- nebula 版本:bench v1.2.0 import v3.1.0 ldbc_snb_datagen v0.3.3
- 部署方式: 分布式
- 安装方式:源码编译
- 是否上生产环境:Y
- 硬件信息
- 磁盘( 推荐使用 SSD)
- CPU、内存信息
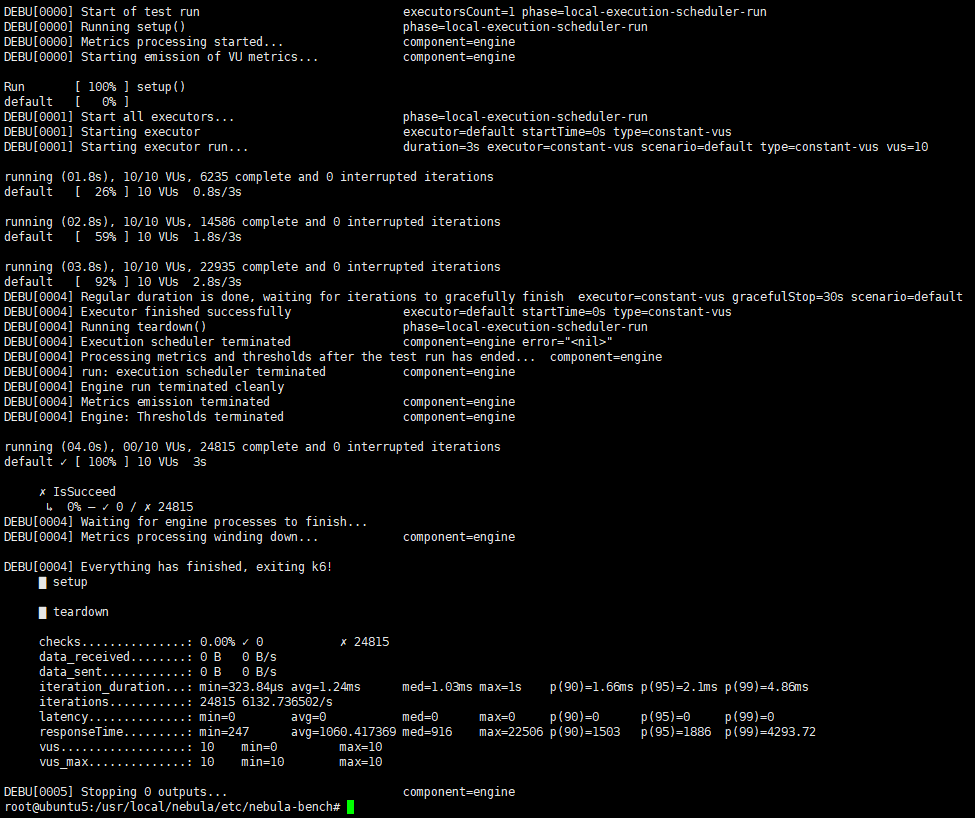
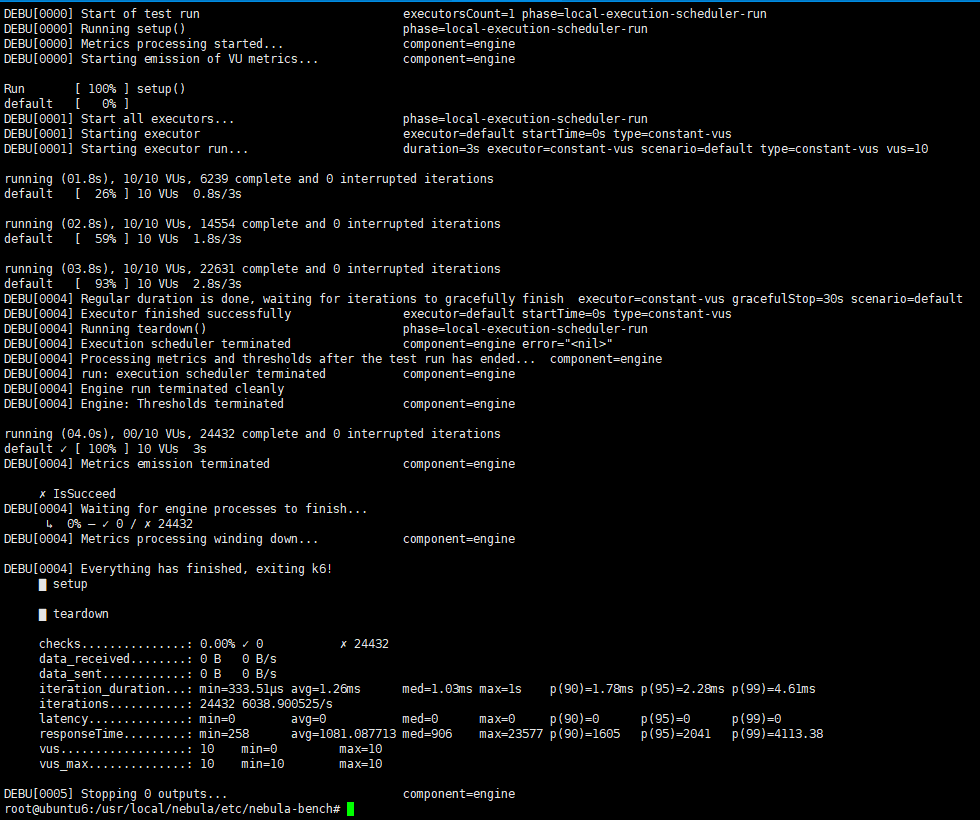
运行python3 run.py stress run命令后,刚开始isducceed 100%,继续测试,几轮过后,变成0%成功,然后停止测试,这是正常的吗
