提问参考模版:
- nebula 版本:nebula 3.4.1
- 部署方式: 分布式
- 安装方式: RPM
- 是否上生产环境:Y
- 硬件信息
- 磁盘( 推荐使用 SSD)SSD
- CPU、内存信息, 16核,128G
- 问题的具体描述
- 相关的 meta / storage / graph info 日志信息(尽量使用文本形式方便检索)
最近对慢查询做优化,发现一个参数max_job_size, 于是做了尝试,发现效果并不明显。
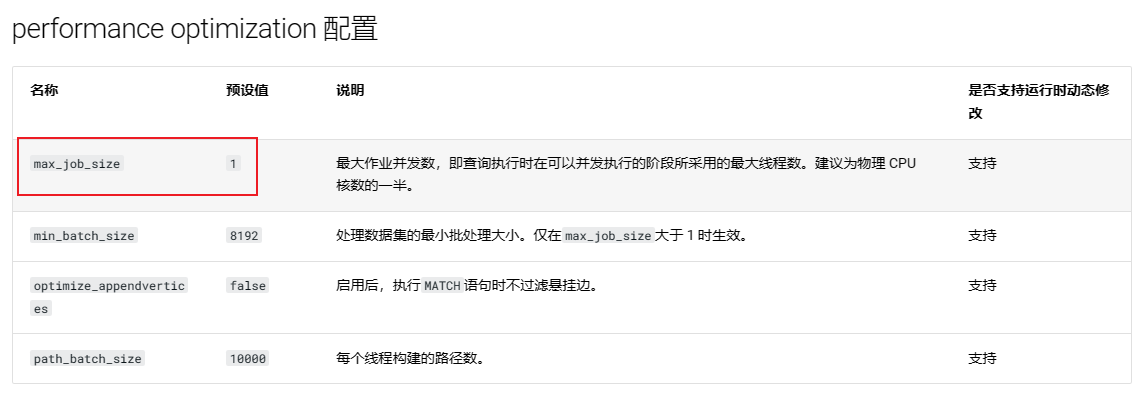
同时记得storaged 层有两个并发的参数,如下,想了解下这两个参数的区别?
目前实验看起来graphd 层的 max_job_size 看起来作用很小,尤其对subgraph 的一些语句没有什么提升,max_job_size 中提到了可以并发执行的阶段有是指某些算子可以并发吗? 比如
Traverse, GetNeigher 这些阶段吗?
–query_concurrently=true
–num_io_threads=16