- 内核版本:3.5.0
![]()
- importer 版本:3.1.0

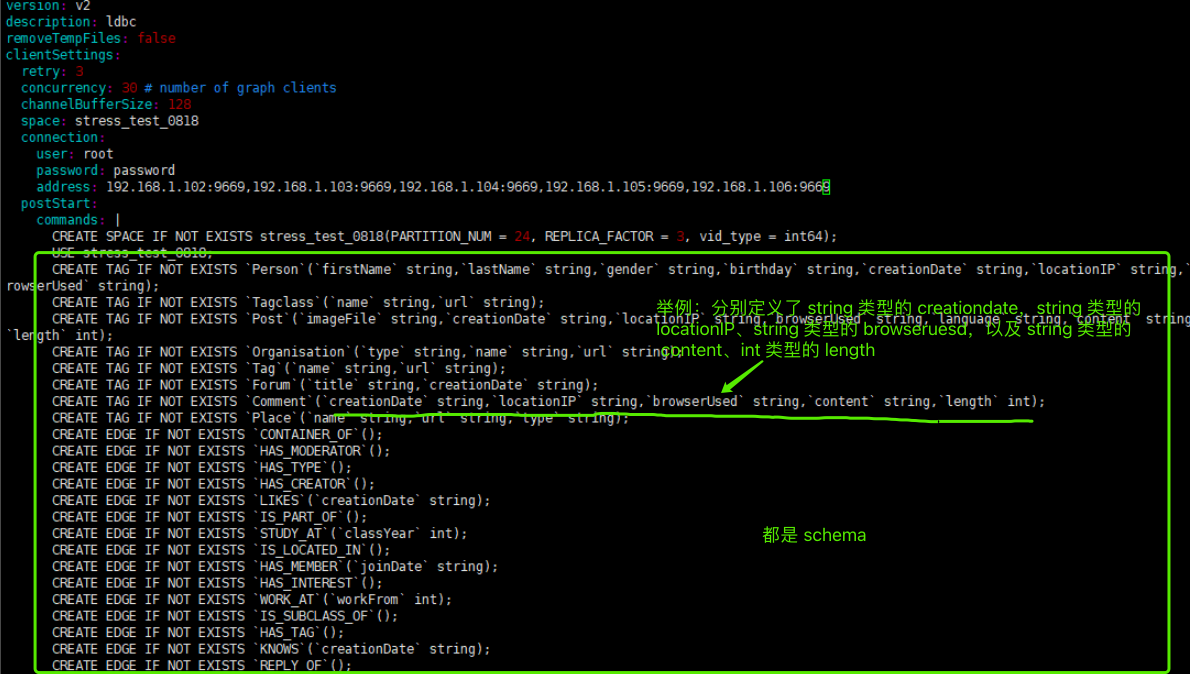
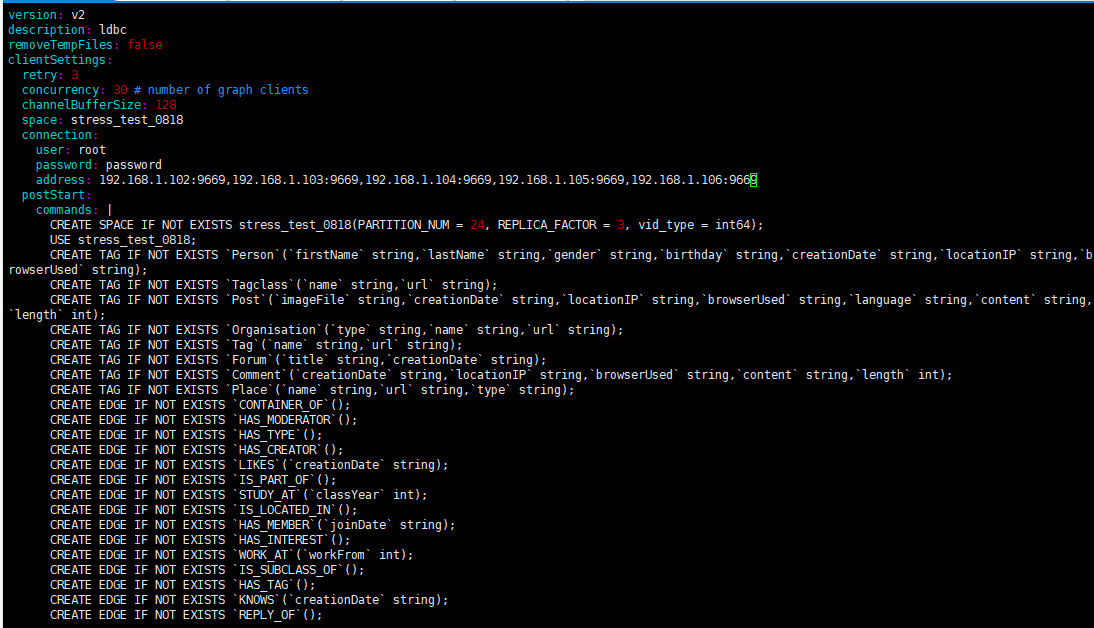
使用python3 run.py nebula importer --dry-run命令生成yaml配置文件,修改内容如下
