图说天下
2023 年8 月 30 日 05:55
1
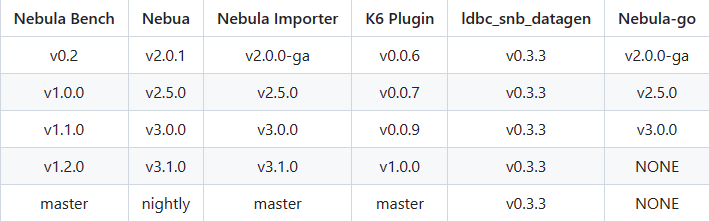
nebula 版本:3.6.0
nebula-importer版本: 4.0(3.1.0)
部署方式:分布式
安装方式:二进制版本
是否上生产环境:N
问题的具体描述
NebulaGraph Bench测试环境搭建
–诊断过程
参考了 nebula-importer导入数据时报错unsupported client version - #5,来自 veezhang
希望脚本在生成配置文件时加个参数,例如v2或者v3, 这样能一键生成对应
同样尝试了降级importer的版本(4.0降到3.1), 执行时报了另外一个错:None into int
最后说明一点: import_config.yaml文件是执行以下命令自动生成的:
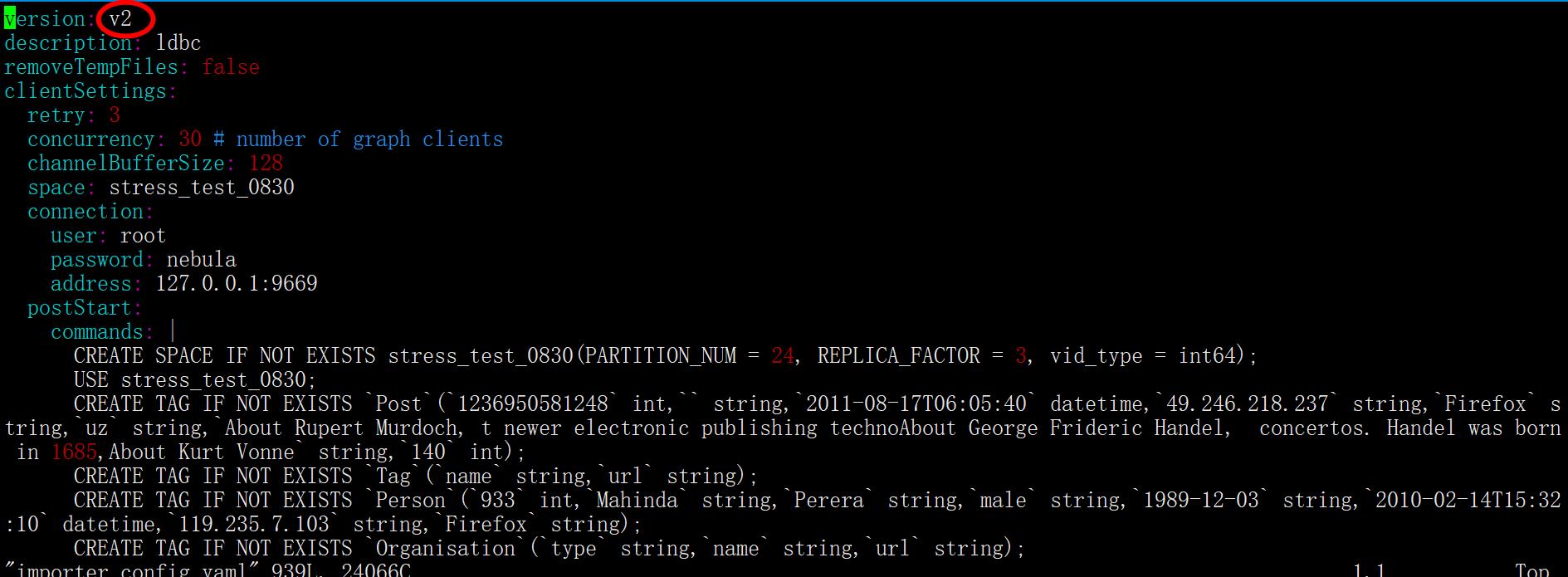
这个命令目前只能生成v2版本的yaml文件,不支持v3或者更高版本。
1 个赞
意见很好,感谢,参数太多确实难用。版本多,不匹配,也令人头大。
suu
2023 年8 月 30 日 06:05
3
bench和importer的版本号要配套。你的importer用的v3.1.0的话,bench是v1.2.0的吗?
