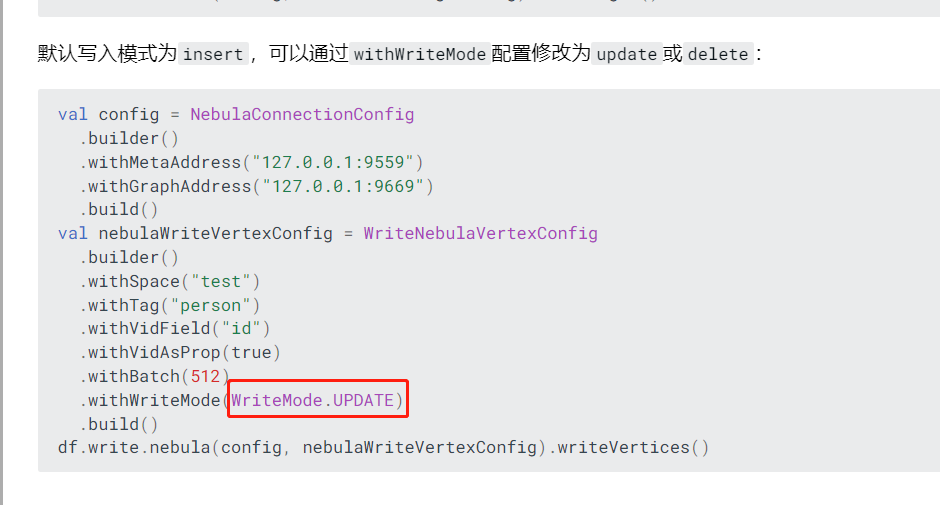
-
nebula 版本:3.5
-
部署方式:分布式
-
安装方式:RPM
-
是否上生产环境:N
-
问题的具体描述
参考 https://docs.nebula-graph.com.cn/3.5.0/nebula-spark-connector/ ,在个人电脑上编译nebula-spark-connector3.4,并运行NebulaSparkWriterExample.scala,使用自带数据,实现数据写入nebula graph数据库集群。
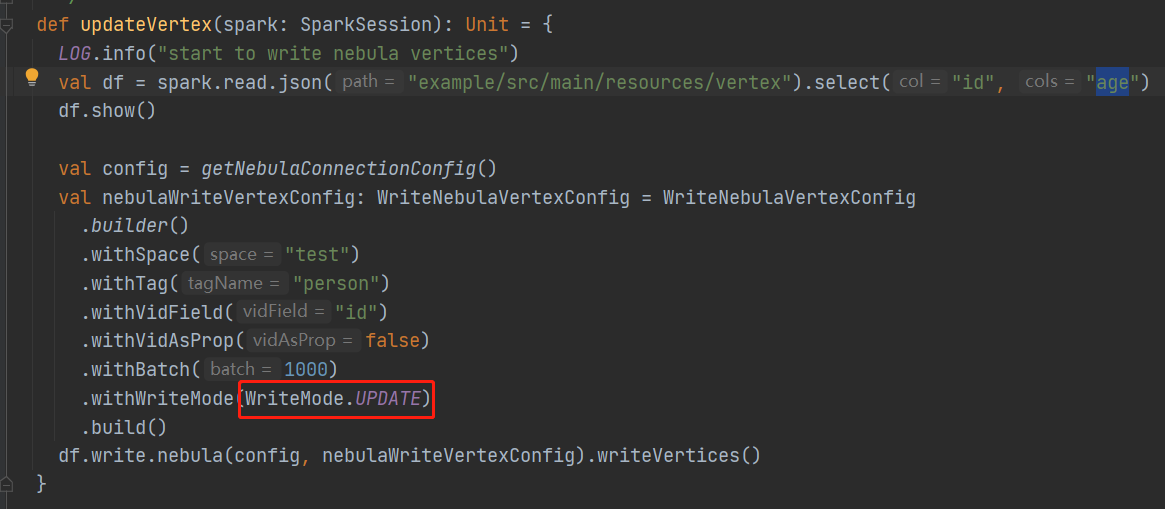
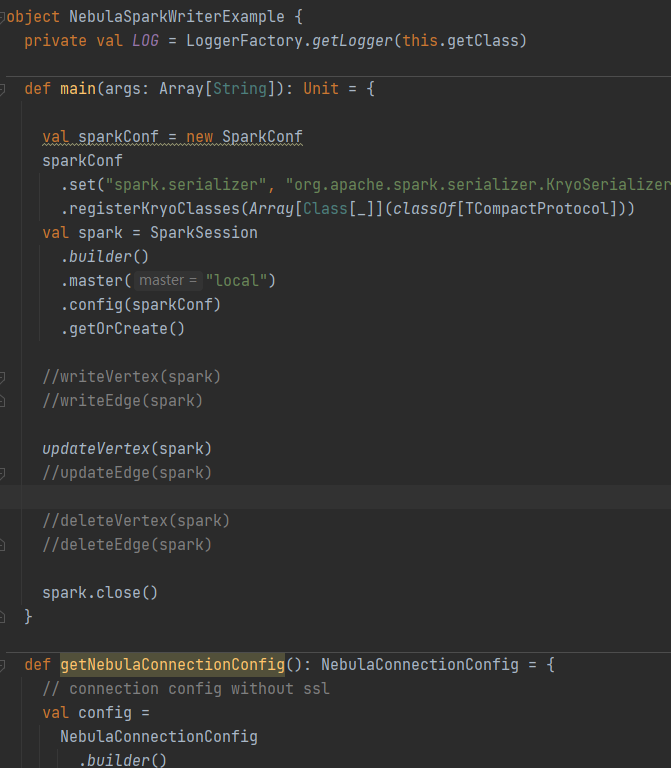
首先根据resource的edge和vertex创建了空间,标签和边类型及属性,并修改NebulaSparkWriterExample.scala,并通过writeVertex(spark)成功将数据写入数据库,并且通过deleteVertex(spark)成功删除数据。但修改代码使用updateVertex(spark)时,运行提示the maximum number of statements for Nebula is 512。
INFO [main] - Running Spark version 2.4.4
INFO [main] - Submitted application: 28d275a5-2a00-4125-854c-5ef855d2993d
INFO [main] - Changing view acls to: zhangkaixiang,root
INFO [main] - Changing modify acls to: zhangkaixiang,root
INFO [main] - Changing view acls groups to:
INFO [main] - Changing modify acls groups to:
INFO [main] - SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(zhangkaixiang, root); groups with view permissions: Set(); users with modify permissions: Set(zhangkaixiang, root); groups with modify permissions: Set()
INFO [main] - Successfully started service 'sparkDriver' on port 62414.
INFO [main] - Registering MapOutputTracker
INFO [main] - Registering BlockManagerMaster
INFO [main] - Using org.apache.spark.storage.DefaultTopologyMapper for getting topology information
INFO [main] - BlockManagerMasterEndpoint up
INFO [main] - Created local directory at C:\Users\zkx\AppData\Local\Temp\blockmgr-edb005b0-fc7a-4fd5-9a4a-c381f8162129
INFO [main] - MemoryStore started with capacity 1967.4 MB
INFO [main] - Registering OutputCommitCoordinator
INFO [main] - Logging initialized @5471ms
INFO [main] - jetty-9.3.z-SNAPSHOT, build timestamp: unknown, git hash: unknown
INFO [main] - Started @5533ms
INFO [main] - Started ServerConnector@36b0fcd5{HTTP/1.1,[http/1.1]}{0.0.0.0:4040}
INFO [main] - Successfully started service 'SparkUI' on port 4040.
INFO [main] - Started o.s.j.s.ServletContextHandler@452ba1db{/jobs,null,AVAILABLE,@Spark}
INFO [main] - Started o.s.j.s.ServletContextHandler@71e5f61d{/jobs/json,null,AVAILABLE,@Spark}
INFO [main] - Started o.s.j.s.ServletContextHandler@2ce86164{/jobs/job,null,AVAILABLE,@Spark}
