环境信息:
测试场景,单机部署,8core 32G

测试目的:验证 tag 数量对查询性能是否有影响?
基准场景是:1万个点、10万条边
针对上述场景执行 match 查询,速度很快。
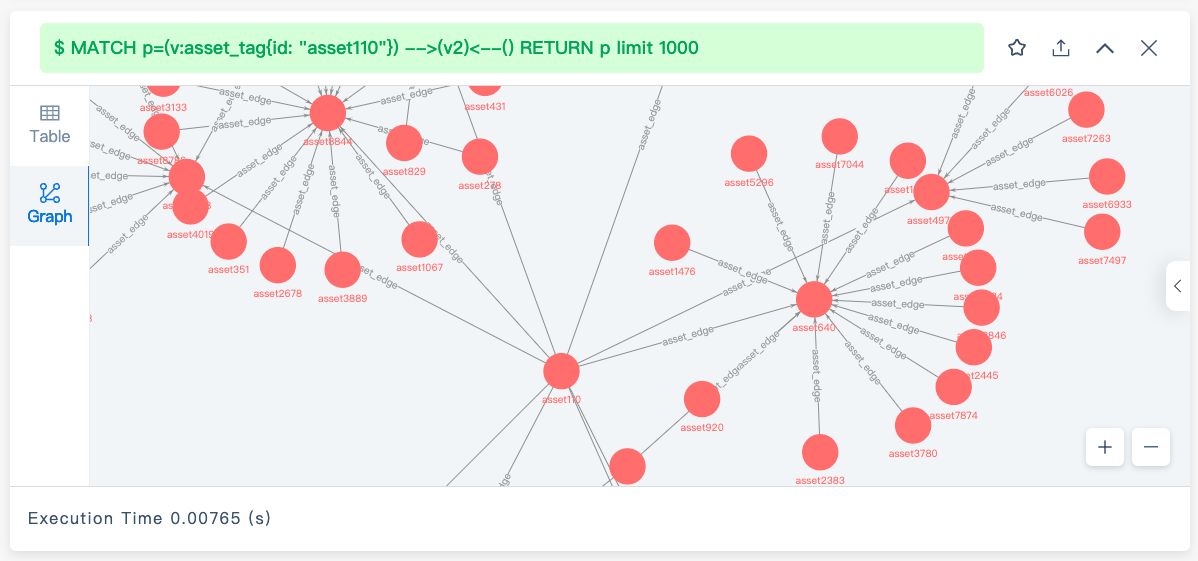
然后模拟添加 10000 个 tag(此时尚未将这些 tag 与点做关联),添加后做相同的查询,此时查询性能下降严重,慢了约 340 倍。
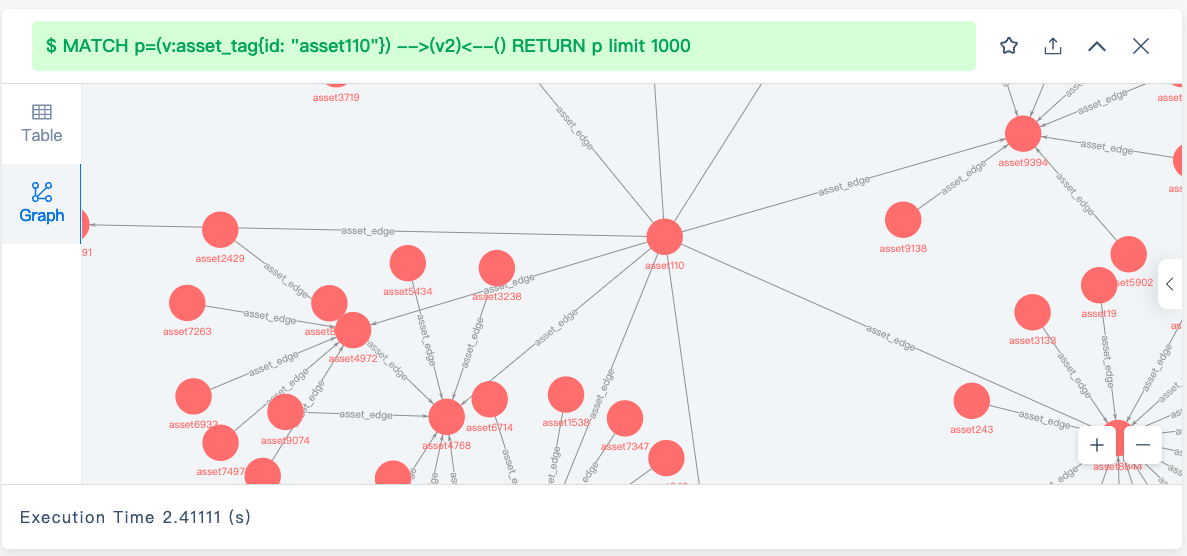
尝试 profile 发现,AppendVertices 算子耗时最多,total_rpc 耗时 1.88s,在这一阶段 storaged 将所有 tag 信息都返回了,这里我的疑问点是:此时这些 tag 尚未关联点,为什么也会返回呢?

