Hello @wey,
- the RPC timeout failure happens for all queries executed in llama-index or nebula-python.
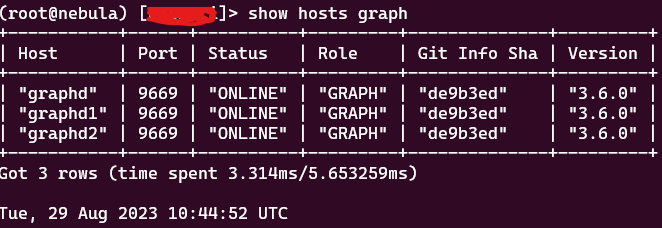
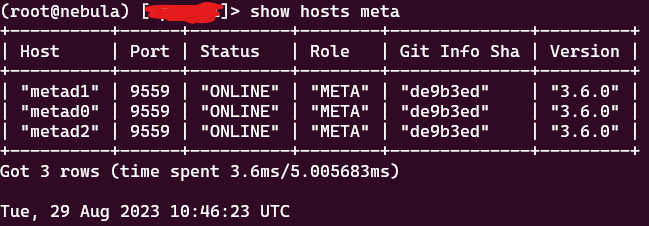
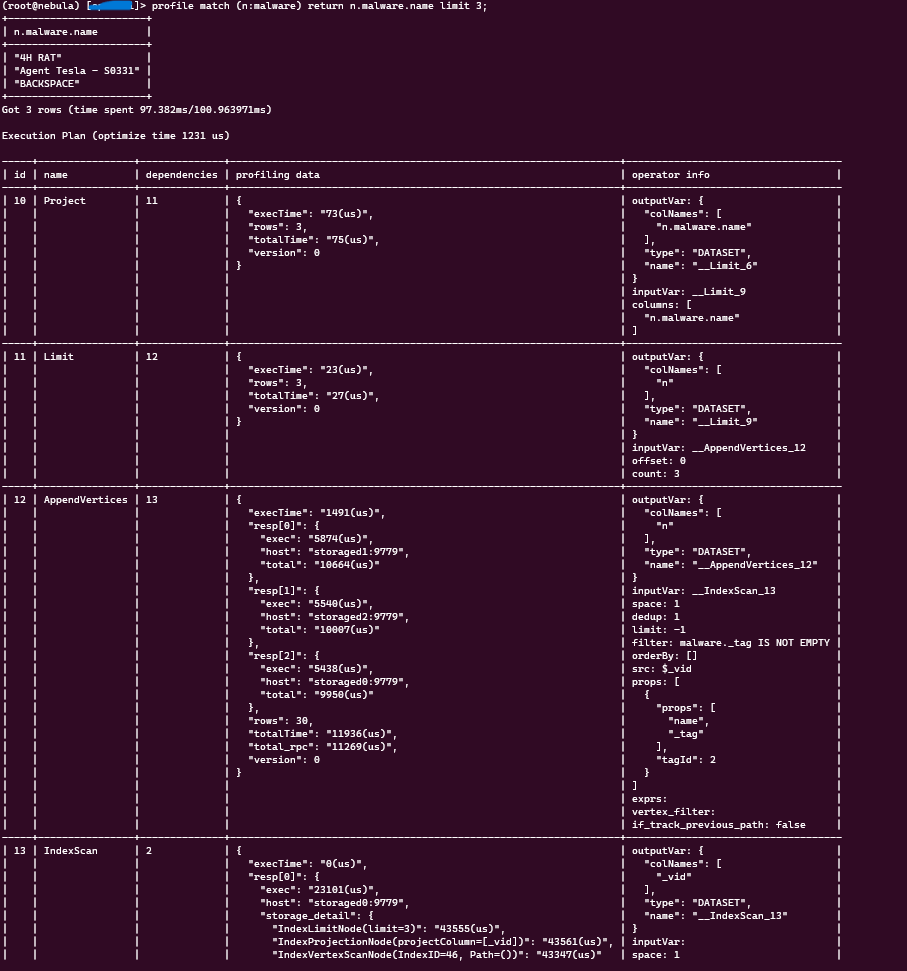
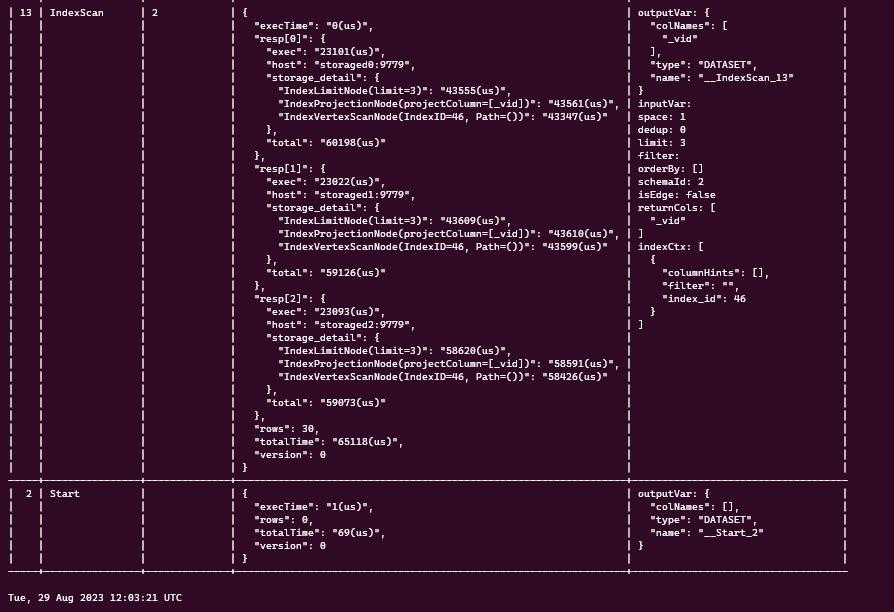
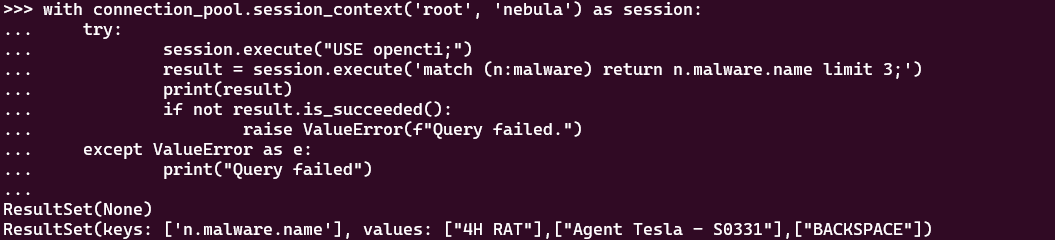
- Running the profile query in nebula console works, and returns the following:
However, running the following code in python
from nebula3.gclient.net import ConnectionPool
from nebula3.Config import Config
from nebula3.Exception import IOErrorException
from nebula3.fbthrift.transport.TTransport import TTransportException
# define a config
config = Config()
config.max_connection_pool_size = 10
# init connection pool
connection_pool = ConnectionPool()
# if the given servers are ok, return true, else return false
ok = connection_pool.init([('127.0.0.1', 9669)], config)
# option 1 control the connection release yourself
# get session from the pool
session = connection_pool.get_session('root', 'nebula')
# select space
session.execute('USE opencti')
# release session
session.release()
# option 2 with session_context, session will be released automatically
with connection_pool.session_context('root', 'nebula') as session:
try:
session.execute('USE opencti')
result = session.execute('profile match (n:malware) return n.malware.name limit 3;')
if result is None:
raise ValueError(f"Query failed.")
if not result.is_succeeded():
raise ValueError(
f"Query failed."
f"Error message: {result.error_msg()}"
)
except (TTransportException, IOErrorException, RuntimeError) as e:
print(
f"Connection issue, try to recreate session pool "
f"Erorr: {e}"
)
raise e
except ValueError as e:
# query failed on db side
print(
f"Query failed."
f"Error message: {e}"
)
raise e
except Exception as e:
# other exceptions
print(
f"Query failed."
f"Error message: {e}"
)
raise e
# close the pool
connection_pool.close()
It returns the timeout error:
The logs don’t log anything specific related to queries related to the timeout, as you can see below:
storaged-stderr.log
I20230828 15:26:23.183328 1 AdminTaskManager.cpp:40] exit AdminTaskManager::init()
I20230828 15:26:23.183528 120 AdminTaskManager.cpp:224] waiting for incoming task