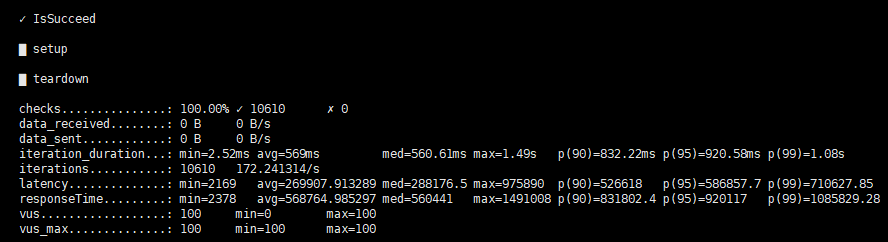
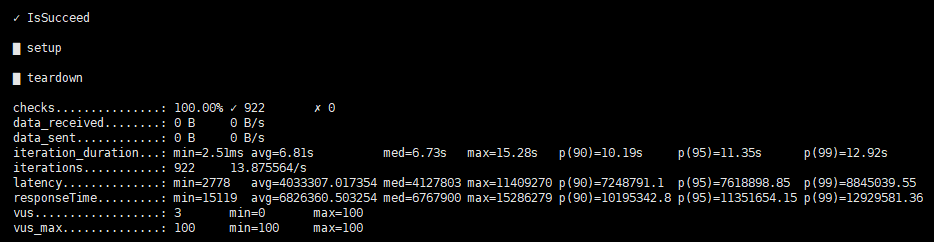
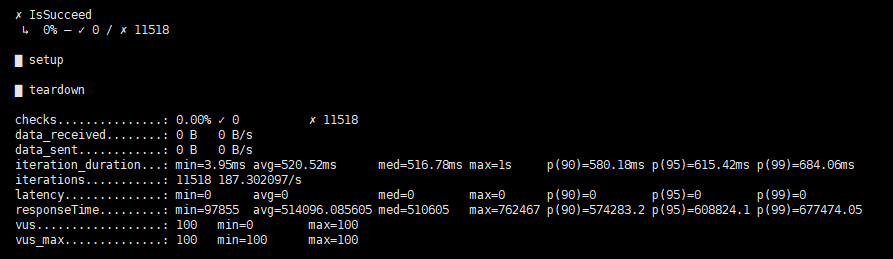
不是正常的,看最后一张图应该是所有的请求都失败了,可以查看该压测任务对应的out.csv文件,看看是因为什么原导致的请求失败。

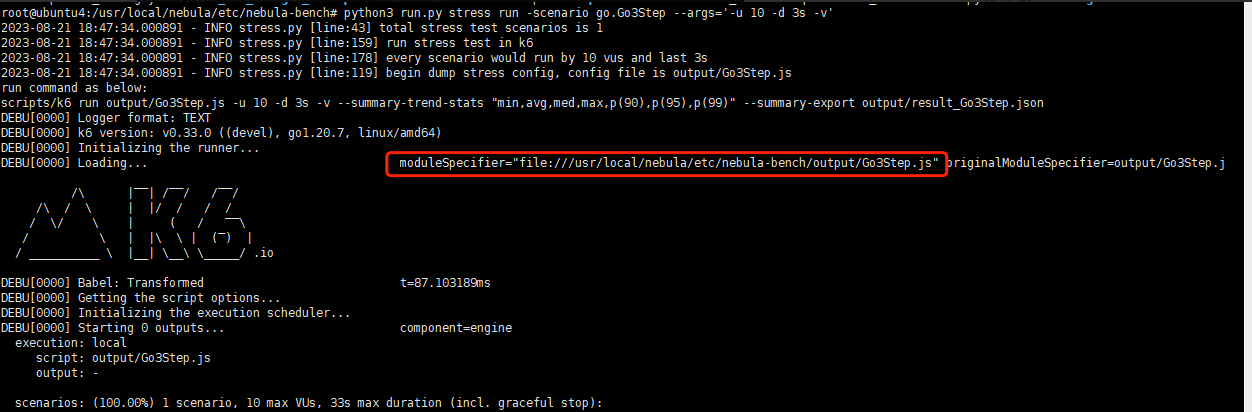
确认最后一张图对应的scenario是Go3Step吗?确认的话可以单独执行一下该scenario,加一下-v看看详细信息。
