1 概述
innodb 是 MySQL 主要的存储引擎, innodb 包含缓存页、事务系统和存储系统。本篇文章主要涉及最底层的物理存储进行分析,讲解了表空间的概念、数据字典、借助工具从用户表空间读取数据和观察索引的数据结构。
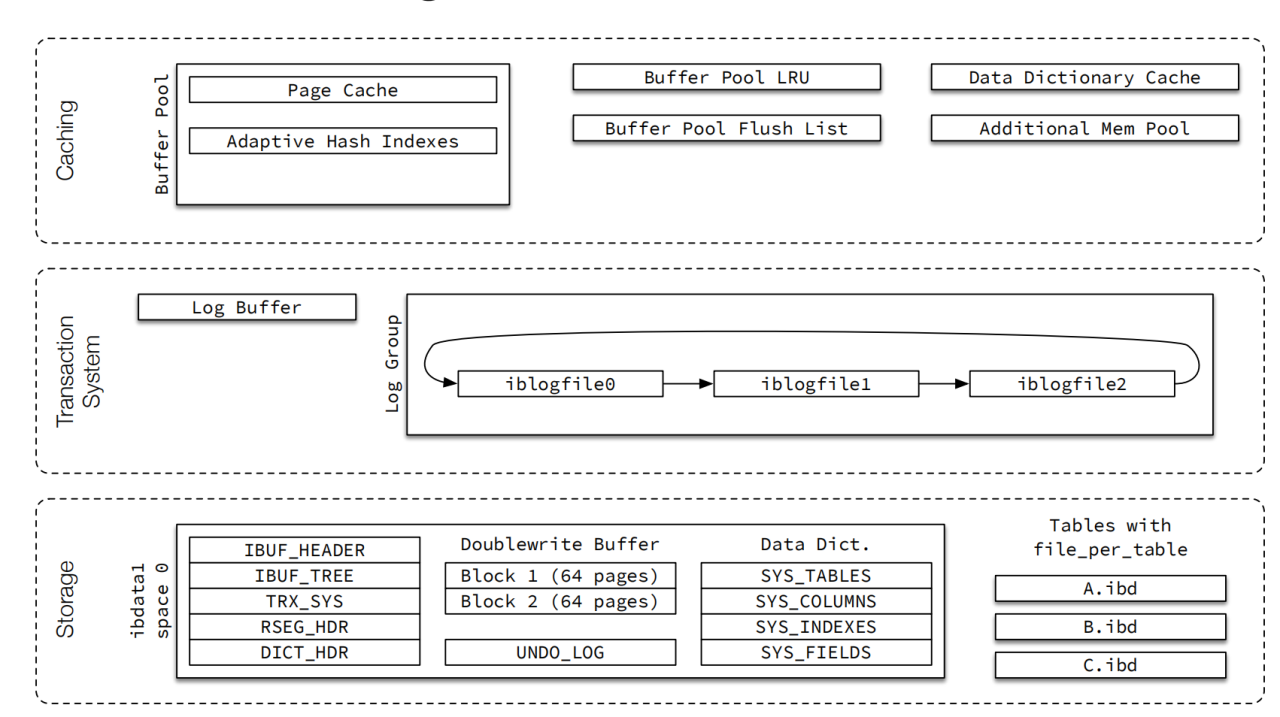
这个主要针对 MySQL5.7.40, 具体版本差异可能略微有不一致的地方。
在讲述前,我们先创建一个测试表和测试库。
CREATE DATABASE test;
use test;
CREATE TABLE IF NOT EXISTS `user`(
`id` INT UNSIGNED AUTO_INCREMENT,
`name` VARCHAR(100) NOT NULL,
`create_time` timestamp NOT NULL
DEFAULT CURRENT_TIMESTAMP,
PRIMARY KEY ( `id` )
)ENGINE=InnoDB DEFAULT CHARSET=utf8;
然后尝试插入若干条数据。
INSERT INTO test.user (name) VALUES ("1");
...