I20230828 15:26:23.340339 1 MemoryUtils.cpp:171] MemoryTracker set static ratio: 0.8
I20230828 15:26:33.502504 69 MetaClient.cpp:3263] Load leader of "storaged0":9779 in 1 space
I20230828 15:26:33.503928 69 MetaClient.cpp:3263] Load leader of "storaged1":9779 in 1 space
I20230828 15:26:33.503968 69 MetaClient.cpp:3263] Load leader of "storaged2":9779 in 1 space
I20230828 15:26:33.503979 69 MetaClient.cpp:3269] Load leader ok
I20230828 15:26:43.527977 69 MetaClient.cpp:3263] Load leader of "storaged0":9779 in 1 space
I20230828 15:26:43.528112 69 MetaClient.cpp:3263] Load leader of "storaged1":9779 in 1 space
I20230828 15:26:43.528128 69 MetaClient.cpp:3263] Load leader of "storaged2":9779 in 1 space
I20230828 15:26:43.528137 69 MetaClient.cpp:3269] Load leader ok
metad-stderr.log
I20230828 15:26:20.882784 1 MetaDaemon.cpp:193] The meta daemon start on "metad0":9559
I20230828 15:26:20.883342 1 JobManager.cpp:88] Not leader, skip reading remaining jobs
I20230828 15:26:20.883716 1 JobManager.cpp:64] JobManager initialized
I20230828 15:26:20.883806 103 JobManager.cpp:150] JobManager::scheduleThread enter
I20230828 15:26:21.572297 129 HBProcessor.cpp:33] Receive heartbeat from "storaged1":9779, role = STORAGE
I20230828 15:26:21.572355 129 HBProcessor.cpp:41] Machine "storaged1":9779 is not registered
I20230828 17:57:20.924661 57 ThriftClientManager-inl.h:67] resolve "metad1":9560 as "172.19.0.7":9560
I20230829 09:14:15.053244 57 ThriftClientManager-inl.h:67] resolve "metad2":9560 as "172.19.0.3":9560
For graphd, it only contains INFO logs no ERRORS logs:
I20230828 15:26:32.722048 67 MetaClient.cpp:3269] Load leader ok
I20230828 15:26:42.741894 67 MetaClient.cpp:3263] Load leader of "storaged0":9779 in 1 space
I20230828 15:26:42.741950 67 MetaClient.cpp:3263] Load leader of "storaged1":9779 in 1 space
I20230828 15:26:42.741958 67 MetaClient.cpp:3263] Load leader of "storaged2":9779 in 1 space
I20230828 15:26:42.741961 67 MetaClient.cpp:3269] Load leader ok
As I mentioned earlier, executing queries through nebula console works completely fine, however, when done through nebula-python or llama-index there is always RPC timeout error regardless of the query.
Any ideas ?