INFO [main] - Started o.s.j.s.ServletContextHandler@51df223b{/jobs/job/json,null,AVAILABLE,@Spark}
INFO [main] - Started o.s.j.s.ServletContextHandler@fd46303{/stages,null,AVAILABLE,@Spark}
INFO [main] - Started o.s.j.s.ServletContextHandler@60d8c0dc{/stages/json,null,AVAILABLE,@Spark}
INFO [main] - Started o.s.j.s.ServletContextHandler@4204541c{/stages/stage,null,AVAILABLE,@Spark}
INFO [main] - Started o.s.j.s.ServletContextHandler@60fa3495{/stages/stage/json,null,AVAILABLE,@Spark}
INFO [main] - Started o.s.j.s.ServletContextHandler@3e2822{/stages/pool,null,AVAILABLE,@Spark}
INFO [main] - Started o.s.j.s.ServletContextHandler@79e18e38{/stages/pool/json,null,AVAILABLE,@Spark}
INFO [main] - Started o.s.j.s.ServletContextHandler@29a60c27{/storage,null,AVAILABLE,@Spark}
INFO [main] - Started o.s.j.s.ServletContextHandler@1849db1a{/storage/json,null,AVAILABLE,@Spark}
INFO [main] - Started o.s.j.s.ServletContextHandler@69c79f09{/storage/rdd,null,AVAILABLE,@Spark}
INFO [main] - Started o.s.j.s.ServletContextHandler@1ca25c47{/storage/rdd/json,null,AVAILABLE,@Spark}
INFO [main] - Started o.s.j.s.ServletContextHandler@5fcacc0{/environment,null,AVAILABLE,@Spark}
INFO [main] - Started o.s.j.s.ServletContextHandler@533b266e{/environment/json,null,AVAILABLE,@Spark}
INFO [main] - Started o.s.j.s.ServletContextHandler@6d1d4d7{/executors,null,AVAILABLE,@Spark}
INFO [main] - Started o.s.j.s.ServletContextHandler@89ff02e{/executors/json,null,AVAILABLE,@Spark}
INFO [main] - Started o.s.j.s.ServletContextHandler@6865c751{/executors/threadDump,null,AVAILABLE,@Spark}
INFO [main] - Started o.s.j.s.ServletContextHandler@62679465{/executors/threadDump/json,null,AVAILABLE,@Spark}
INFO [main] - Started o.s.j.s.ServletContextHandler@6a988392{/static,null,AVAILABLE,@Spark}
INFO [main] - Started o.s.j.s.ServletContextHandler@7c22d4f{/,null,AVAILABLE,@Spark}
INFO [main] - Started o.s.j.s.ServletContextHandler@5f59185e{/api,null,AVAILABLE,@Spark}
INFO [main] - Started o.s.j.s.ServletContextHandler@46e8a539{/jobs/job/kill,null,AVAILABLE,@Spark}
INFO [main] - Started o.s.j.s.ServletContextHandler@495083a0{/stages/stage/kill,null,AVAILABLE,@Spark}
INFO [main] - Bound SparkUI to 0.0.0.0, and started at http://zkx:4040
INFO [main] - Starting executor ID driver on host localhost