2 表空间和索引存储
本章节的目录主要是为了描述表空间的物理文件构成和并借助innodb_ruby工具直接从表空间中读取数据记录。
表空间简述
MySQL表空间是指在MySQL数据库中用于存储表和索引数据的逻辑结构单元。每个表都会被分配到一个或多个表空间中,表空间是由一个或多个数据文件组成的。在MySQL中,表空间的主要作用包括:存储表和索引数据、管理存储空间、优化性能。MySQL 包含如下表空间:
系统表空间:系统表空间是用于存储数据库管理系统的系统数据和元数据的特殊表空间。它包含系统目录、系统表和其他系统数据等。ibdata1 就是一个用来构建innodb系统表空间的文件。
每表文件表空间:每表文件表空间(也称为用户表空间)是用于存储用户创建的表和索引的表空间。每个表和索引都可以属于不同的表空间。以/.ibd文件的形式存在,每个表都独立占用一个表空间文件。
通用表空间:通用表空间是一种特殊类型的表空间,用于存储多个用户的表和索引。与每表文件表空间不同,通用表空间提供了更高的灵活性和可伸缩性,因为多个用户可以共享同一个表空间。它还简化了数据库维护和管理的工作。
撤消表空间:撤消表空间(也称为回滚表空间)用于存储事务撤消或回滚数据。撤消表空间通常是系统表空间的一部分。
临时表空间:临时表空间用于存储临时数据,如排序操作和临时表的创建。
通过控制台 sql 也可以从INFORMATION_SCHEMA 库中的 INNODB_SYS_TABLESPACES 表查看表空间的信息,当前版本系统表空间没有展示出来,系统表空间 ID 为 0.
mysql> select SPACE,NAME from INFORMATION_SCHEMA.INNODB_SYS_TABLESPACES;
+-------+---------------------------------+
| SPACE | NAME |
+-------+---------------------------------+
| 2 | mysql/plugin |
....
| 25 | test/user |
+-------+---------------------------------+
表空间物理结构
每个空间被分为多个页面,通常每个页面 16 KiB。如下图,每个 page 通常有不同的作用。

数据页
页(Page):页是InnoDB存储引擎中管理数据的最小单元。InnoDB将表的数据和索引按页的形式进行存储。每个页的大小通常为16KB。InnoDB的缓冲池(Buffer Pool)中存储着页数据,当需要读取或写入数据时,InnoDB会将对应的页加载到缓冲池中进行操作。
一个页中除去页头和页尾,实际可用的大小为 16338 byte. 不同类似的页实际内容都不太一样。

innodb分析工具innodb_ruby
innodb_ruby 是一个用于操作 InnoDB 存储引擎的 Ruby 语言库。它提供了在 Ruby 代码中访问和操作 InnoDB 存储引擎的功能。其中共包含 2 个命令行工具innodb_space 和innodb_log 分别可以分析 innodb 表空间和日志,这里主要用到innodb_space 工具对innodb 表空间和数据存储进行分析。
innodb_space 可以使用选项–system-space-file (-s) 指定系统空间,也可以使用选项–space-file (-f)指定普通的表空间进行分析。
系统表空间
ibdata 即系统空间,ibdata1是一个用来构建innodb系统表空间的文件,这个文件包含了innodb表的元数据、undo日志、修改buffer和双写buffer。 其中 ibdata 的大部分 page 页都是固定类型如下图。

从这张innodb 的结构图就可以看出来,系统表空间中大部分页的物理位置都是固定的。
使用innodb_space -s ibdata1 space-summary 可以看到 ibdata1 中每一页的信息,其中 type 属性代表该页的具体类型。
[root@sky data]# innodb_space -s ibdata1 space-summary
page type prev next lsn
0 FSP_HDR 0 0 12217552
1 IBUF_BITMAP 0 0 1199510
2 INODE 0 0 886508
3 SYS 0 0 11196
4 INDEX 0 0 11196
5 TRX_SYS 0 0 12218071
6 SYS 0 0 1196046
7 SYS 0 0 12219210
..。
其中从上图的命令行输出中可以看到以下一些页
-
FSP_HDR (Filespace Header): 这是文件空间头部页,用于存储关于整个文件系统的信息。
-
IBUF_BITMAP (Insert Buffer Bitmap): 这是插入缓冲区位图页,用于跟踪插入缓冲区中哪些位置有数据。
-
INODE: 这是索引节点页,用于存储文件和目录的元数据,例如权限、所有者和时间戳等。
