前文
紧接上文NebulaGraph助力赋能大模型,独特的图模型有助于大模型建设,本文探索如何落地进行图模型的建设,怎么做?从哪一步下手?通过王者荣耀图谱构建,从文中你可以得到以下收获。
- NebulaGraph的python编程环境搭建
- NebulaGraph的入门级api使用
- NebulaGraph的编程示例
- 图模型的优势好处
- 图模型的构建考虑因素
- 多种调校图模型的分析参数的方式
- NebulaGraph对图世界的理解与奉献
模型区别
《DAMA数据管理知识体系指南》一书将数据建模方法分成6种,分别是关系建模 、维度建模、面向对象建模、基于事实建模、基于时间建模以及NOSQL建模,其中NOSQL再往下划分有文档建模、图建模、列建模、键值建模。那么关系建模和维度建模较与图建模有什么不同, 图模型有什么优势。
图模型更容易发现数据之间千丝万缕的关系。举一个例子,中国所有的人口信息写在数据库,要找出你和接触北京某位人物要经过多少层链路。 关系模型和维度模型要耗费极大力气,而且是不理想的效果,而图模型则是可以轻轻松松的完成。
举个例子,青春偶像剧里面的爸爸失散多年的女儿与自己的亲生儿子产生感情的应用场景,男的婚外情,挂牌小三生了一个孩子,孩子不知道亲父的存在,多年以后,居然与正牌的儿子谈起恋爱。图模型可以防止发生这样的意外
按照关系建模的思路
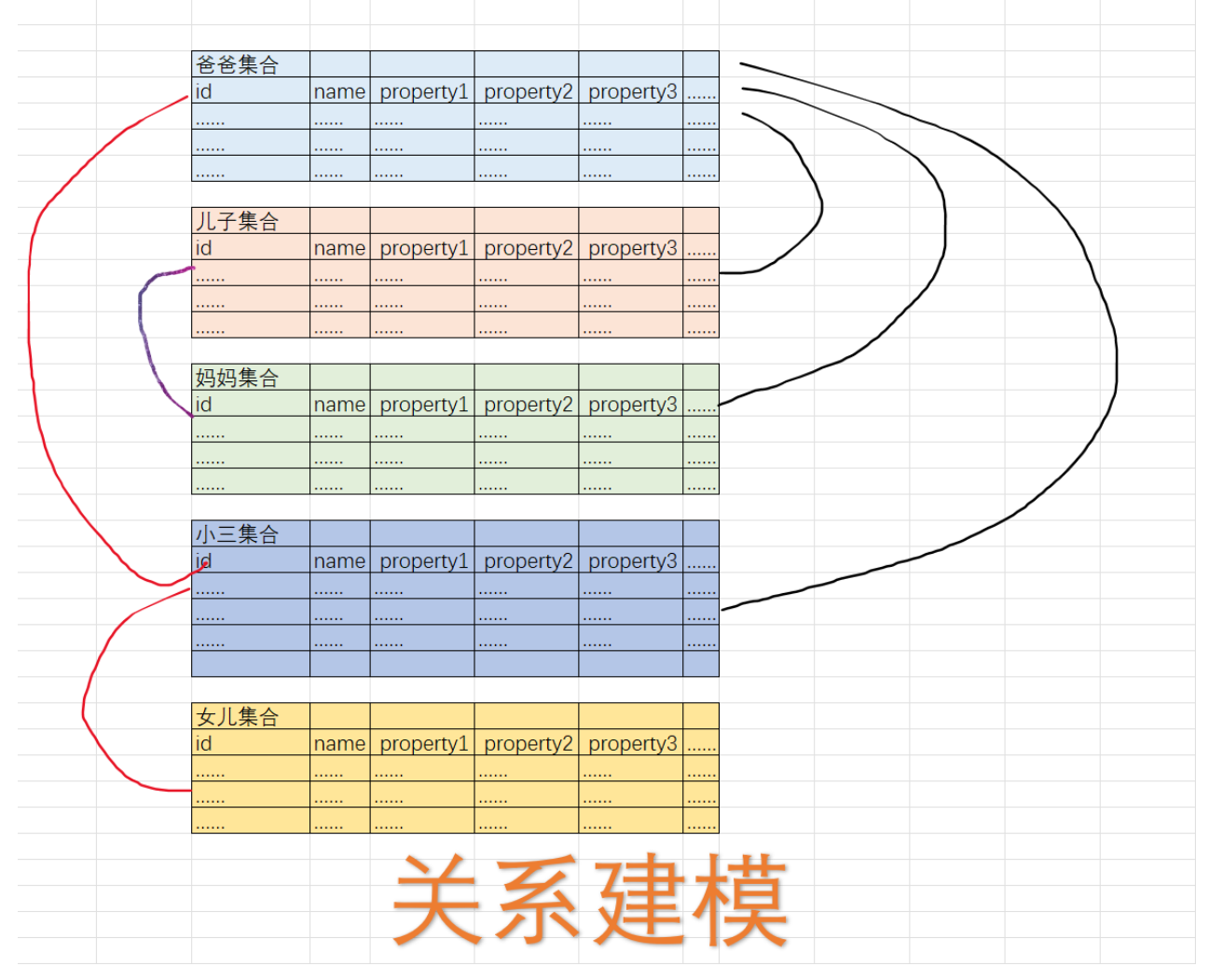
