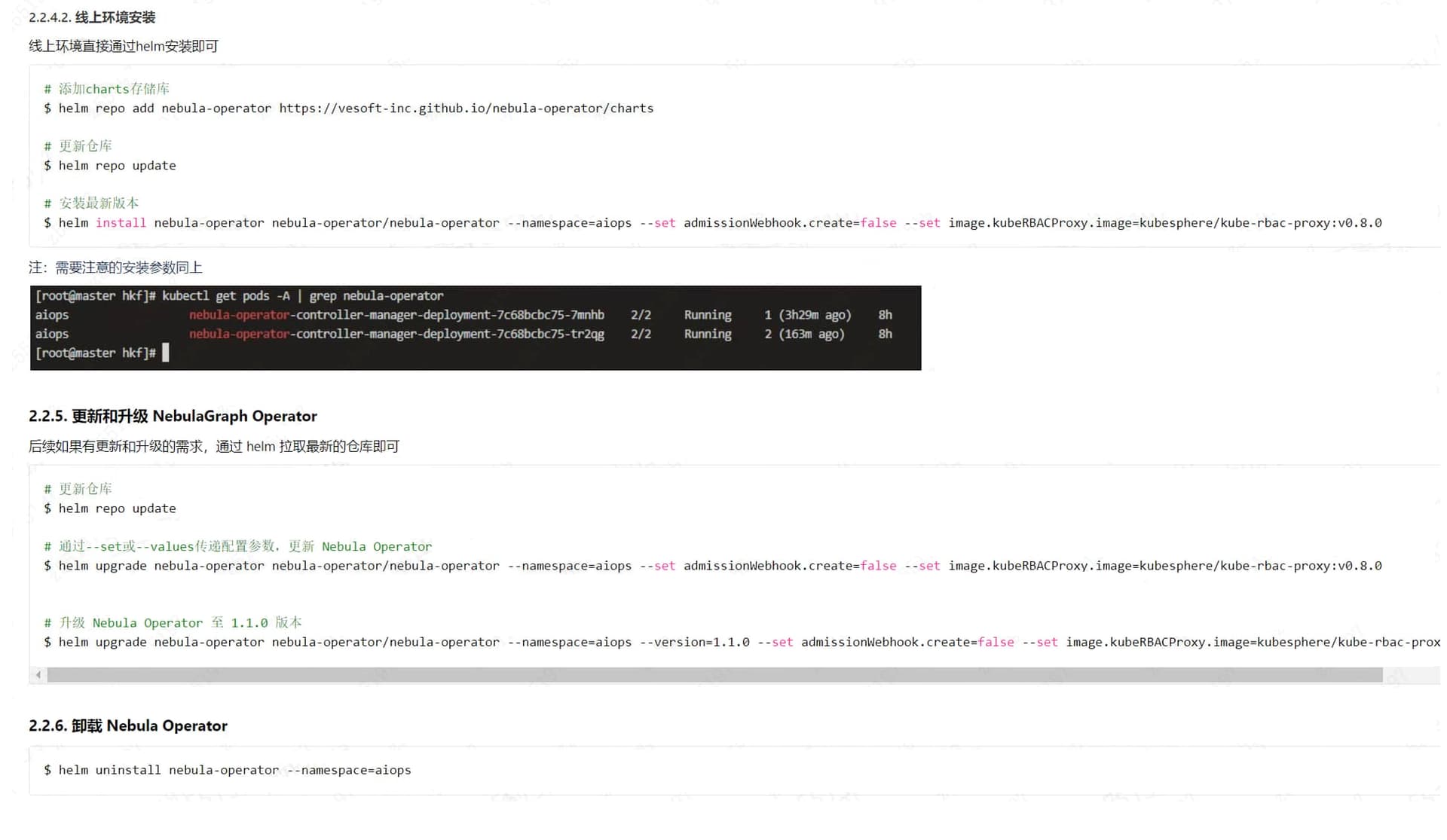
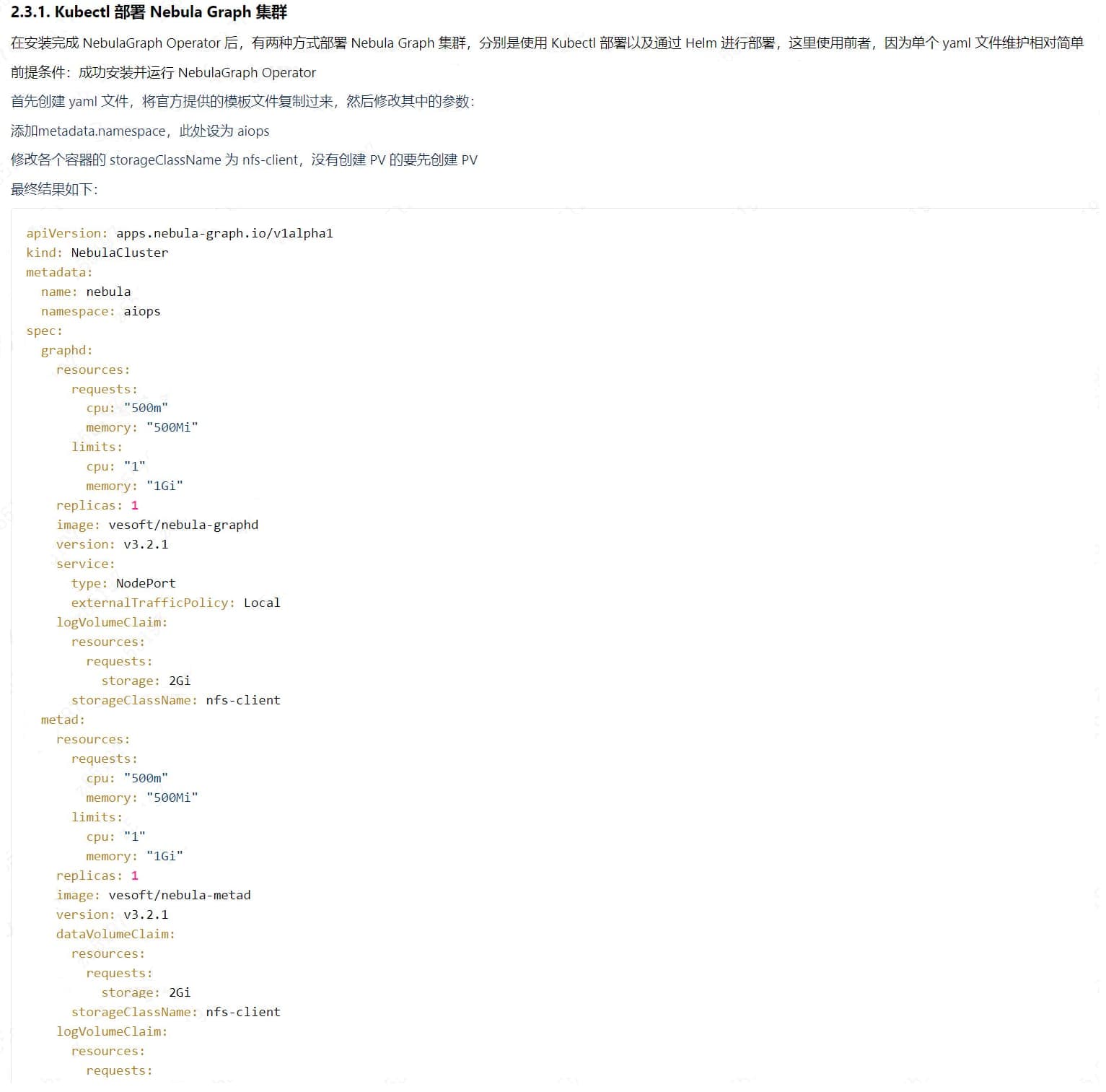
你这能获取到storaged的日志吗,可以上传过来看看
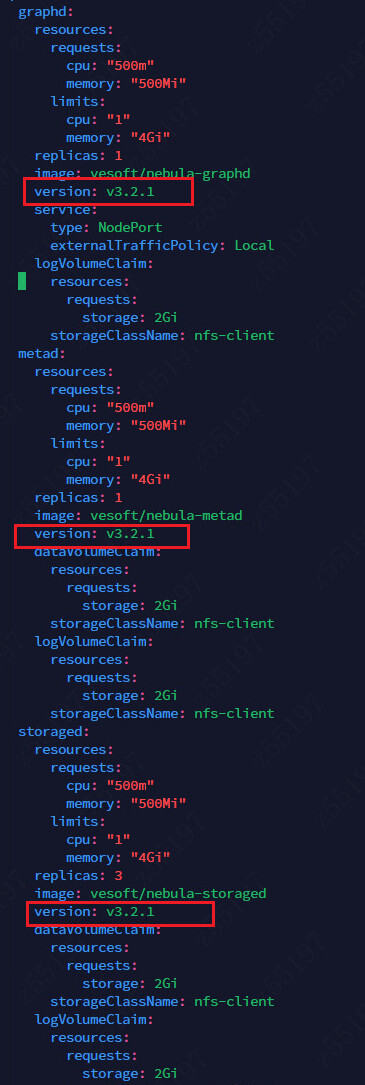
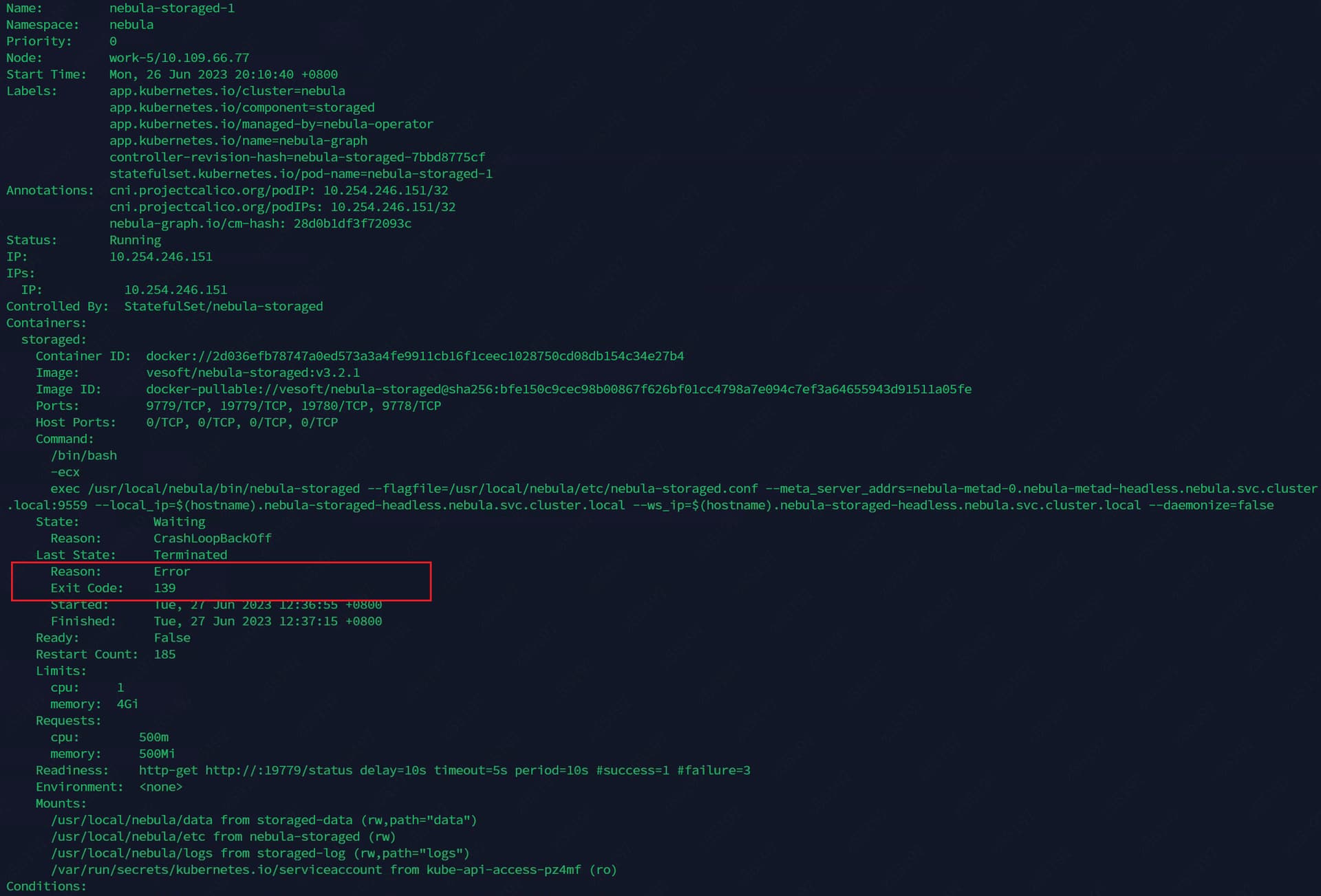
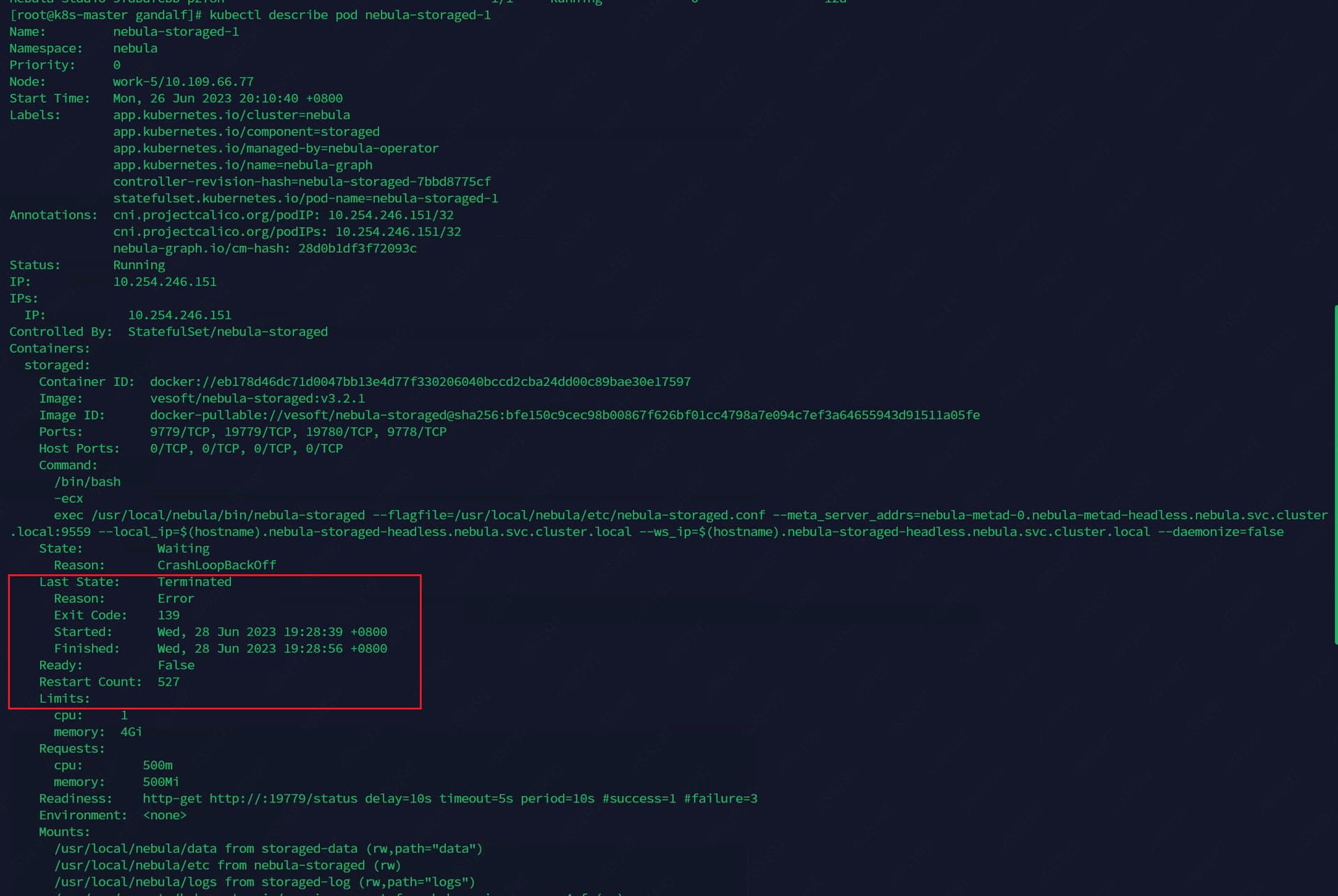