1 个赞
suu
2023 年8 月 30 日 06:11
5
你可以贴几张你自己的图片给大家看看,说不定有提示信息你自己没看到。
图说天下
2023 年8 月 30 日 06:18
6
下面的截图是将importer版本降为3.1后执行脚本出错信息
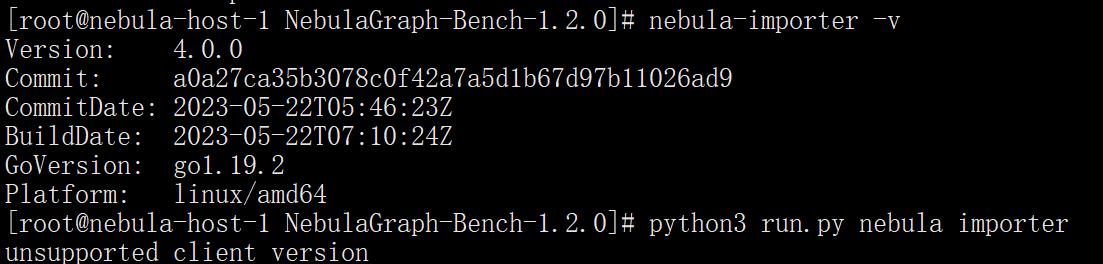
下面的截图是更换成4.0版本的importer后,执行脚本出错
脚本自动生成的配置文件为v2版本
打开 importer 的配置文件,然后随便找一个 index 是 None 的点,上面有一个 CSV 文件的路径。
比如 xxxx/xxxx/tag_hasType_tagclass.csvhead xxxx/xxxx/tag_hasType_tagclass_header.csv 看一下内容是什么?
bench 里,最开始初始化 index 是 None,然后会找 header 文件,然后遍历 header 文件第一行,如果有 .id 的列,就赋值 index。看上去是 header 文件不太对。
你 LDBC 的 csv 是用 bench 生成的么?
suu
2023 年8 月 30 日 08:33
9
我之前安装的bench1.2.0,importer4.0.0,和你报一样的错误“unsupported client version”,但是我换成3.1.0以后就解决了
图说天下
2023 年8 月 31 日 08:58
10
head -1 /nebula_test/test/perf_test/NebulaGraph-Bench-1.2.0/target/data/test_data/social_network/dynamic/comment_header.csv
1236950581249|2011-08-17T14:26:59|92.39.58.88|Chrome|yes|3
不带header的csv第一行:
1236950581250|2011-08-17T11:10:21|213.55.127.9|Internet Explorer|thanks|6
好像没啥差别啊。 难道是生成的数据有问题 ?
图说天下:
comment_header
> head -1 comment_header.csv add_nebula_dashboard [da1850f] modified untracked
id|creationDate|locationIP|browserUsed|content|length
看上去是 header 的那个头不见了,所以根据 header 生产的 importer 的配置是错误的
或者全部重新生成数据。
图说天下
2023 年9 月 1 日 01:56
12
很奇怪,我重新生成测试数据后,没有发现带header的csv文件,难道是命令用错了?