关系建模弊病是两个集合互相隔离,只能通过有限的外键互相相认,行数据之间不知道彼此的关系,而且距离遥远,使用算法模型也麻烦。
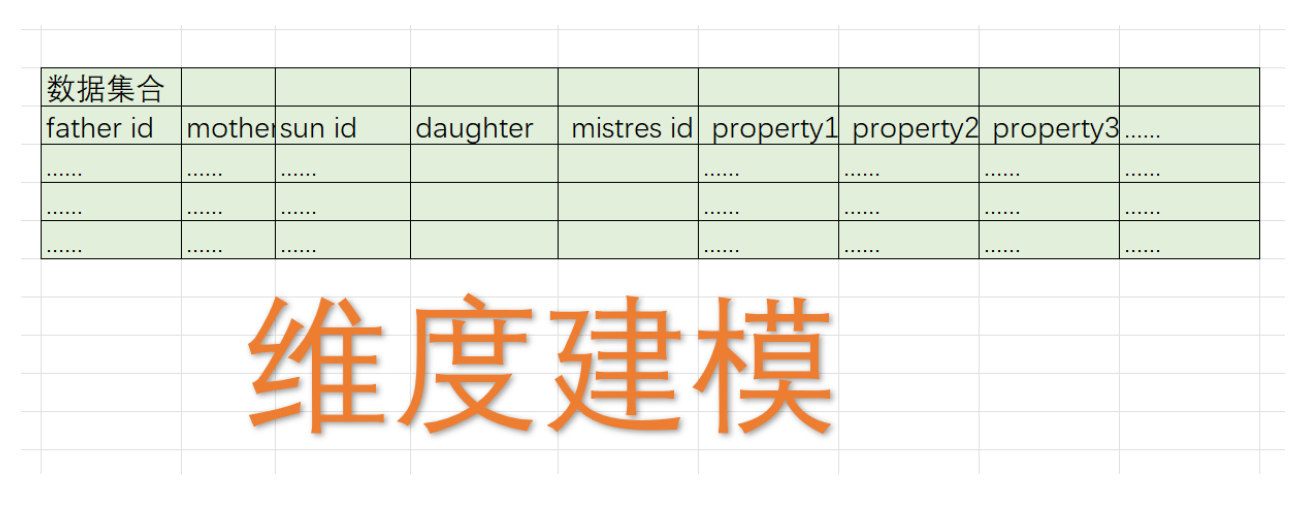
按照维度建模的思路
经过数据整合后,维度建模把大量相关的数据都集中在一起,虽然距离很近,但是彼此之间不知道两者的关系。运行算法型耗费大量的精力,却得出一个错误的结果。
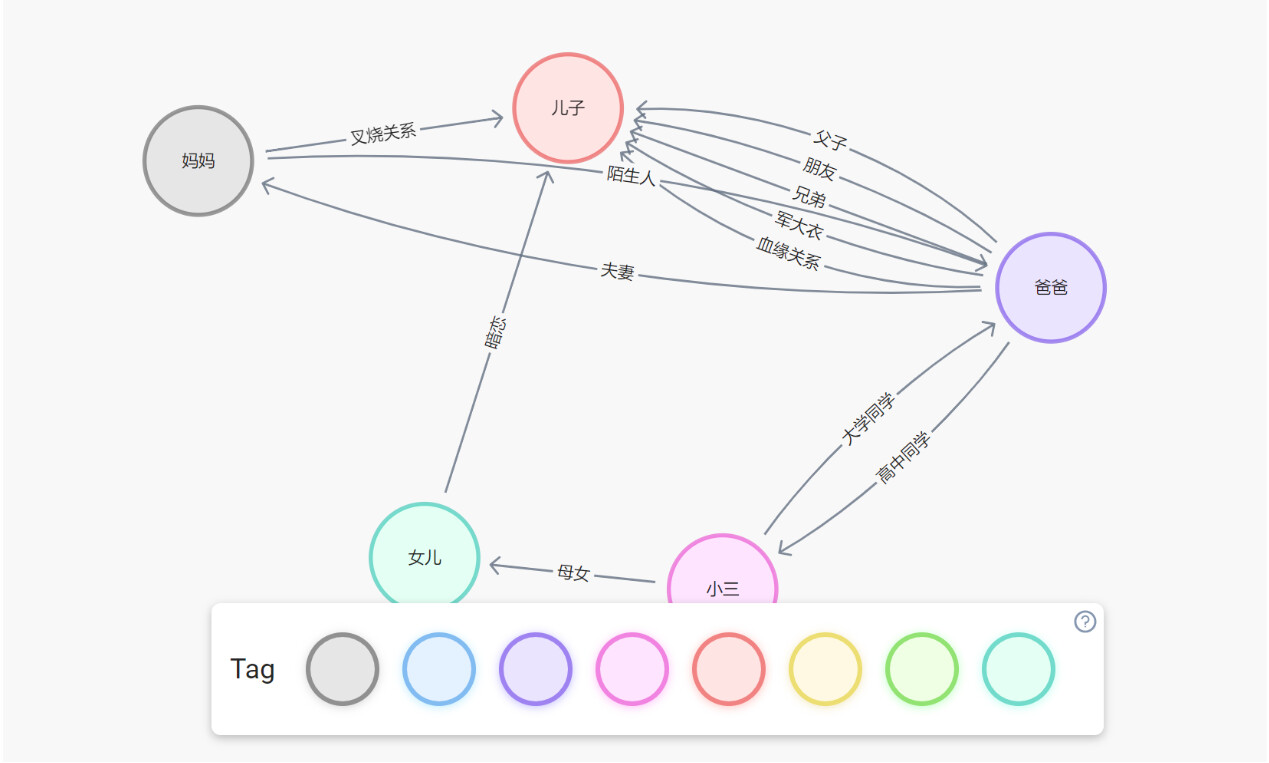
按照图建模的思路
图中可见图模型的特别之处,就是点与点之间的关系,图建模称为边,通过边确定两个点之间的关系,通过边实现数据之间高维度的关系。
图模型的秘决是两点之间单边的关系和数据值,平时对图模型的维护主要是对边的维护,调整到真实值,自然也能反映客观状况的真实值。
实践开发
硬件环境
| ip角色 | 作用 | |
|---|---|---|
| 192.168.10.X | Nebulagraph单点 | 服务端 |
| 192.168.10.X | windows11+pycharm+python3.9 | 客户端 |
客户端安装python3.9,基于pip安装, pip3.9.exe install nebula3-python以及panda包
确定开发工具pycharm已经安装相关的package。
业务场景
图模型的标准建模步骤分为三个阶段
-
确定顶点以及顶点的属性
-
确定边和边的属性
-