INFO [main] - Successfully started service 'org.apache.spark.network.netty.NettyBlockTransferService' on port 62427.
INFO [main] - Server created on zkx:62427
INFO [main] - Using org.apache.spark.storage.RandomBlockReplicationPolicy for block replication policy
INFO [main] - Registering BlockManager BlockManagerId(driver, zkx, 62427, None)
INFO [dispatcher-event-loop-0] - Registering block manager zkx:62427 with 1967.4 MB RAM, BlockManagerId(driver, zkx, 62427, None)
INFO [main] - Registered BlockManager BlockManagerId(driver, zkx, 62427, None)
INFO [main] - Initialized BlockManager: BlockManagerId(driver, zkx, 62427, None)
INFO [main] - Started o.s.j.s.ServletContextHandler@1ce93c18{/metrics/json,null,AVAILABLE,@Spark}
INFO [main] - start to write nebula vertices
INFO [main] - Setting hive.metastore.warehouse.dir ('null') to the value of spark.sql.warehouse.dir ('file:/D:/software/nebula-spark-connector/spark-warehouse').
INFO [main] - Warehouse path is 'file:/D:/software/nebula-spark-connector/spark-warehouse'.
INFO [main] - Started o.s.j.s.ServletContextHandler@1d3e6d34{/SQL,null,AVAILABLE,@Spark}
INFO [main] - Started o.s.j.s.ServletContextHandler@6eafb10e{/SQL/json,null,AVAILABLE,@Spark}
INFO [main] - Started o.s.j.s.ServletContextHandler@3bc735b3{/SQL/execution,null,AVAILABLE,@Spark}
INFO [main] - Started o.s.j.s.ServletContextHandler@577f9109{/SQL/execution/json,null,AVAILABLE,@Spark}
INFO [main] - Started o.s.j.s.ServletContextHandler@2234078{/static/sql,null,AVAILABLE,@Spark}
INFO [main] - Registered StateStoreCoordinator endpoint
INFO [main] - Pruning directories with:
INFO [main] - Post-Scan Filters:
INFO [main] - Output Data Schema: struct<value: string>
INFO [main] - Pushed Filters:
INFO [main] - Code generated in 341.3348 ms
INFO [main] - Block broadcast_0 stored as values in memory (estimated size 220.5 KB, free 1967.2 MB)
INFO [main] - Block broadcast_0_piece0 stored as bytes in memory (estimated size 20.7 KB, free 1967.2 MB)
INFO [dispatcher-event-loop-1] - Added broadcast_0_piece0 in memory on zkx:62427 (size: 20.7 KB, free: 1967.4 MB)
INFO [main] - Created broadcast 0 from json at NebulaSparkWriterExample.scala:146
INFO [main] - Planning scan with bin packing, max size: 4194857 bytes, open cost is considered as scanning 4194304 bytes.