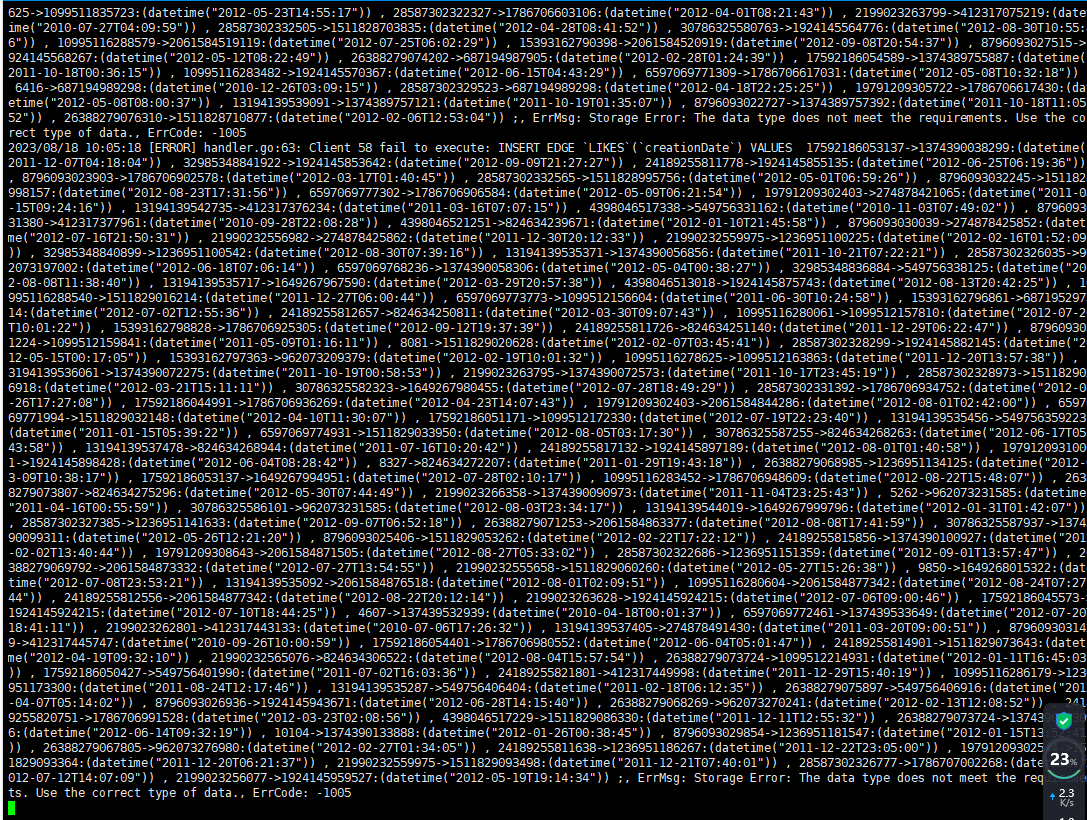
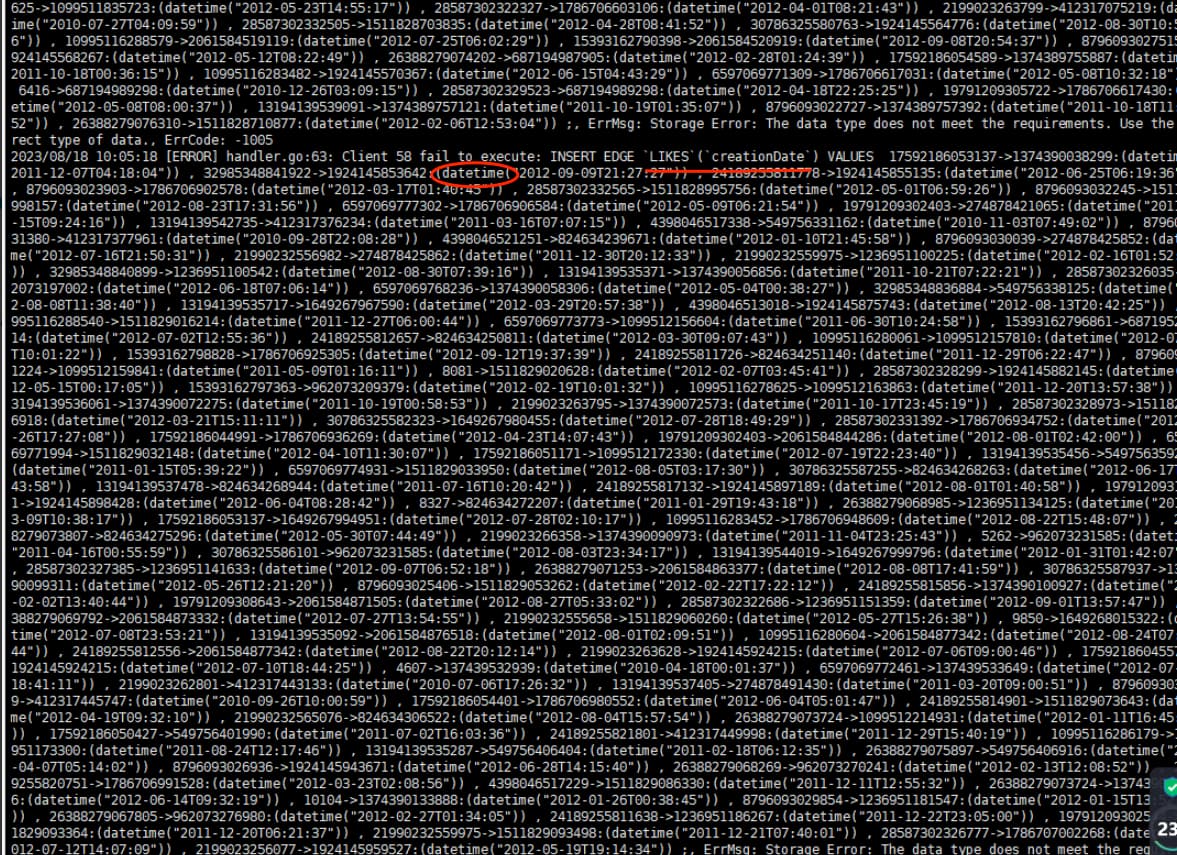
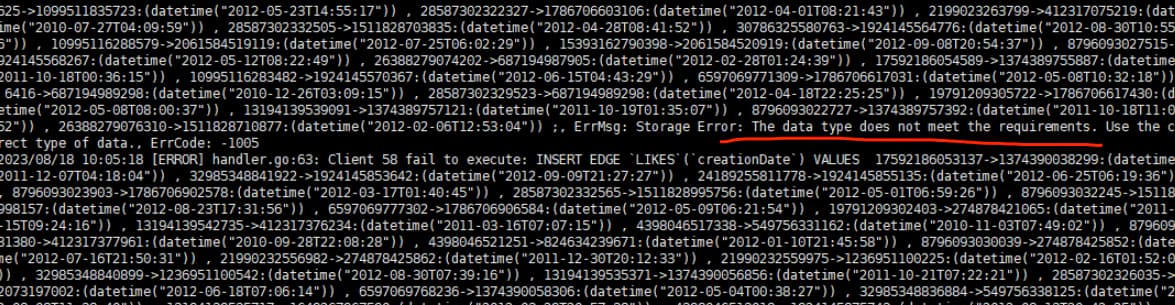
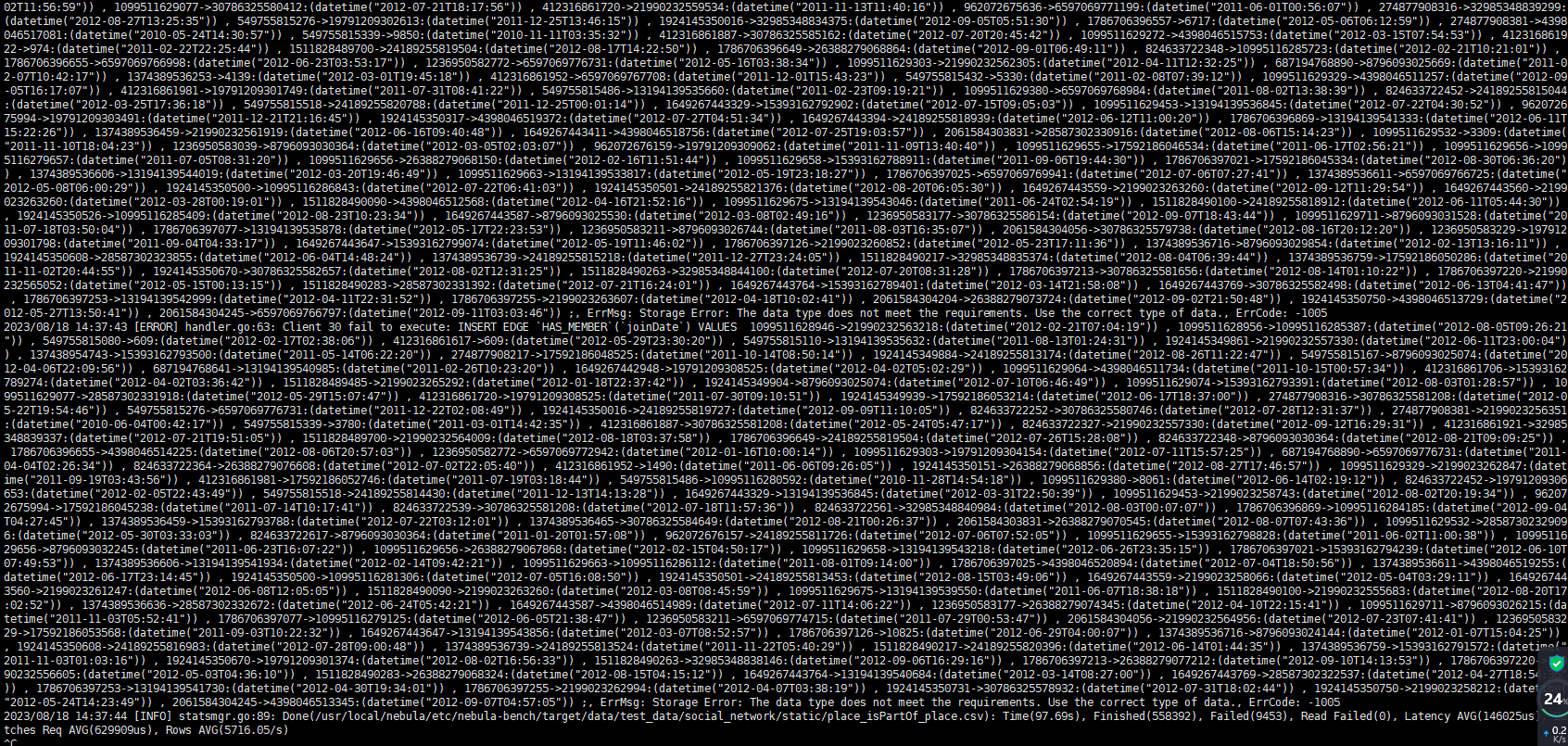
使用/usr/local/nebula/etc/nebula-bench/nebula-importer/nebula-importer --config importer_config.yaml命令导入时,变成这样了,请问是什么原因导致的呢
![]()
使用python3 run.py nebula importer --dry-run命令生成yaml配置文件,修改内容如下
你的 schema 中 likes 的属性是 string 类型的,你传值的时候传入的是 datetime 类型的,自然会报错。
报错信息翻译成中文大概意思就是,你导入的数据同说好的数据类型不一致(要遵守约定哟~~~
不好意思~我有两个问题:
1、这个属性是什么类型应该在哪里看?
