Hal
1
-
nebula 版本:社区版3.5.0
-
部署方式:分布式 (3节点)
-
安装方式:RPM
-
是否上生产环境:Y
-
硬件信息
磁盘 1.5T
内存 64G
-
问题的具体描述
问题1:
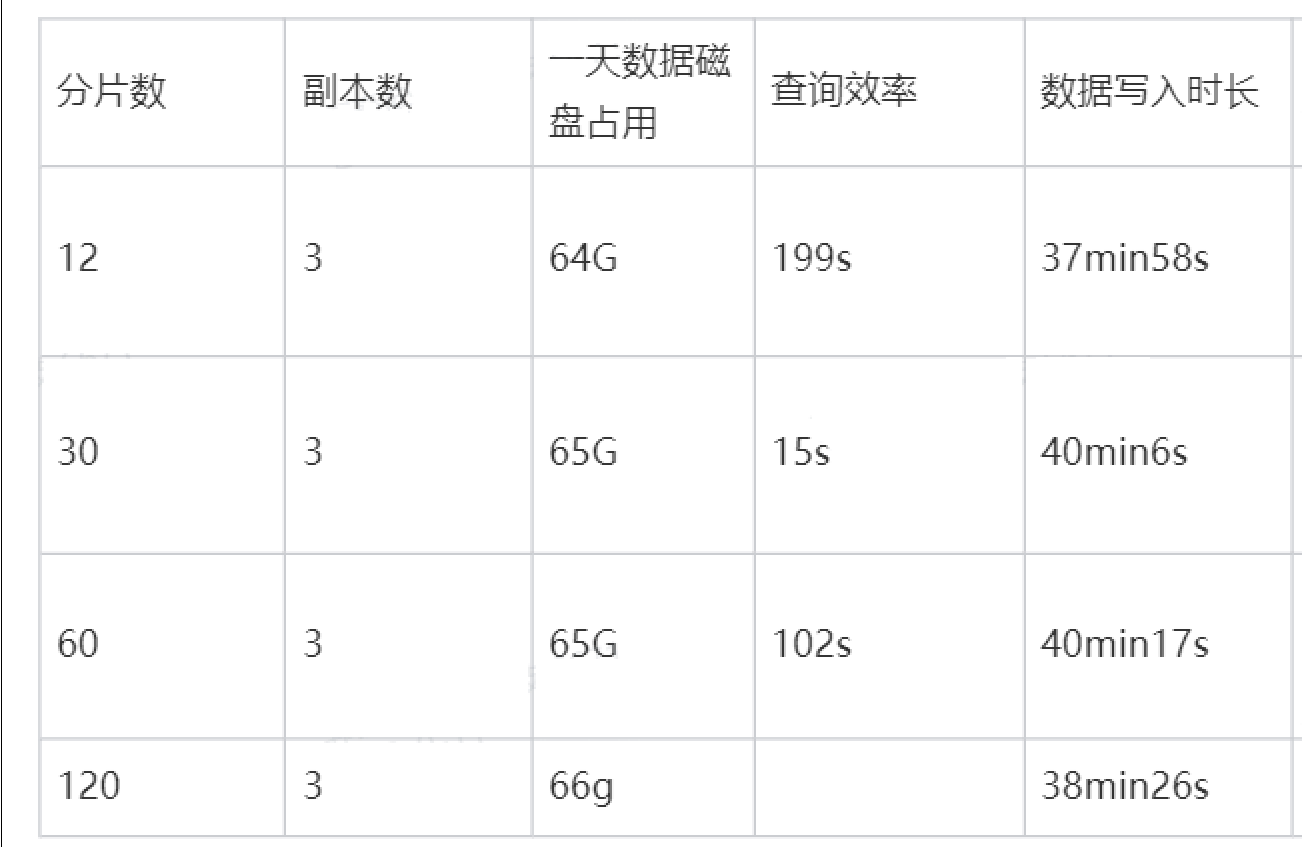
创建了一个120分区3副本的图空间,导入一天数据发现每个节点的硬盘占用64G左右内存,在单机测试的时候使用的是1分区1副本的图空间,半年数据才用了551G,后来降低分区数为60,所占用的磁盘空间仍是那么大
想到了数据在nebula存在存储放大的现象,是因为增加了分区数导致的吗?
我简单做个一个测试,想要观察不同的分区数是否会影响磁盘使用情况,结果显示似乎跟分区数无关,那会是什么原因导致磁盘使用量变得那么大呢 
单机磁盘使用情况(半年数):
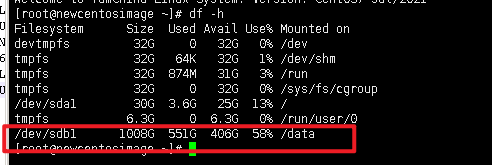
生产环境磁盘使用情况(一天数据):

importer导入成功日志,显示读取的csv文件只有2.2G
一天数据量级:
问题2:
在使用nebula-importer(docker方式部署)导入数据的时候发现随着数据的写入,导入速度越来越慢
求大佬们指导  非常感谢
非常感谢
关于1,我猜是你的vid配置比较大导致;
关于2. 配置参数牵扯比较多,可以看看有没有帮助:
Hal
5
十分感谢,我这边尝试了一下,降低了vid类型的长度后磁盘使用率确实降低了不少,另外我发现在晚上的时候磁盘自己会降下来,请问这是有什么存储机制吗?数据被压缩了吗?
steam
6
1 个赞
Hal
7
好的,非常感谢,还有个小问题,为什么我导入数据完成后手动进行compaction,磁盘使用量并没有下降呢,集群自动进行compaction与手动触发有什么差异吗?
steam
8
磁盘使用量可能是 wal 日志造成的,我摘录了下 gpt 给我的回复:
RocksDB 的 Compaction 过程与 WAL(Write-Ahead Log,预写日志)是独立的,Compaction 不会直接回收 WAL 日志。
WAL 是一种用于数据持久化和恢复的机制,在写入数据之前,RocksDB 会将数据先写入 WAL 日志文件,以确保数据的持久性和一致性。Compaction 则是 RocksDB 中的一项后台任务,它负责对 SST(Sorted String Table)文件进行合并和整理,以优化数据存储和查询性能。
在 Compaction 过程中,RocksDB 会根据一定的策略将多个 SST 文件合并成一个更大的 SST 文件,并删除或清理不再需要的数据块。然而,这个过程与 WAL 日志文件是独立的。Compaction 只关注 SST 文件的合并和整理,不会直接回收或删除 WAL 日志文件。
WAL 日志文件通常会根据预设的大小或时间限制进行轮换和删除。RocksDB 会在 WAL 日志写入一定量的数据后,触发 WAL 日志的切换,并将旧的 WAL 日志文件标记为可回收。一旦没有活跃的读取事务需要使用 WAL 日志中的数据,RocksDB 可以自行决定何时删除旧的 WAL 日志文件。
因此,WAL 日志文件的回收通常由 RocksDB 内部的策略和机制处理,与 Compaction 过程是分开的。
简单来说,你只执行 Compaction 的话,磁盘空间可能不一定大幅度下降,你可以试试调整下 wal 的 ttl 时间,默认是 4 小时,参考这个:Storage 服务配置 - NebulaGraph Database 手册
1 个赞
system
关闭
11
此话题已在最后回复的 7 天后被自动关闭。不再允许新回复。