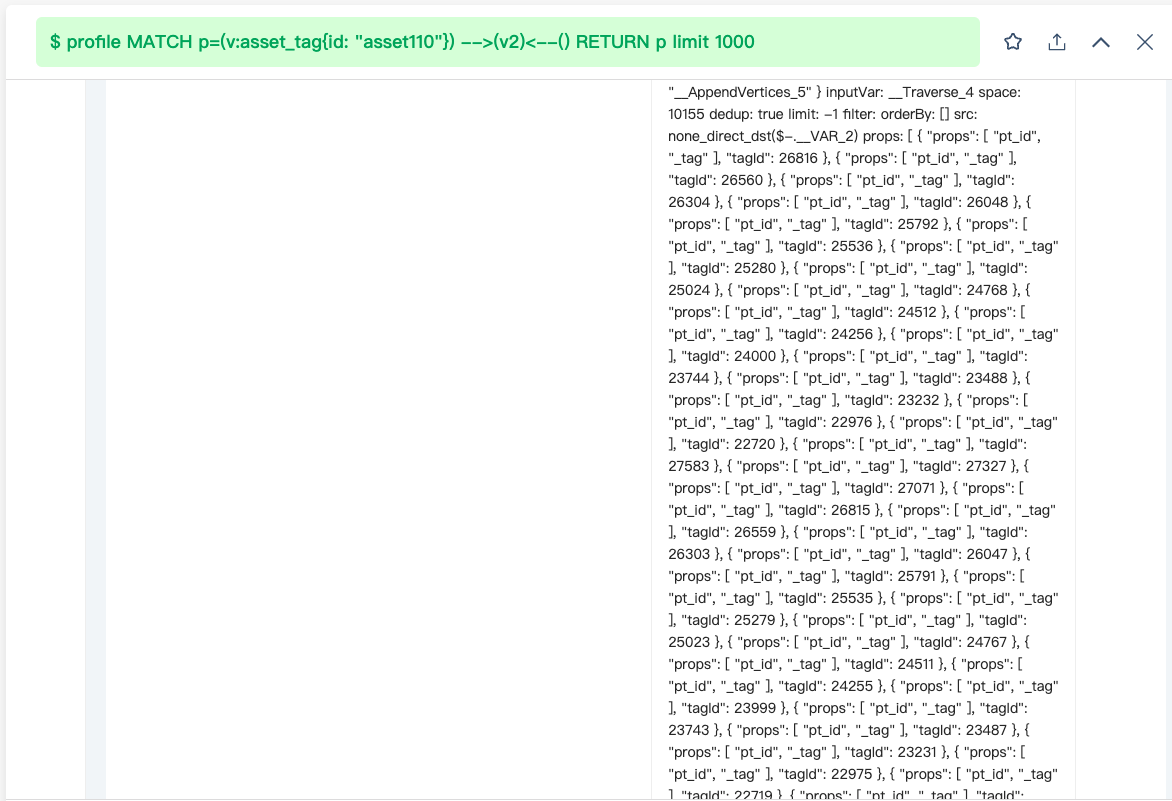
在完成上述测试后,随后将1万个点,每个点随机关联20个tag,并且为这 10000 tag建立索引。做完这些操作后,继续执行上述查询,发现已经查不出结果了,graphd 中也有一堆超时。

针对这个现象,翻了下社区里其他讨论,尝试做了一把手动 compact 后查询恢复正常了,请问这里的原理是什么呀?
我们的场景是:物联网时序场景,每个点是一个物理设备,设备之间会相互关联,设备上有很多指标(温度、负载等),我们想把这些指标作为 tag 关联到设别上,在实际环境中,这样的 tag 会有几十万甚至百万级,目前看这样的设计效果不理想,我们也在考虑将指标作为点处理,具体还要做进一步测试,针对这类场景,社区大佬们有一些设计建议吗?