还有一个命令是
这条命令执行完 会生成带header的csv
python3 run.py data -s 10 就可以生成带 header 的,不需要 python3 run.py data -os
你可以用 bench 的 master + importer v3.2.0
图说天下
2023 年9 月 1 日 02:06
14
重新检查了一下生成的文件,确实有带header的csv
图说天下
2023 年9 月 1 日 03:13
15
还是有问题。
用了bench的master版本 + importer 3.1版本,执行还是出错:
2023/09/01 11:11:46 --- START OF NEBULA IMPORTER ---
2023/09/01 11:11:47 Client(0) fails to execute commands (CREATE SPACE IF NOT EXISTS stress_test_0901(PARTITION_NUM = 24, REPLICA_FACTOR = 3, vid_type = int64);
USE stress_test_0901;
CREATE TAG IF NOT EXISTS `Post`(`imageFile` string,`creationDate` string,`locationIP` string,`browserUsed` string,`language` string,`content` string,`length` int);
CREATE TAG IF NOT EXISTS `Tagclass`(`name` string,`url` string);
CREATE TAG IF NOT EXISTS `Organisation`(`type` string,`name` string,`url` string);
CREATE TAG IF NOT EXISTS `Tag`(`name` string,`url` string);
CREATE TAG IF NOT EXISTS `Forum`(`title` string,`creationDate` string);
CREATE TAG IF NOT EXISTS `Place`(`name` string,`url` string,`type` string);
CREATE TAG IF NOT EXISTS `Comment`(`creationDate` string,`locationIP` string,`browserUsed` string,`content` string,`length` int);
CREATE TAG IF NOT EXISTS `Person`(`firstName` string,`lastName` string,`gender` string,`birthday` string,`creationDate` string,`locationIP` string,`browserUsed` string);
CREATE EDGE IF NOT EXISTS `CONTAINER_OF`();
CREATE EDGE IF NOT EXISTS `HAS_CREATOR`();
CREATE EDGE IF NOT EXISTS `STUDY_AT`(`classYear` int);
CREATE EDGE IF NOT EXISTS `IS_LOCATED_IN`();
CREATE EDGE IF NOT EXISTS `REPLY_OF`();
CREATE EDGE IF NOT EXISTS `KNOWS`(`creationDate` string);
CREATE EDGE IF NOT EXISTS `WORK_AT`(`workFrom` int);
CREATE EDGE IF NOT EXISTS `HAS_MEMBER`(`joinDate` string);
CREATE EDGE IF NOT EXISTS `HAS_TYPE`();
CREATE EDGE IF NOT EXISTS `HAS_INTEREST`();
CREATE EDGE IF NOT EXISTS `IS_PART_OF`();
CREATE EDGE IF NOT EXISTS `IS_SUBCLASS_OF`();
CREATE EDGE IF NOT EXISTS `HAS_TAG`();
CREATE EDGE IF NOT EXISTS `HAS_MODERATOR`();
CREATE EDGE IF NOT EXISTS `LIKES`(`creationDate` string);
CREATE TAG INDEX IF NOT EXISTS `person_first_name_idx` on `Person`(firstName(10));
CREATE EDGE INDEX IF NOT EXISTS `like_creationDate_idx` on `LIKES`(creationDate);
), response error code: -1005, message: Invalid param!
2023/09/01 11:11:48 --- END OF NEBULA IMPORTER ---
图说天下
2023 年9 月 1 日 03:16
16
为了节省时间,我是把bench 1.2的target目录打包成一个tgz文件,然后直接在bench 的master版本目录下解压,是否还需要复制其他文件 ?
图说天下
2023 年9 月 1 日 03:22
17
改用3.2版本的importer,还是有错:
2023/09/01 11:20:37 --- START OF NEBULA IMPORTER ---
2023/09/01 11:20:37 [INFO] config.go:393: Failed data path: err/data/Comment.csv/comment.csv
2023/09/01 11:20:37 [INFO] config.go:399: find file: /nebula_test/test/perf_test/NebulaGraph-Bench-master/target/data/test_data/social_network/dynamic/comment.csv
2023/09/01 11:20:37 [INFO] config.go:393: Failed data path: err/data/Forum.csv/forum.csv
2023/09/01 11:20:37 [INFO] config.go:399: find file: /nebula_test/test/perf_test/NebulaGraph-Bench-master/target/data/test_data/social_network/dynamic/forum.csv
2023/09/01 11:20:37 [INFO] config.go:393: Failed data path: err/data/Person.csv/person.csv
2023/09/01 11:20:37 [INFO] config.go:399: find file: /nebula_test/test/perf_test/NebulaGraph-Bench-master/target/data/test_data/social_network/dynamic/person.csv
2023/09/01 11:20:37 [INFO] config.go:393: Failed data path: err/data/Post.csv/post.csv
