exchange 3.5.0
nebula:3.5.0
nebula graph中已经存储了当前的数据,现在我希望对其中的一个tag下的大量节点的某一个属性进行更新,此时我能否在原先parquet的基础上,更新该属性,再将该parquet通过exchange导入graph中?
例如现在我有1亿个person节点,我希望将所有person节点下的age属性增大1岁,能否在源文件上进行修改,再通过exchange导入到nebula graph中?
exchange 3.5.0
nebula:3.5.0
nebula graph中已经存储了当前的数据,现在我希望对其中的一个tag下的大量节点的某一个属性进行更新,此时我能否在原先parquet的基础上,更新该属性,再将该parquet通过exchange导入graph中?
例如现在我有1亿个person节点,我希望将所有person节点下的age属性增大1岁,能否在源文件上进行修改,再通过exchange导入到nebula graph中?
这里是我写错了,exchange用的也是3.5.0版本的。
是将配置文件中的tag.writeMode改成update就可以了吗?那对于需要源文件有什么要求呢?例如我只想要更新age这一个属性,对应的parquet中只有两列vid和age就可以了吗?还是原先的属性都要保留?
如果你的源文件只有 age列的值变化,你可以继续使用insert模式,insert时会将你老数据覆盖的。
用update也可以实现,只要指定vid和age就可以,但update性能没有insert好。
那如果我想要通过一个新文件对内容进行更新,新文件里只有vid和age两列,是不是就需要用update了
是的。
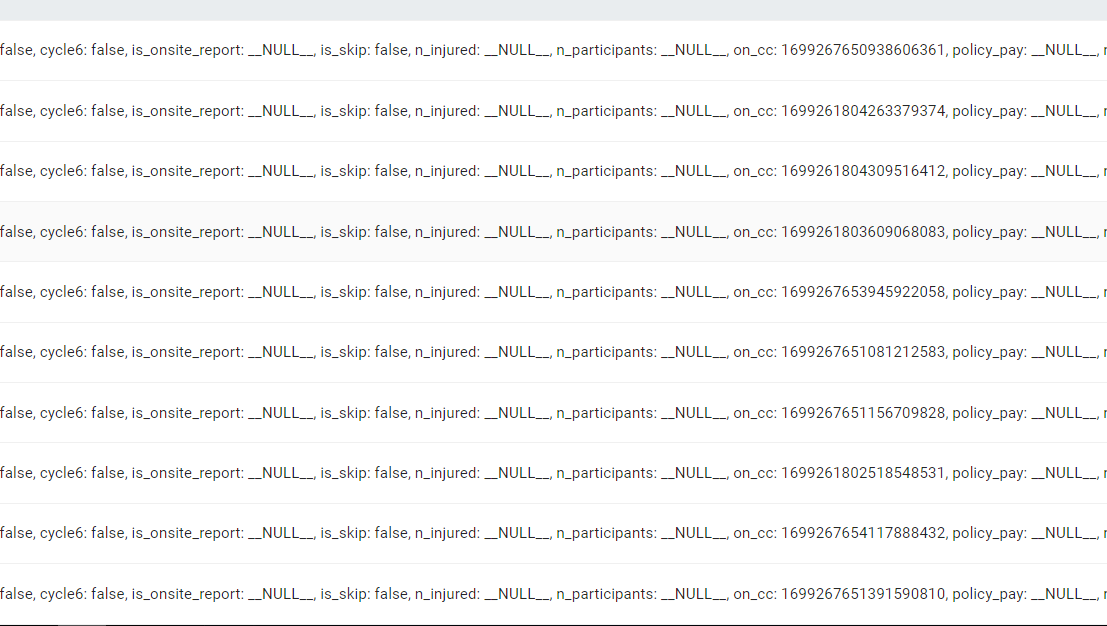
各位大佬们,这里有个问题,我使用update的writeMode去更新tag,使用的更新文件中只有vid和需要更新的属性两列,但是更新完了之后除了更新的属性之外,其他的属性都消失了,这是为啥,是我写的不对吗?这是我的exchange的conf文件,能帮我看看问题在哪吗?
{
# 配置Spark相关
# Spark configuration
spark:{
app:{
name: Nebula Exchange
}
}
# nebula graph相关配置
nebula:{
address:{
graph:[""]
meta:[""]
}
user:root
pswd:
# 指定图空间
space: yc3
connection:{
timeout: 3000
retry: 3
}
execution:{
retry:1
}
error:{
max: 16
output: /tmp/errors
}
rate:{
limit: 1024
timeout: 1000
}
}
tags:[
writeMode : update
{
name: Person
type:{
source:parquet
sink:client
}
path:""
fields:[
cc
]
nebula.fields:[
on_cc
]
writeMode: update
vertex:vid
separator: ","
batch: 256
partition: 16
}
{
name: Car
type:{
source:parquet
sink:client
}
path:""
fields:[
cc
]
nebula.fields:[
on_cc
]
writeMode: update
vertex:vid
separator: ","
batch: 256
partition: 16
}
{
name: Claim
type:{
source:parquet
sink:client
}
path:""
fields:[
cc
]
nebula.fields:[
on_cc
]
writeMode: update
vertex:vid
separator: ","
batch: 256
partition: 16
}
{
name: Phone
type:{
source:parquet
sink:client
}
path:""
fields:[
cc
]
nebula.fields:[
on_cc
]
writeMode: update
vertex:vid
separator: ","
batch: 256
partition: 16
}
]
}
重复提问,以上面的链接回复为准。