- nebula 版本:3.4.0
- 部署方式:分布式
- 安装方式:源码编译
- 是否上生产环境:Y
- 硬件信息
vCPU: 72C 内存: 196G 系统盘: SSD 480GB 数据盘: NVME 4 * 4T
问题的具体描述
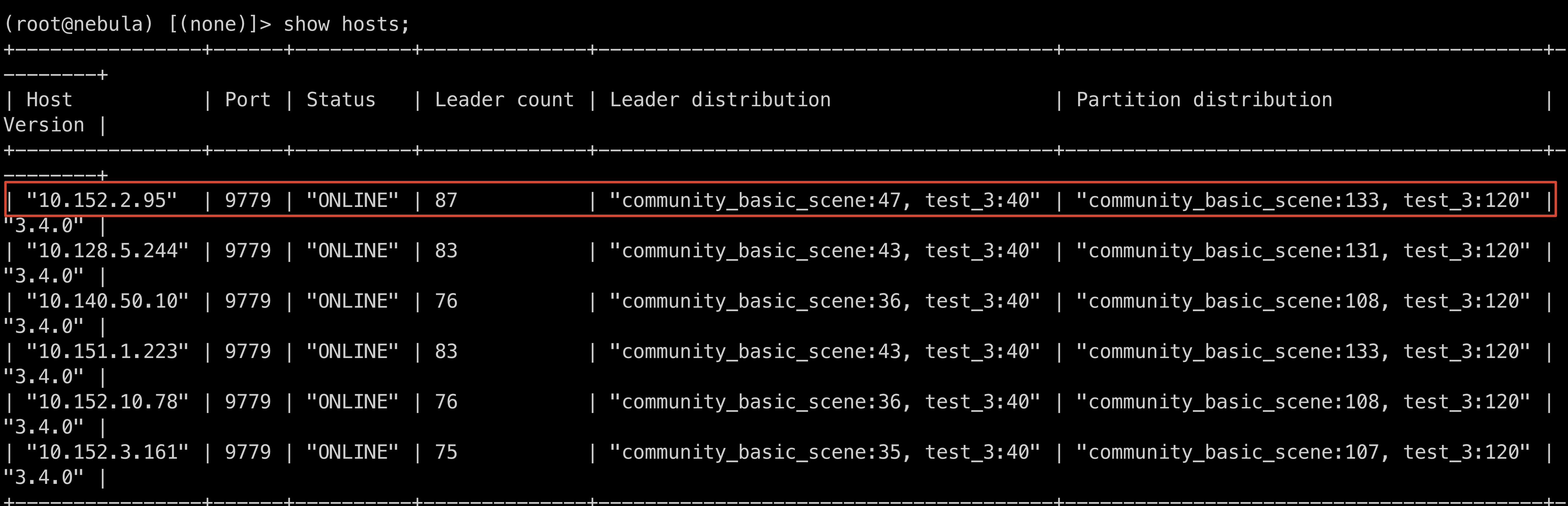
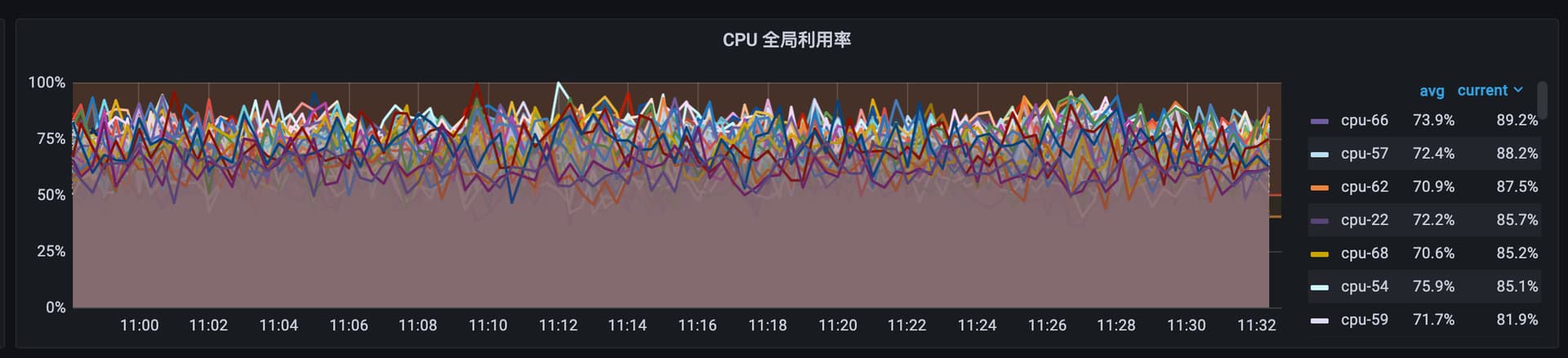
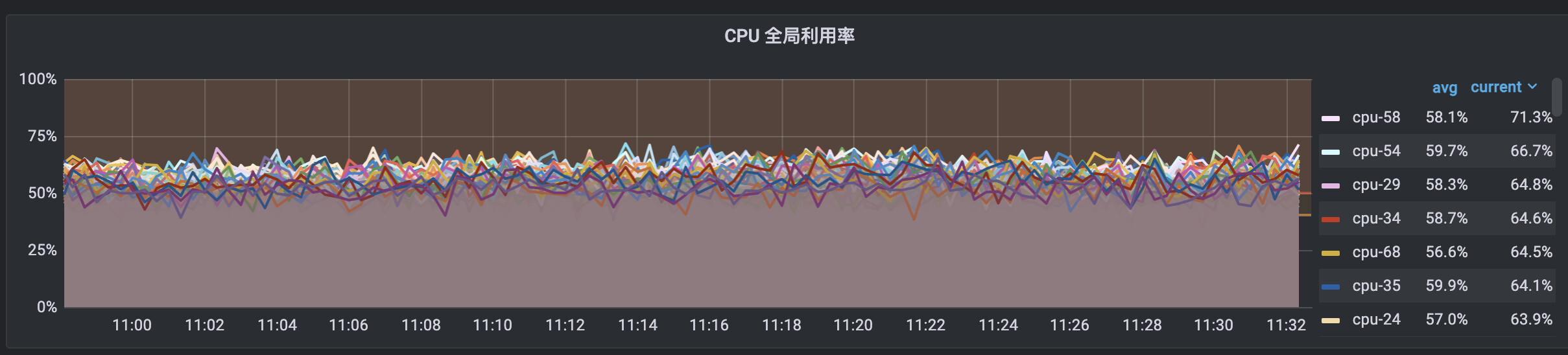
host 节点 10.152.2.95 cpu负载相比于其他节点高出不少,在新增存储节点时,数据已经Balance Data 和 Balance Leader过了
host 10.152.2.95 CPU 监控
host 10.151.1.223 CPU监控
问题:
- 如何解决负载不均问题,是否需要重新balance一次?
- 使用
SHOW QUERIES | ORDER BY $-.DurationInUSec DESC | LIMIT 10; 时只能看到host 为计算节点,如何判断对哪些存储节点负载较大?
节点上有graph服务吗?有可能查询都发到这个节点的graph上了,如果没有graph也有可能是这个节点有热点数据。还有就是看下节点间的配置一致吗
1 个赞
每台机器只部署graph 或者 Storage, 不存在计算节点和存储节点混合部署
节点间配置完全一致
怎么查看热点数据?
看样子的partition 分配不均导致的
暂时没办法查看热点数据,虽然part分布肯定是均衡的,leader分布也均衡的情况下,有可能你的查询就是落在这个节点的leader上。另外数据分片是是是hash取模的,有可能数据本身就是有倾斜。
Compaction操作会读取硬盘上的数据,然后重组数据结构和索引,然后再写回硬盘,可以成倍提升读取性能。
所以如果对数据Compaction操作,然后再Balance Data 和 Balance Leader 是否可行?
我觉得做其他操作之前,可能要先考虑的是你的查询是否有热点?比如频繁查一些大点
1 个赞
compaction是节点内的操作,不影响节点之间的数据
对集群扩容或者缩容操作 再进行Balance操作 可行否 ?
system
关闭
9
此话题已在最后回复的 30 天后被自动关闭。不再允许新回复。