-
SYS: 这是系统页,可能用于存储与文件系统或数据库相关的其他系统信息。
-
INDEX: 这是索引页,用于存储和管理文件系统中的索引数据,从而加快文件系统的访问速度。
-
TRX_SYS (Transaction System): 这是事务系统页,用于存储和管理数据库中的事务相关信息。
…
innodb_space 命令还支持直接查看系统表空间中记录的表空间信息, 通过system-spaces 参数可以打印出来。 user 表空间一共有 6 个 page,有 1 个索引 page.
[root@sky data]# innodb_space -s ibdata1 system-spaces
name pages indexes
...
test/user 6 1
InnoDB数据字典
我们目前关心的数据字典,也就是 SYS: Data Dirctionary 就是存储数据字典的相关信息,
数据字典信息是数据库表的元信息,包含了表的结构、列、索引的描述。
InnoDB由于历史原因,数据字典元数据与表元数据文件(文件)中存储的信息存在一定程度的重叠 .frm 文件,在 MySQL 8 中已经取消.frm 文件
可以通过以下命令从 ibdata1 文件中读取每个表的元数据,包含表信息、列信息、索引信息和字段信息
innodb_space -s ibdata1 data-dictionary-tables
innodb_space -s ibdata1 data-dictionary-columns
innodb_space -s ibdata1 data-dictionary-indexes
查看当前 test/user 表的信息
[root@sky data]# innodb_space -s ibdata1 data-dictionary-tables
name id n_cols type mix_id mix_len cluster_name space
test/user 44 2147483651 33 0 80 25
查看 test/user列的信息
[root@sky data]# innodb_space -s ibdata1 data-dictionary-columns
table_id pos name mtype prtype len prec
44 0 id 6 1795 4 0
44 1 name 12 2167055 300 0
44 2 create_time 3 525575 4 0
查看 test/user索引信息,从这里可以看到page_no =3 , 代表索引页的根页位于test/user表空间的第三页
[root@sky data]# innodb_space -s ibdata1 data-dictionary-indexes
table_id id name n_fields type space page_no
44 41 PRIMARY 1 3 25 3
用户表空间

用户表空间通常一个表属于一个空间,位于<数据库名称>/表名.ibd 文件。
通过space-summary 命令查看用户表空间的每一页信息,需要-f 指定相应的表空间 ibd 文件。
和系统表空间中的结构比较类型,其中根索引页一般都在第三页,如果超过一个索引页,会往下增加索引页,上面记录的 table page_no 一致
[root@sky test]# innodb_space -f test/user.ibd space-summary
page type prev next lsn
0 FSP_HDR 0 0 12221415
1 IBUF_BITMAP 0 0 12218171
2 INODE 0 0 12221415
3 INDEX 0 0 12221415
4 ALLOCATED 0 0 0
5 ALLOCATED 0 0 0
索引页
通过page-illustrate 参数可以打印出当前页的详细使用情况和分布情况,如下就是一个索引页的详情。
[root@sky data]# innodb_space -f test/user.ibd -p 3 page-illustrate
Page 3 (INDEX)
Offset ╭────────────────────────────────────────────────────────────────╮
0 │█████████████████████████████████████▋██████████████████████████│
64 │█████████▋███████████████████▋████████████▋████████████▋████▋▋▞▞│
128 │▞▞▞▞▞████▋▋▞▞▞▞▞▞▞████▋▋▞▞▞▞▞▞▞████▋▋▞▞▞▞▞▞▞████▋▋▞▞▞▞▞▞▞▞▞▞▞▞▞▞│
192 │▞▞▞▞▞▞▞▞▞▞▞▞▞▞▞▞▞▞▞▞▞▞▞▞▞▞▞▞▞▞▞▞▞▞▞▞▞▞▞▞▞▞▞▞▞▞▞▞▞▞▞▞▞▞▞▞▞▞▞▞▞▞▞▞│
....