storaged的pod信息
麻烦帮忙看一看,看日志信息看不出来是什么问题,但是这个状态退出码是139,是什么心跳检测的问题嘛,用的注册中心是coredns。
老哥,能看出来大概是哪里的问题吗,搞了一周了,还没搞好。
wey
7
默认服务的日志没有 forward 给 stdout/stderr 所以其实 kubectl logs 看不到这部分信息,参考
去 pod 里看 log 目录下的信息哈
cc @kevin.qiao 不知道我们默认把日志 forward 给 pod stdout/err 是否合理,否则 SRE 同学们不会意识到需要去文件里看日志,似乎有点违反常规?
你好呀,我尝试进入pod了,因为pod是crashLoopBackOff,pod没有创建成功所以进入不了pod查看日志,有用的信息只有pod exit 139 目前。
wey
10
嗯嗯,对,只能把 volume mount 到其他 pod 看了或者改成 forward 给 stdout
参考
你好呀,这个日志是有用的吗?用处不大的话我就再找找,麻烦你了。
是呀 太感谢你了 解决问题了 真的太感谢了 我好好努力 希望可以去你们那里实习!!!!
1 个赞
wey
16
呀,欢迎呀!可以加我微信说实习的事情呀,我们应该是在招聘的
1 个赞
steam
17
 这位用户目前在其他公司实习啦,他会研究研究我们的内核之后再来投递我们的实习岗的。
这位用户目前在其他公司实习啦,他会研究研究我们的内核之后再来投递我们的实习岗的。
2 个赞
system
关闭
18
此话题已在最后回复的 30 天后被自动关闭。不再允许新回复。