INFO [main] - Starting job: json at NebulaSparkWriterExample.scala:146
INFO [dag-scheduler-event-loop] - Got job 0 (json at NebulaSparkWriterExample.scala:146) with 1 output partitions
INFO [dag-scheduler-event-loop] - Final stage: ResultStage 0 (json at NebulaSparkWriterExample.scala:146)
INFO [dag-scheduler-event-loop] - Parents of final stage: List()
INFO [dag-scheduler-event-loop] - Missing parents: List()
INFO [dag-scheduler-event-loop] - Submitting ResultStage 0 (MapPartitionsRDD[2] at json at NebulaSparkWriterExample.scala:146), which has no missing parents
INFO [dag-scheduler-event-loop] - Block broadcast_1 stored as values in memory (estimated size 9.8 KB, free 1967.2 MB)
INFO [dag-scheduler-event-loop] - Block broadcast_1_piece0 stored as bytes in memory (estimated size 5.4 KB, free 1967.1 MB)
INFO [dispatcher-event-loop-0] - Added broadcast_1_piece0 in memory on zkx:62427 (size: 5.4 KB, free: 1967.4 MB)
INFO [dag-scheduler-event-loop] - Created broadcast 1 from broadcast at DAGScheduler.scala:1161
INFO [dag-scheduler-event-loop] - Submitting 1 missing tasks from ResultStage 0 (MapPartitionsRDD[2] at json at NebulaSparkWriterExample.scala:146) (first 15 tasks are for partitions Vector(0))
INFO [dag-scheduler-event-loop] - Adding task set 0.0 with 1 tasks
INFO [dispatcher-event-loop-1] - Starting task 0.0 in stage 0.0 (TID 0, localhost, executor driver, partition 0, PROCESS_LOCAL, 8292 bytes)
INFO [Executor task launch worker for task 0] - Running task 0.0 in stage 0.0 (TID 0)
INFO [Executor task launch worker for task 0] - Reading File path: file:///D:/software/nebula-spark-connector/example/src/main/resources/vertex, range: 0-553, partition values: [empty row]
INFO [Executor task launch worker for task 0] - Code generated in 13.1198 ms
INFO [Executor task launch worker for task 0] - Finished task 0.0 in stage 0.0 (TID 0). 1456 bytes result sent to driver
INFO [task-result-getter-0] - Finished task 0.0 in stage 0.0 (TID 0) in 211 ms on localhost (executor driver) (1/1)
INFO [task-result-getter-0] - Removed TaskSet 0.0, whose tasks have all completed, from pool
INFO [dag-scheduler-event-loop] - ResultStage 0 (json at NebulaSparkWriterExample.scala:146) finished in 0.314 s
INFO [main] - Job 0 finished: json at NebulaSparkWriterExample.scala:146, took 0.352954 s
INFO [main] - Pruning directories with:
INFO [main] - Post-Scan Filters:
INFO [main] - Output Data Schema: struct<age: bigint, id: bigint>
INFO [main] - Pushed Filters:
INFO [main] - Code generated in 14.6206 ms
INFO [main] - Code generated in 14.3205 ms
INFO [main] - Block broadcast_2 stored as values in memory (estimated size 220.5 KB, free 1966.9 MB)
INFO [main] - Block broadcast_2_piece0 stored as bytes in memory (estimated size 20.7 KB, free 1966.9 MB)
INFO [dispatcher-event-loop-0] - Added broadcast_2_piece0 in memory on zkx:62427 (size: 20.7 KB, free: 1967.4 MB)
INFO [main] - Created broadcast 2 from show at NebulaSparkWriterExample.scala:147
INFO [main] - Planning scan with bin packing, max size: 4194857 bytes, open cost is considered as scanning 4194304 bytes.