16256 │▞▞▞▞▞▞▞▞▞▞▞▞▞▞▞▞▞▞▞▞▞▞▞▞▞▞▞▞▞▞▞▞▞▞▞▞▞▞▞▞▞▞▞▞▞▞▞▞▞▞▞▞▞▞▞▞▞▞▞▞▞▞▞▞│
16320 │▞▞▞▞▞▞▞▞▞▞▞▞▞▞▞▞▞▞▞▞▞▞▞▞▞▞▞▞▞▞▞▞▞▞▞▞▞▞▞▞▞▞▞▞▞▞▞▞▞▞▞▞▞▞█▋█▋█████▋│
Legend (█ = 1 byte):
Region Type Bytes Ratio
█ FIL Header 38 0.23%
█ Index Header 36 0.22%
█ File Segment Header 20 0.12%
█ Infimum 13 0.08%
█ Supremum 13 0.08%
█ Record Header 25 0.15%
█ Record Data 5 0.03%
█ Page Directory 4 0.02%
█ FIL Trailer 8 0.05%
░ Garbage 0 0.00%
▞ Unknown (no data dictionary) 16222 99.01%
其实索引页的结构如下,Record Data 就是实际存放索引数据的地方。
-
FIL Header:文件头部,存储了索引页的一些基本信息,比如页号和页类型等。
-
Index Header:索引头部,存储了索引的元数据,包括索引的结构和属性等信息。它提供了索引的定义和配置,用于索引的创建和维护。
-
File Segment Header:文件段头部,用于管理数据库文件的段(segment)的头部信息。一个数据库文件可以被分为多个段,文件段头部记录了每个段的属性和状态等信息。
-
Infimum:最小值,是在索引页中的特殊记录,代表索引键值的最小值。它用于保证索引的完整性和范围查询的正确性。
-
Supremum:最大值,是在索引页中的特殊记录,代表索引键值的最大值。和Infimum类似,它也用于保证索引的完整性和范围查询的正确性。
-
Record Header:记录头部,存储了每个记录的元数据,包括记录的长度、类型等信息。它用于索引页中记录的解析和访问。
-
Record Data:记录数据,存储了每个记录的具体数据。根据不同的索引类型,记录数据可以是实际的索引键值,或者是指向实际数据行的指针。
-
Page Directory:页面目录,存储了索引页中每个记录的位置和偏移量等信息。它提供了索引页内记录的快速查找和访问。
-
FIL Trailer:文件尾部,存储了索引页的结尾信息,如校验和等。它用于保证索引页的完整性和正确性。
-
Garbage:垃圾数据,表示在索引页中没有被使用或不再有效的数据区域。这些数据区域被标记为垃圾,可能由于索引的修改或数据的删除而产生。
-
Unknown (no data dictionary):未知类型(未分配空间),表示在索引页中没有被分配给具体数据类型或者未被使用的空间。这些空间可能是留作扩展或未使用的保留空间
可以直接通过指定user.ibd 执行 page-records 获取记录,但是由于没有数据字典,只能获取每个数据记录在页中的偏移量,无法仅仅靠用户表空间解析数据本身。
[root@sky examples]# innodb_space -f test/user.ibd -p 3 page-records
Record 126: () → ()
Record 154: () → ()
Record 182: () → ()
Record 210: () → ()
Record 238: () → ()
Record 266: () → ()
Record 294: () → ()
Record 322: () → ()
Record 350: () → ()
Record 378: () → ()
Record 406: () → ()
利用数据字典,加上用户表空间就能读取到数据库数据了。这里尝试使用page-records 命令读取用户表空间中page_no=3 的数据记录,能够顺利地读取表空间的真实数据。