python3 run.py stress run -scenario go.Go3Step --args='-u 10 -d 3s -v'
2 个赞
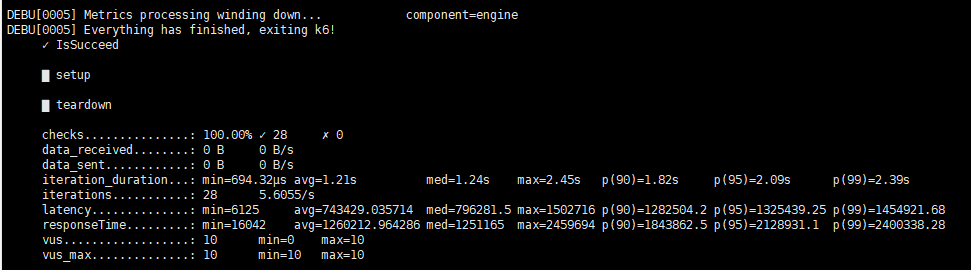
上面为第一跳的结果图,如下为第三跳的结果图,显示space was not chosen
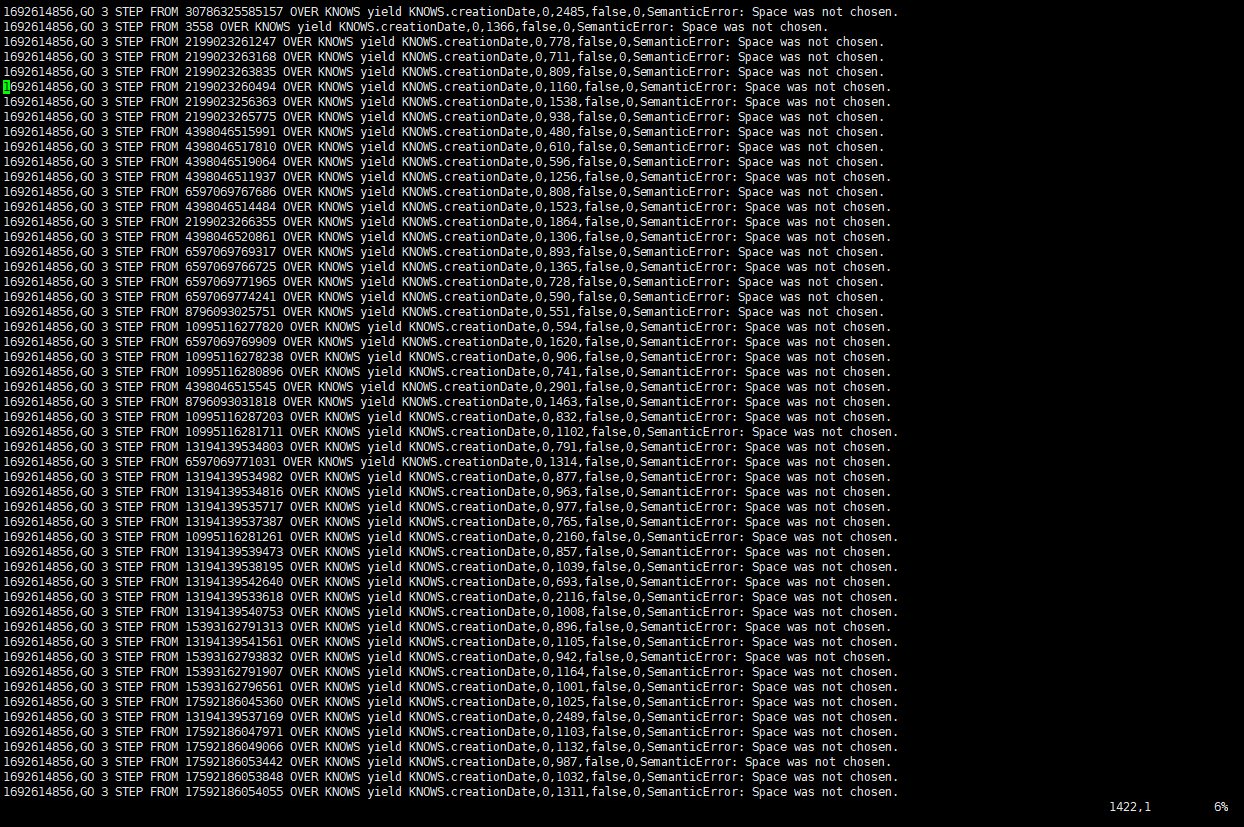
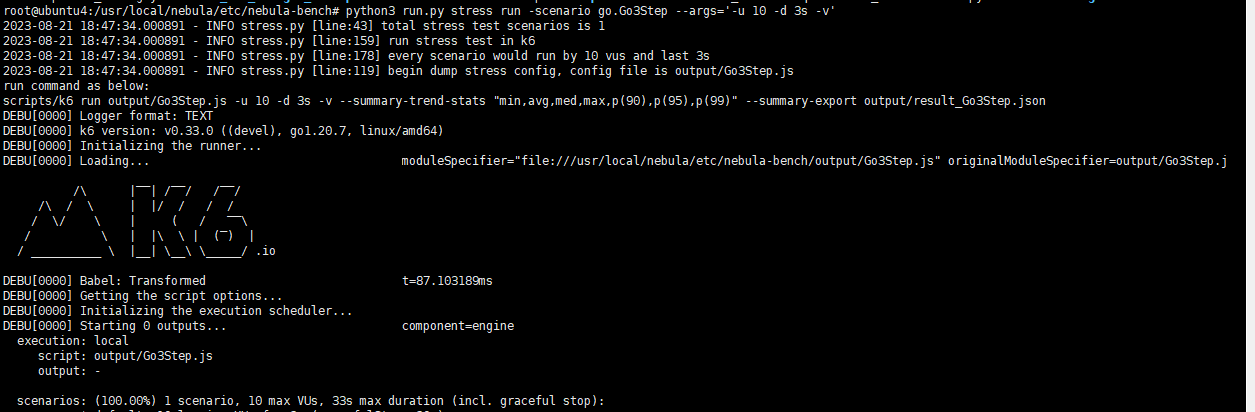
命令python3 run.py stress run -scenario go.Go3Step --args='-u 10 -d 3s -v’运行结果如下