INFO [main] - Starting job: show at NebulaSparkWriterExample.scala:147
INFO [dag-scheduler-event-loop] - Got job 1 (show at NebulaSparkWriterExample.scala:147) with 1 output partitions
INFO [dag-scheduler-event-loop] - Final stage: ResultStage 1 (show at NebulaSparkWriterExample.scala:147)
INFO [dag-scheduler-event-loop] - Parents of final stage: List()
INFO [dag-scheduler-event-loop] - Missing parents: List()
INFO [dag-scheduler-event-loop] - Submitting ResultStage 1 (MapPartitionsRDD[6] at show at NebulaSparkWriterExample.scala:147), which has no missing parents
INFO [dag-scheduler-event-loop] - Block broadcast_3 stored as values in memory (estimated size 10.8 KB, free 1966.9 MB)
INFO [dag-scheduler-event-loop] - Block broadcast_3_piece0 stored as bytes in memory (estimated size 5.8 KB, free 1966.9 MB)
INFO [dispatcher-event-loop-1] - Added broadcast_3_piece0 in memory on zkx:62427 (size: 5.8 KB, free: 1967.3 MB)
INFO [dag-scheduler-event-loop] - Created broadcast 3 from broadcast at DAGScheduler.scala:1161
INFO [dag-scheduler-event-loop] - Submitting 1 missing tasks from ResultStage 1 (MapPartitionsRDD[6] at show at NebulaSparkWriterExample.scala:147) (first 15 tasks are for partitions Vector(0))
INFO [dag-scheduler-event-loop] - Adding task set 1.0 with 1 tasks
INFO [dispatcher-event-loop-0] - Starting task 0.0 in stage 1.0 (TID 1, localhost, executor driver, partition 0, PROCESS_LOCAL, 8292 bytes)
INFO [Executor task launch worker for task 1] - Running task 0.0 in stage 1.0 (TID 1)
INFO [Executor task launch worker for task 1] - Reading File path: file:///D:/software/nebula-spark-connector/example/src/main/resources/vertex, range: 0-553, partition values: [empty row]
INFO [Executor task launch worker for task 1] - Code generated in 13.8182 ms
INFO [Executor task launch worker for task 1] - Finished task 0.0 in stage 1.0 (TID 1). 1305 bytes result sent to driver
INFO [task-result-getter-1] - Finished task 0.0 in stage 1.0 (TID 1) in 79 ms on localhost (executor driver) (1/1)
INFO [task-result-getter-1] - Removed TaskSet 1.0, whose tasks have all completed, from pool
INFO [dag-scheduler-event-loop] - ResultStage 1 (show at NebulaSparkWriterExample.scala:147) finished in 0.101 s
INFO [main] - Job 1 finished: show at NebulaSparkWriterExample.scala:147, took 0.105949 s
+---+---+
| id|age|
+---+---+
| 12| 20|
| 13| 21|
| 14| 22|
| 15| 23|
| 16| 24|
| 17| 25|
| 18| 26|
| 19| 27|
| 20| 28|
| 21| 29|
+---+---+
INFO [main] - enableMetaSSL is true, then enableGraphSSL will be invalid for now.
INFO [main] - enableMetaSSL is true, then enableGraphSSL will be invalid for now.
Exception in thread "main" java.lang.AssertionError: assertion failed: the maximum number of statements for Nebula is 512
at scala.Predef$.assert(Predef.scala:170)
at com.vesoft.nebula.connector.WriteNebulaVertexConfig$WriteVertexConfigBuilder.check(NebulaConfig.scala:396)
at com.vesoft.nebula.connector.WriteNebulaVertexConfig$WriteVertexConfigBuilder.build(NebulaConfig.scala:363)
at com.vesoft.nebula.examples.connector.NebulaSparkWriterExample$.updateVertex(NebulaSparkWriterExample.scala:158)
at com.vesoft.nebula.examples.connector.NebulaSparkWriterExample$.main(NebulaSparkWriterExample.scala:40)
at com.vesoft.nebula.examples.connector.NebulaSparkWriterExample.main(NebulaSparkWriterExample.scala)
INFO [Thread-1] - Invoking stop() from shutdown hook
INFO [Thread-1] - Stopped Spark@36b0fcd5{HTTP/1.1,[http/1.1]}{0.0.0.0:4040}
INFO [Thread-1] - Stopped Spark web UI at http://zkx:4040
INFO [dispatcher-event-loop-1] - MapOutputTrackerMasterEndpoint stopped!
INFO [Thread-1] - MemoryStore cleared
INFO [Thread-1] - BlockManager stopped
INFO [Thread-1] - BlockManagerMaster stopped
INFO [dispatcher-event-loop-1] - OutputCommitCoordinator stopped!
INFO [Thread-1] - Successfully stopped SparkContext
INFO [Thread-1] - Shutdown hook called
INFO [Thread-1] - Deleting directory C:\Users\zkx\AppData\Local\Temp\spark-fae65a7a-8845-42d0-aa87-8e2c5ac358eb
Process finished with exit code 1