这也说明了本地磁盘并没有做静态加密,即使不需要任何认证只要能够访问数据字典就能读取数据。
[root@sky examples]# innodb_space -s ./ibdata1 -T test/user -p 3 page-records
Record 126: (id=1) → (name="1", create_time="2023-07-23 14:07:16")
Record 154: (id=2) → (name="1", create_time="2023-07-23 14:07:17")
Record 182: (id=3) → (name="1", create_time="2023-07-23 14:07:17")
Record 210: (id=4) → (name="1", create_time="2023-07-23 14:07:18")
Record 238: (id=5) → (name="1", create_time="2023-07-23 14:07:19")
Record 266: (id=6) → (name="1", create_time="2023-07-23 14:07:19")
Record 294: (id=7) → (name="1", create_time="2023-07-23 14:07:20")
Record 322: (id=8) → (name="1", create_time="2023-07-23 14:07:21")
Record 350: (id=9) → (name="1", create_time="2023-07-23 14:07:21")
Record 378: (id=10) → (name="1", create_time="2023-07-23 14:07:22")
Record 406: (id=11) → (name="1", create_time="2023-07-23 15:07:51")
3 索引页组织方式
本章节主要讲表空间数据页中和跨数据页的索引排列方式。
页内索引-页目录
一个页内部的索引,通常是一个链表结构,一个元素指向下一个元素,单调递增。其中单个页中包含
● infimum: 代表索引最小的值,即链表头
● supremum: 代表索引最大的值,即链表尾
如果一个 page 中一共有 n 的索引,那么为了找到一个索引,只是通过链表的结构从infimum 到supremum,最大的时间复杂度就需要 O(n),为了提高单个 page 中的索引的查询数据。引入了一个叫 page directory 的数据结构,有一块专门的物理区域存放,也可以叫做页目录。
这个算法的原理是这样的:
首先对索引进行分组,每一组叫数据槽 slots,其中 owned 为组中的索引数量,记录在该组的最后一个索引中,并且page directory 中记录的地址也是最后一个索引的地址。
如下图中 infimum 为第一组,索引数 1;中间每组索引数为 4;最后一组 supremum 索引数为 5;一共有 7 个 slot.
然后就可以通过对 page directory 二分法定位索引,时间复杂度为O(logN)
-
先定位到中间的 slot 末尾索引地址,对比索引值大小
-
如果需要查询的索引值大于它,则从当前 slot 和最后一个 slots 取中间 slot 的索引进行对比
-
如果需要查询的索引值小于它,则从当前 slot 和第一个 slots 取中间 slot 的索引进行对比
-
直到上下界限的 slot 相等,然后从末尾索引开始往前定位,直到找到相等的索引
可以通过page-directory-summary 查看当前索引页的 page-directory 信息,可以看出infimum 索引数固定为 1,中间 slot 索引数为 4,最后的supremum 为 4~7 之间,这里为 7.
