- nebula 版本:3.5.0
- 部署方式:云端 / 分布式 / 单机(分布式)
- 安装方式:源码编译 / Docker / RPM(源码编译)
- 是否上生产环境:Y / N(Y)
- 硬件信息
- 磁盘( 推荐使用 SSD)
- CPU、内存信息
根据手册里的步骤到了生成数据这一步
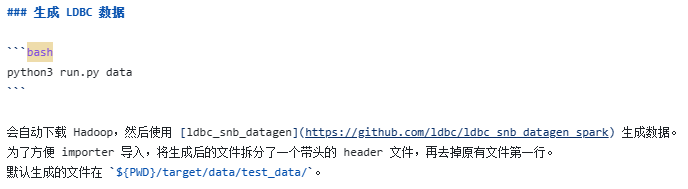
下几张图为我生成的csv数据

请问对于这些csv数据应该怎样进行处理呢?我看有的手册说去掉第一行,有的没说,现在对于这个csv文件的处理部分有点没太弄懂?可以不处理,直接把数据导入到 nebula-graph吗?
你看的什么手册?
https://docs.nebula-graph.com.cn/2.0/nebula-importer/config-with-header/
https://github.com/nebula-contrib/NebulaGraph-Bench/blob/v1.2.0/README_cn.md?plain=1
https://docs.nebula-graph.com.cn/1.2.0/manual-CN/1.overview/2.quick-start/4.import-csv-file/#go-importer_csv
主要是看NebulaGraph-Bench的readme,看了以后没看懂
![]()
拆分后的文件是哪个文件?去掉原有文件第一行?原有文件又是哪个,是指所有的csv文件?
原文件就是被拆分的那个文件。
你这个文档。。都是 2 年前的,你从哪里淘出来的,- -,你可以看最新的文档,这里是你用的 3.5.0 的文档哈:https://docs.nebula-graph.com.cn/3.5.0/nebula-importer/config-with-header/
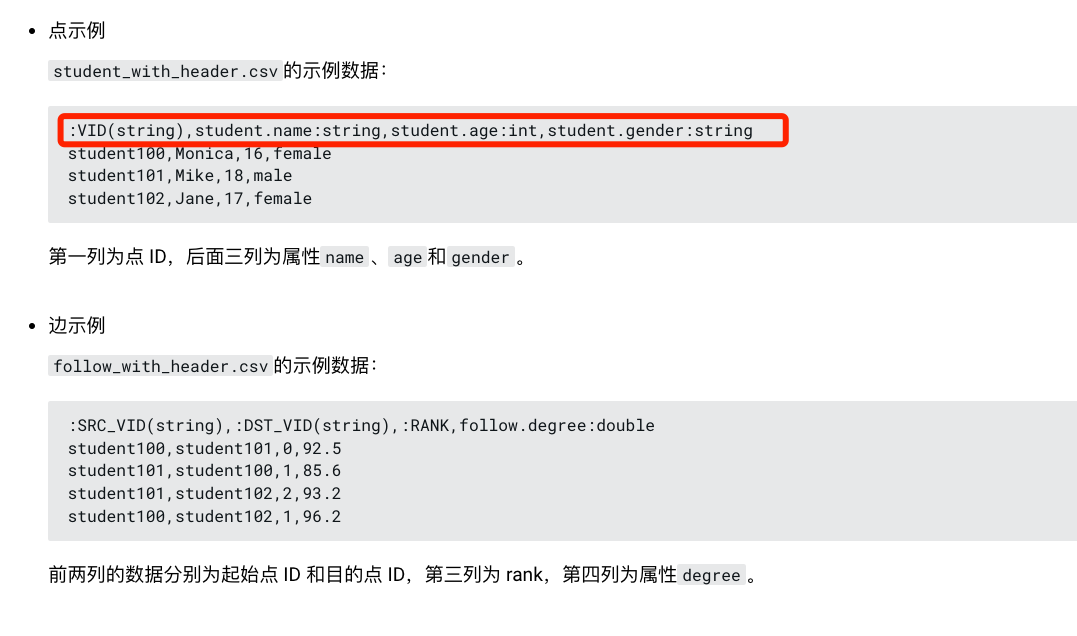

上面分别是有表头(红色)和无表头(绿色),你可以看到,有表头的会写明这个字段是什么类型,对应什么属性,但是无表头的直接就是数值。
相对应的配置文件,有表头的导入方式在配置文件中就不需要增加这个 tag 的属性有什么,什么类型,反之,无表头的配置文件就要说明清楚这些属性是什么、类型是什么。



是啊,看你哪种方式方便。不一定要都改成有表头的。
所以改不改表头都是可以的。如果我只是复现ldbc数据集,那是不是不用修改配置文件了,直接进行导入就好
你得看下你的 importer 的配置文件(我不清楚是否已经是对着 ldbc 做了适配)
importer的配置文件内容,我只修改了address的信息,但是当我运行python3 run.py nebula importer命令后再打开看,发现内容被复原了,所以现在配置文件处于一点也没修改的状态
此话题已在最后回复的 30 天后被自动关闭。不再允许新回复。