2023/09/01 11:20:37 [INFO] config.go:399: find file: /nebula_test/test/perf_test/NebulaGraph-Bench-master/target/data/test_data/social_network/dynamic/post.csv
2023/09/01 11:20:37 [INFO] config.go:393: Failed data path: err/data/Organisation.csv/organisation.csv
2023/09/01 11:20:37 [INFO] config.go:399: find file: /nebula_test/test/perf_test/NebulaGraph-Bench-master/target/data/test_data/social_network/static/organisation.csv
2023/09/01 11:20:37 [INFO] config.go:393: Failed data path: err/data/Place.csv/place.csv
2023/09/01 11:20:37 [INFO] config.go:399: find file: /nebula_test/test/perf_test/NebulaGraph-Bench-master/target/data/test_data/social_network/static/place.csv
2023/09/01 11:20:37 [INFO] config.go:393: Failed data path: err/data/Tag.csv/tag.csv
2023/09/01 11:20:37 [INFO] config.go:399: find file: /nebula_test/test/perf_test/NebulaGraph-Bench-master/target/data/test_data/social_network/static/tag.csv
2023/09/01 11:20:37 [INFO] config.go:393: Failed data path: err/data/Tagclass.csv/tagclass.csv
2023/09/01 11:20:37 [INFO] config.go:399: find file: /nebula_test/test/perf_test/NebulaGraph-Bench-master/target/data/test_data/social_network/static/tagclass.csv
2023/09/01 11:20:37 [INFO] config.go:393: Failed data path: err/data/IS_LOCATED_IN.csv/person_isLocatedIn_place.csv
2023/09/01 11:20:37 [INFO] config.go:399: find file: /nebula_test/test/perf_test/NebulaGraph-Bench-master/target/data/test_data/social_network/dynamic/person_isLocatedIn_place.csv
2023/09/01 11:20:37 [INFO] config.go:393: Failed data path: err/data/KNOWS.csv/person_knows_person.csv
2023/09/01 11:20:37 [INFO] config.go:399: find file: /nebula_test/test/perf_test/NebulaGraph-Bench-master/target/data/test_data/social_network/dynamic/person_knows_person.csv
2023/09/01 11:20:37 [INFO] config.go:393: Failed data path: err/data/LIKES.csv/person_likes_comment.csv
2023/09/01 11:20:37 [INFO] config.go:399: find file: /nebula_test/test/perf_test/NebulaGraph-Bench-master/target/data/test_data/social_network/dynamic/person_likes_comment.csv
2023/09/01 11:20:37 [INFO] config.go:393: Failed data path: err/data/LIKES.csv/person_likes_post.csv
2023/09/01 11:20:37 [INFO] config.go:399: find file: /nebula_test/test/perf_test/NebulaGraph-Bench-master/target/data/test_data/social_network/dynamic/person_likes_post.csv
2023/09/01 11:20:37 [INFO] config.go:393: Failed data path: err/data/HAS_CREATOR.csv/comment_hasCreator_person.csv
2023/09/01 11:20:37 [INFO] config.go:399: find file: /nebula_test/test/perf_test/NebulaGraph-Bench-master/target/data/test_data/social_network/dynamic/comment_hasCreator_person.csv
2023/09/01 11:20:37 [INFO] config.go:393: Failed data path: err/data/HAS_TAG.csv/comment_hasTag_tag.csv
2023/09/01 11:20:37 [INFO] config.go:399: find file: /nebula_test/test/perf_test/NebulaGraph-Bench-master/target/data/test_data/social_network/dynamic/comment_hasTag_tag.csv
2023/09/01 11:20:37 [INFO] config.go:393: Failed data path: err/data/IS_LOCATED_IN.csv/comment_isLocatedIn_place.csv
2023/09/01 11:20:37 [INFO] config.go:399: find file: /nebula_test/test/perf_test/NebulaGraph-Bench-master/target/data/test_data/social_network/dynamic/comment_isLocatedIn_place.csv
2023/09/01 11:20:37 [INFO] config.go:393: Failed data path: err/data/REPLY_OF.csv/comment_replyOf_comment.csv
2023/09/01 11:20:37 [INFO] config.go:399: find file: /nebula_test/test/perf_test/NebulaGraph-Bench-master/target/data/test_data/social_network/dynamic/comment_replyOf_comment.csv