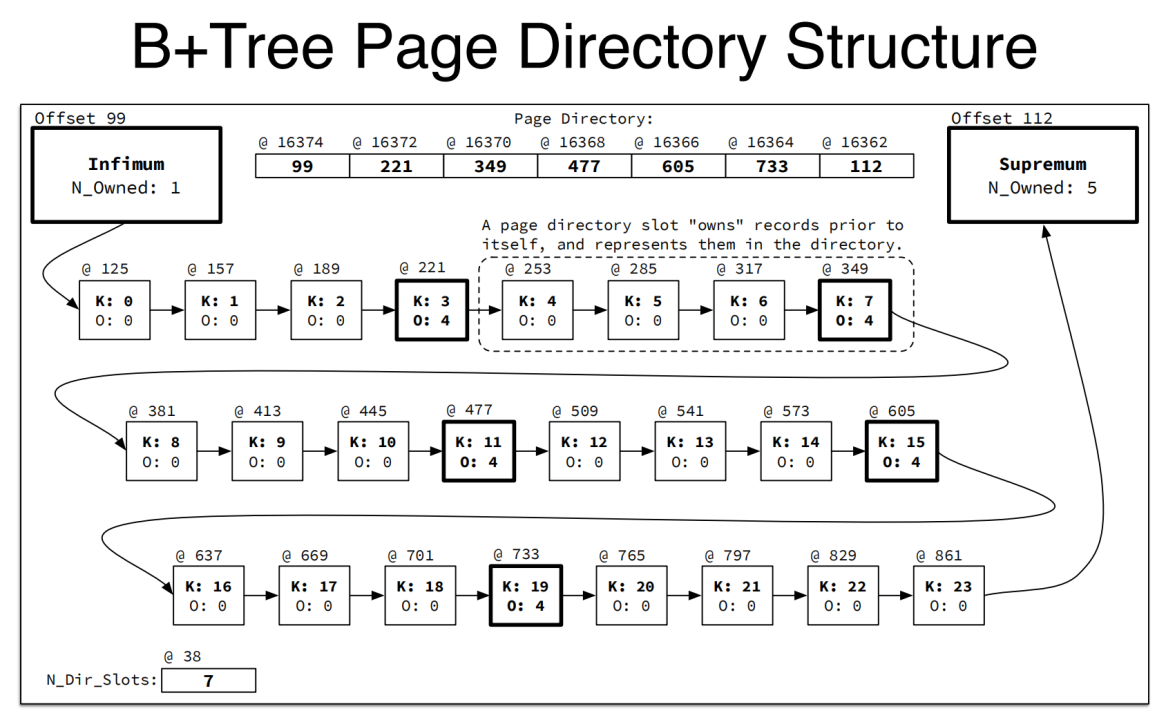
0 99 infimum 1
1 210 conventional 4 ()
2 112 supremum 7
跨页索引-B+树
页外就是我们常见的 B+树模型了,一个页只有 16k,存储的数据有限,当我们插入大量的数据时,会发生什么事情呢?
尝试不断往测试表中插入数据,当前已经插入 1897 条记录。
mysql> select count(*) from test.user;
+----------+
| count(*) |
+----------+
| 1897 |
+----------+
1 row in set (0.00 sec)
此时观察索引页数量,已经由原来的 1 个变成了6 个,这代表树开始进行分裂。
[root@sky data]# innodb_space -f test/user.ibd space-summary
page type prev next lsn
0 FSP_HDR 0 0 12511818
1 IBUF_BITMAP 0 0 12218171
2 INODE 0 0 12511818
3 INDEX 0 0 12511818
4 INDEX 0 5 12400985
5 INDEX 4 6 12455415
6 INDEX 5 7 12511818
7 INDEX 6 8 12511818
8 INDEX 7 0 12515126
9 ALLOCATED 0 0 0
通过index-digraphdigraph 命令打印出当前的索引结构。从以下打印出的内容中,可以当前 b+树已经分裂成 8 个树。
其中根节点是 page_3,其他 5 个节点是叶子树,这是一个二级的 B+树。
[root@sky data]# innodb_space -s ./ibdata1 -T test/user -I PRIMARY index-digraph
digraph btree {
rankdir = LR;
ranksep = 2.0;
page_3 [ shape = 'record'; label = '<page>Page 3|(5 records)|<dir_4>(#<struct Innodb::Page::Index::FieldDescriptor name="id", type="INT UNSIGNED", value=1, extern=nil>)|...];
page_3:dir_4 → page_4:page:nw;