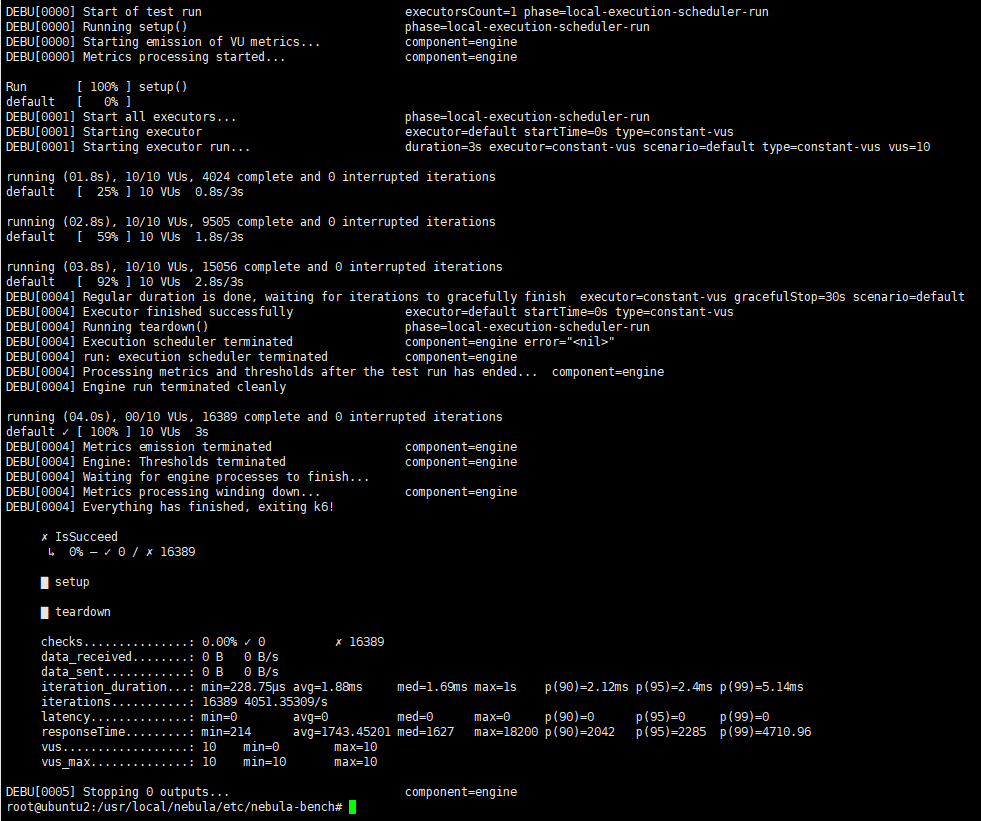
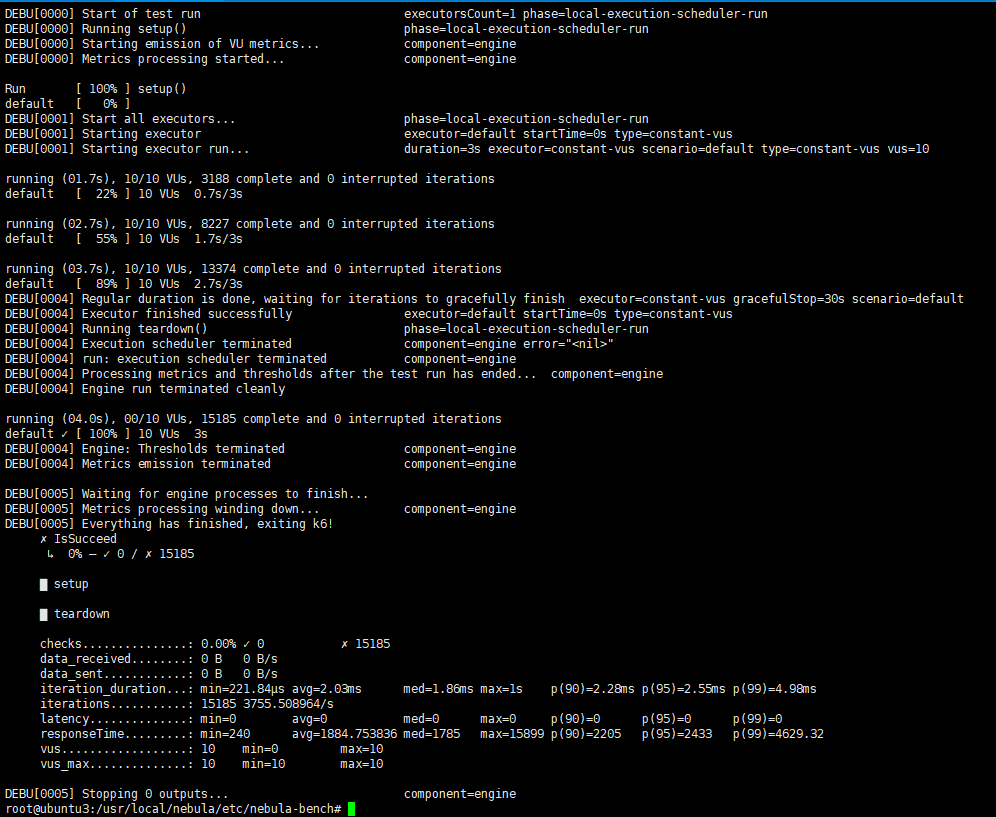
其他四台的三跳结果没显示错误,但是执行命令python3 run.py stress run -scenario go.Go3Step --args='-u 10 -d 3s -v’运行issucceed 0%结果如下
可以看看这个js文件,里面的space是什么?
如果js里面的space不是预期的,可以在该机器上使用以下命令设置一下space_name
export NEBULA_SPACE=test_space
这个配置文件里面有两个关键的配置:
graphd的地址【即图中的127.0.0.1】 & space名称【即图中的stress_test_0821】
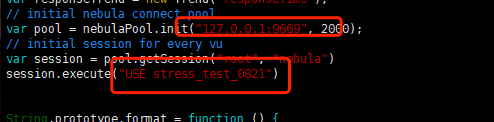
如果这两个配置与实际不符合,可以用export设置下全局变量:
export NEBULA_SPACE=test_space
export NEBULA_ADDRESS=127.0.0.1:9669
我们在执行的时候会根据全局配置生成js文件再执行压测,所以修改单个js文件没有什么意义。
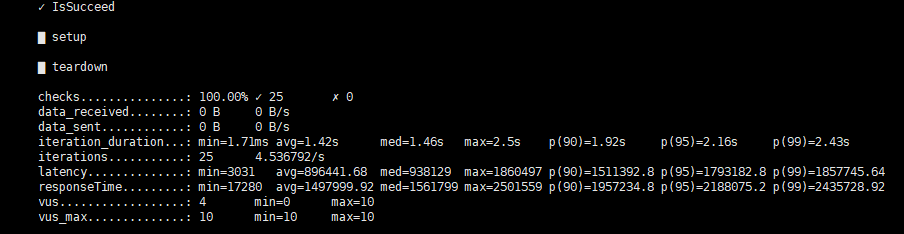
好像这次的checks的数字比较小,是因为导入的数据少吗
不是因为导入的数据少,看latency应该是单个query执行时间较长
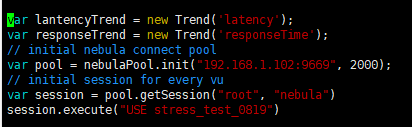
需要,如果部署了多台graphd的话,NEBULA_ADDRESS需要写多台,如:
export NEBULA_ADDRESS=192.168.0.11:9669,192.168.0.12:9669,192.168.0.13:9669
好的,特别感谢,还有一个问题,就是checks的数字比较小(latency应该是单个query执行时间较长)这个问题可以改善吗
此话题已在最后回复的 7 天后被自动关闭。不再允许新回复。