2023/09/01 11:20:37 [INFO] config.go:393: Failed data path: err/data/REPLY_OF.csv/comment_replyOf_post.csv
2023/09/01 11:20:37 [INFO] config.go:399: find file: /nebula_test/test/perf_test/NebulaGraph-Bench-master/target/data/test_data/social_network/dynamic/comment_replyOf_post.csv
2023/09/01 11:20:37 [INFO] config.go:393: Failed data path: err/data/CONTAINER_OF.csv/forum_containerOf_post.csv
2023/09/01 11:20:37 [INFO] config.go:399: find file: /nebula_test/test/perf_test/NebulaGraph-Bench-master/target/data/test_data/social_network/dynamic/forum_containerOf_post.csv
2023/09/01 11:20:37 [INFO] config.go:393: Failed data path: err/data/HAS_MEMBER.csv/forum_hasMember_person.csv
2023/09/01 11:20:37 [INFO] config.go:399: find file: /nebula_test/test/perf_test/NebulaGraph-Bench-master/target/data/test_data/social_network/dynamic/forum_hasMember_person.csv
2023/09/01 11:20:37 [INFO] config.go:393: Failed data path: err/data/HAS_MODERATOR.csv/forum_hasModerator_person.csv
2023/09/01 11:20:37 [INFO] config.go:399: find file: /nebula_test/test/perf_test/NebulaGraph-Bench-master/target/data/test_data/social_network/dynamic/forum_hasModerator_person.csv
2023/09/01 11:20:37 [INFO] config.go:393: Failed data path: err/data/HAS_TAG.csv/forum_hasTag_tag.csv
2023/09/01 11:20:37 [INFO] config.go:399: find file: /nebula_test/test/perf_test/NebulaGraph-Bench-master/target/data/test_data/social_network/dynamic/forum_hasTag_tag.csv
2023/09/01 11:20:37 [INFO] config.go:393: Failed data path: err/data/HAS_INTEREST.csv/person_hasInterest_tag.csv
2023/09/01 11:20:37 [INFO] config.go:399: find file: /nebula_test/test/perf_test/NebulaGraph-Bench-master/target/data/test_data/social_network/dynamic/person_hasInterest_tag.csv
2023/09/01 11:20:37 [INFO] config.go:393: Failed data path: err/data/STUDY_AT.csv/person_studyAt_organisation.csv
2023/09/01 11:20:37 [INFO] config.go:399: find file: /nebula_test/test/perf_test/NebulaGraph-Bench-master/target/data/test_data/social_network/dynamic/person_studyAt_organisation.csv
2023/09/01 11:20:37 [INFO] config.go:393: Failed data path: err/data/WORK_AT.csv/person_workAt_organisation.csv
2023/09/01 11:20:37 [INFO] config.go:399: find file: /nebula_test/test/perf_test/NebulaGraph-Bench-master/target/data/test_data/social_network/dynamic/person_workAt_organisation.csv
2023/09/01 11:20:37 [INFO] config.go:393: Failed data path: err/data/HAS_CREATOR.csv/post_hasCreator_person.csv
2023/09/01 11:20:37 [INFO] config.go:399: find file: /nebula_test/test/perf_test/NebulaGraph-Bench-master/target/data/test_data/social_network/dynamic/post_hasCreator_person.csv
2023/09/01 11:20:37 [INFO] config.go:393: Failed data path: err/data/HAS_TAG.csv/post_hasTag_tag.csv
2023/09/01 11:20:37 [INFO] config.go:399: find file: /nebula_test/test/perf_test/NebulaGraph-Bench-master/target/data/test_data/social_network/dynamic/post_hasTag_tag.csv
2023/09/01 11:20:37 [INFO] config.go:393: Failed data path: err/data/IS_LOCATED_IN.csv/post_isLocatedIn_place.csv
2023/09/01 11:20:37 [INFO] config.go:399: find file: /nebula_test/test/perf_test/NebulaGraph-Bench-master/target/data/test_data/social_network/dynamic/post_isLocatedIn_place.csv
2023/09/01 11:20:37 [INFO] config.go:393: Failed data path: err/data/IS_LOCATED_IN.csv/organisation_isLocatedIn_place.csv
2023/09/01 11:20:37 [INFO] config.go:399: find file: /nebula_test/test/perf_test/NebulaGraph-Bench-master/target/data/test_data/social_network/static/organisation_isLocatedIn_place.csv