page_4 [ shape = 'record'; label = '<page>Page 4|(267 records)'; ];
page_3:dir_5 → page_5:page:nw;
page_5 [ shape = 'record'; label = '<page>Page 5|(534 records)'; ];
page_3:dir_6 → page_6:page:nw;
page_6 [ shape = 'record'; label = '<page>Page 6|(534 records)'; ];
page_3:dir_7 → page_7:page:nw;
page_7 [ shape = 'record'; label = '<page>Page 7|(534 records)'; ];
page_3:dir_8 → page_8:page:nw;
page_8 [ shape = 'record'; label = '<page>Page 8|(28 records)'; ];
}
通过page-records 命令查看每一页的数据(由于记录太多, 我这边只记录关键的一些输出,
root@sky data]# innodb_space -s ./ibdata1 -T test/user -p 3 page-records
Record 125: (id=1) → #4
Record 138: (id=268) → #5
Record 151: (id=802) → #6
Record 164: (id=1336) → #7
Record 177: (id=1870) → #8
[root@sky data]# innodb_space -s ./ibdata1 -T test/user -p 4 page-records
Record 126: (id=1) → (name="1", create_time="2023-07-23 14:07:16")
...
Record 7574: (id=267) → (name="1", create_time="2023-07-26 12:57:35")
[root@sky data]# innodb_space -s ./ibdata1 -T test/user -p 4 page-records
Record 126: (id=268) → (name="1", create_time="2023-07-26 12:57:35")
...
Record 15050: (id=801) → (name="1", create_time="2023-07-26 12:57:58")
...
