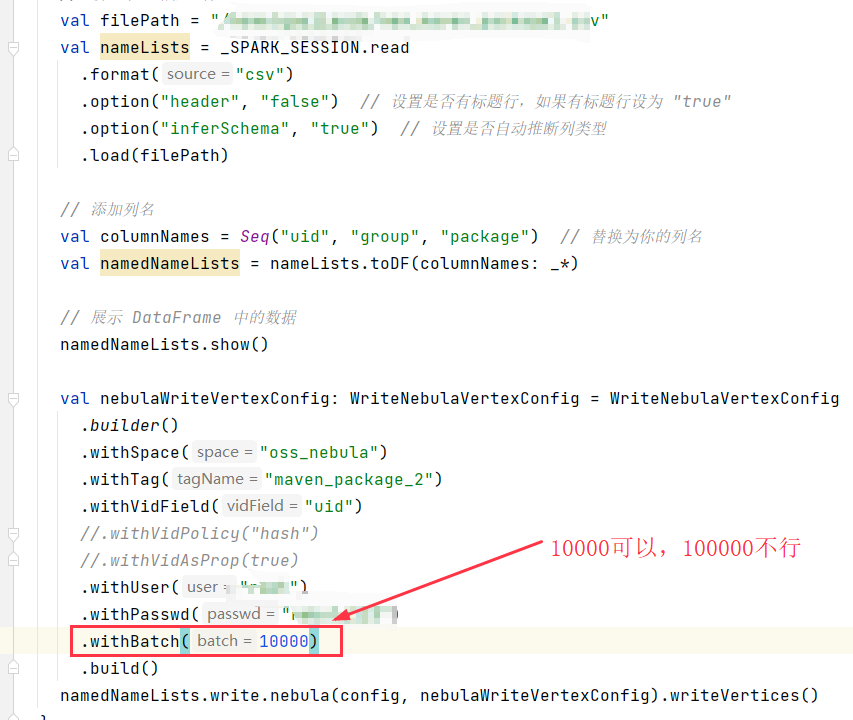
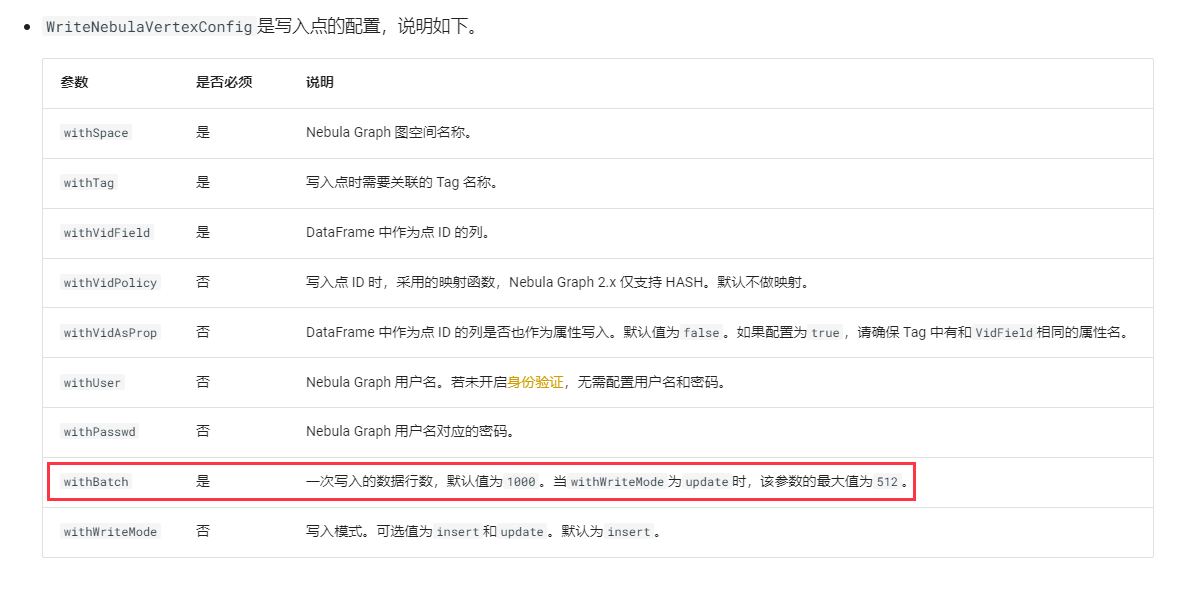
nebula 版本:2.6.2 部署方式:分布式 安装方式:TAR 是否上生产环境:N 硬件信息 磁盘:HHD 8T * 12 内存 128G 问题的具体描述: 使用官网提供的Nebula Spark Connector读取hdfs上数据并加载到nebula时,当batch为100000时无法正常加载到nebula中,调整为10000后可正常加载,想请教下这个参数值有限制吗?服务端和spark均无异常日志打印。
此话题已在最后回复的 30 天后被自动关闭。不再允许新回复。