2023/09/01 11:20:37 [INFO] config.go:393: Failed data path: err/data/IS_PART_OF.csv/place_isPartOf_place.csv
2023/09/01 11:20:37 [INFO] config.go:399: find file: /nebula_test/test/perf_test/NebulaGraph-Bench-master/target/data/test_data/social_network/static/place_isPartOf_place.csv
2023/09/01 11:20:37 [INFO] config.go:393: Failed data path: err/data/IS_SUBCLASS_OF.csv/tagclass_isSubclassOf_tagclass.csv
2023/09/01 11:20:37 [INFO] config.go:399: find file: /nebula_test/test/perf_test/NebulaGraph-Bench-master/target/data/test_data/social_network/static/tagclass_isSubclassOf_tagclass.csv
2023/09/01 11:20:37 [INFO] config.go:393: Failed data path: err/data/HAS_TYPE.csv/tag_hasType_tagclass.csv
2023/09/01 11:20:37 [INFO] config.go:399: find file: /nebula_test/test/perf_test/NebulaGraph-Bench-master/target/data/test_data/social_network/static/tag_hasType_tagclass.csv
2023/09/01 11:20:38 Client(0) fails to execute commands (CREATE SPACE IF NOT EXISTS stress_test_0901(PARTITION_NUM = 24, REPLICA_FACTOR = 3, vid_type = int64);
USE stress_test_0901;
CREATE TAG IF NOT EXISTS `Tag`(`name` string,`url` string);
CREATE TAG IF NOT EXISTS `Person`(`firstName` string,`lastName` string,`gender` string,`birthday` string,`creationDate` string,`locationIP` string,`browserUsed` string);
CREATE TAG IF NOT EXISTS `Post`(`imageFile` string,`creationDate` string,`locationIP` string,`browserUsed` string,`language` string,`content` string,`length` int);
CREATE TAG IF NOT EXISTS `Comment`(`creationDate` string,`locationIP` string,`browserUsed` string,`content` string,`length` int);
CREATE TAG IF NOT EXISTS `Organisation`(`type` string,`name` string,`url` string);
CREATE TAG IF NOT EXISTS `Place`(`name` string,`url` string,`type` string);
CREATE TAG IF NOT EXISTS `Forum`(`title` string,`creationDate` string);
CREATE TAG IF NOT EXISTS `Tagclass`(`name` string,`url` string);
CREATE EDGE IF NOT EXISTS `HAS_MODERATOR`();
CREATE EDGE IF NOT EXISTS `STUDY_AT`(`classYear` int);
CREATE EDGE IF NOT EXISTS `IS_PART_OF`();
CREATE EDGE IF NOT EXISTS `IS_SUBCLASS_OF`();
CREATE EDGE IF NOT EXISTS `LIKES`(`creationDate` string);
CREATE EDGE IF NOT EXISTS `HAS_TYPE`();
CREATE EDGE IF NOT EXISTS `HAS_MEMBER`(`joinDate` string);
CREATE EDGE IF NOT EXISTS `WORK_AT`(`workFrom` int);
CREATE EDGE IF NOT EXISTS `KNOWS`(`creationDate` string);
CREATE EDGE IF NOT EXISTS `REPLY_OF`();
CREATE EDGE IF NOT EXISTS `CONTAINER_OF`();
CREATE EDGE IF NOT EXISTS `HAS_INTEREST`();
CREATE EDGE IF NOT EXISTS `HAS_CREATOR`();
CREATE EDGE IF NOT EXISTS `IS_LOCATED_IN`();
CREATE EDGE IF NOT EXISTS `HAS_TAG`();
CREATE TAG INDEX IF NOT EXISTS `person_first_name_idx` on `Person`(firstName(10));
CREATE EDGE INDEX IF NOT EXISTS `like_creationDate_idx` on `LIKES`(creationDate);
), response error code: -1005, message: Invalid param!
2023/09/01 11:20:39 --- END OF NEBULA IMPORTER ---
图说天下
2023 年9 月 5 日 06:41
18
重新生成了测试数据,可以导入了,感觉导入速度很慢,建议输出结果加个进度条
现在控制台输出的只能看到: 当前已经导入了多少条记录和网络延时, 用户
。。。。。。
2023/09/05 14:37:32 [INFO] statsmgr.go:89: Done(/nebula_test/test/perf_test/NebulaGraph-Bench-master/target/data/test_data/social_network/dynamic/comment_replyOf_post.csv): Time(5276.01s), Finished(139916314), Failed(0), Read Failed(0), Latency AVG(107412us), Batches Req AVG(111981us), Rows AVG(26519.36/s)
steam
2023 年9 月 5 日 06:46
19
图说天下
2023 年9 月 5 日 06:56
20
还有两个问题:
2)断点续传: 例如有20个csv文件,已经完成了10个,在导入第11个文件的时候 因为
steam
2023 年9 月 5 日 07:23
21
断点续传是 importer 这块的 feature,