通过上面的命令可以判断出当前的 B+树模型为下图所示。
那么当我们需要通过索引寻找数据时
-
首先从根索引开始查找,当然页内部会通过 page directory 机制进行查找
-
当发现索引位于某 2 个索引区间,获取起始区间的索引中记录的下一个子树的地址,并且开始查找下一个子树
-
子树内部依然通过page directory 机制进行查找,这里由于只有二级,所以就能直接找到索引,如果有更多级,则继续迭代往子树查找。
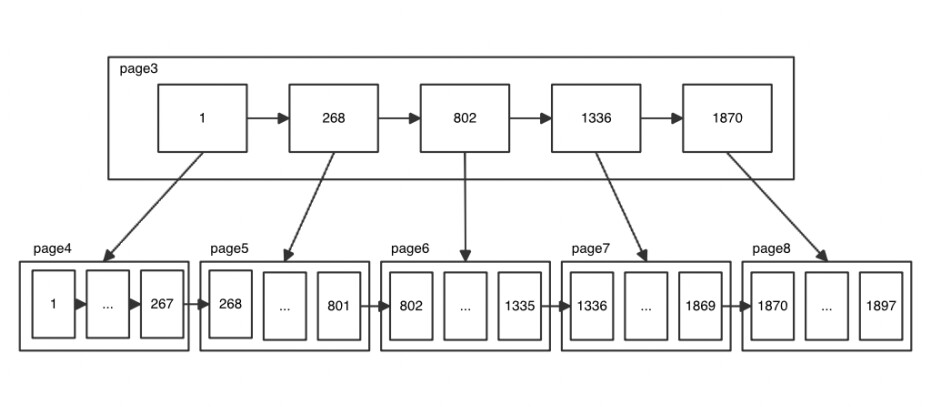
MYSQL 常规的 B+树模型分布可以参考下图。
● infimum 和 supremun 记录每页中的最小记录和最大记录
● 非叶子节点中的索引记录的是下一个页的地址,叶子节点的行记录直接跟在索引后面(聚簇索引)
● 定位索引需要从一级一级往下进行定位
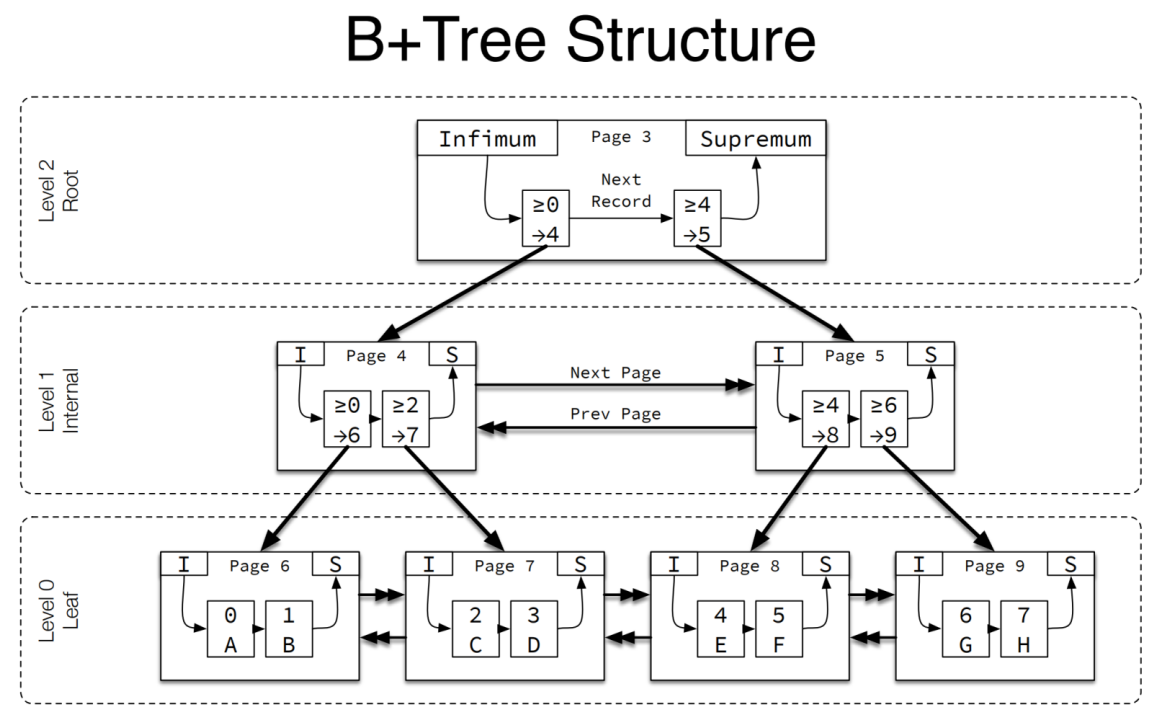
4 总结
InnoDB是MySQL的一种存储引擎,它采用了B+树作为存储和索引的数据结构。了解InnoDB的物理结构对于系统管理员和业务开发人员都非常重要,可以提升MySQL的运维稳定性和优化业务的执行效率。
对于系统管理员来说,了解InnoDB的物理结构可以帮助他们更好地管理数据库的存储空间和性能。
对于业务开发人员来说,理解InnoDB的物理结构可以帮助他们优化SQL查询和提高业务的执行效率。
总而言之,了解InnoDB的物理结构对于系统管理员和业务开发人员都是非常有益的。系统管理员可以通过维护和管理数据库的物理结构提升系统的稳定性,而业务开发人员则可以通过优化SQL查询和索引结构提高业务的执行效率。这样可以使得MySQL的运维和业务开发更加高效和可靠。
参考资料
innodb_diagrams: GitHub - jeremycole/innodb_diagrams: Diagrams for InnoDB data structures and behaviors
innodb_ruby: GitHub - jeremycole/innodb_ruby: A parser for InnoDB file formats, in Ruby
The basics of InnoDB space file layout : The basics of InnoDB space file layout – Jeremy Cole
innodb-tablespace: https://dev.mysql.com/doc/refman/5.7/en/innodb-tablespace.html