2、五台电脑一样的schema,为什么一台数据导入成功,其他四台报1005错误?
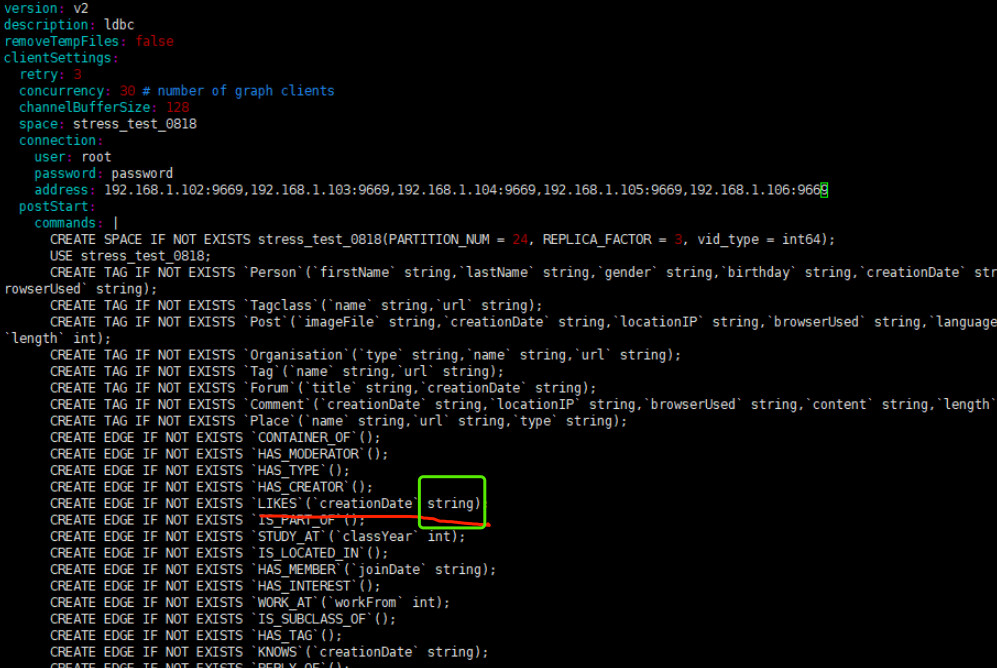
这个是你自己写的,就像我之前在另外个帖子里和你说的那样,你如果用了无表头的话,就在 yaml 文件里约定好对应 schema 的类型,就是下图这些内容:
如果是shi时间戳之类的,你可以定义成 datetime 或者其他时间格式的,这是 NebulaGraph 支持的所有的时间相关的格式:https://docs.nebula-graph.com.cn/3.6.0/3.ngql-guide/3.data-types/4.date-and-time/
我这个是ldbc的yaml文件,是自动生成的,我只改了password和address,所以这个类型在哪看我不太清楚。所以这些无标头的文件我需要一个一个打开看他们的类型?
你约定好的数据类型,传值(参)的时候总得对上啊。自然得看看文件和你的数据是不是类型对得上。
你好,就拿comment.csv举例子,yaml文件有string类型的creationdate,string类型的locationIP,string类型的browseruesd,string类型的content和int类型的length,下图是我的comment.csv内容,我应该怎么修改呢?
like、has_member这些边很明显需要用datatime类型的,从schema来看和实际执行的语句冲突了。
可以对比一下其他几台机器的schema?
我推测是否可能是生成yaml的时候弄错了什么导致的,其他机器没误操作就生成了正确的内容
谢谢,我把数据重新导入就没有错误了
此话题已在最后回复的 7 天后被自动关闭。不再允许新回复。