反复调校关系属性值【最为关键,需要持续不断的调整维护】
业务需求分析,根据当前的热门游戏创建一个王者荣耀相关的图谱,图谱中反映英雄之间的关系以及阵营关系。
哪些属于顶点?哪些属于边?应该设成什么样的值?
图模型思路第一步确定顶点以及顶点的属性,其中一个顶点与英雄 有关的,属性有姓名、类型、年龄等等。另外一个顶点是英雄所附属的阵盟,阵营必然有一个名字,英雄使用的装备以及铭文都可以算是一个顶点。
因此王者图谱的顶点至少有 英雄、阵营、铭文、装备、级数等等,为了简洁代码,只创建了英雄和阵营。
CREATE TAG IF NOT EXISTS hero(name string, age int,type string) //确定英雄
CREATE TAG IF NOT EXISTS team(name string) //确定阵营
CREATE TAG IF NOT EXISTS 铭文(property1、property2、property3、property4)
CREATE TAG IF NOT EXISTS 装备(property1、property2、property3、property4)
CREATE TAG IF NOT EXISTS 级数(property1、property2、property3、property4)
顶点支撑图模型的框架,边发展图模型的关系能力。 第二步是先确认边的关系及基本属性,随着业务了解再确认更多的属性。
顶点之间,英雄之间是否有相生相克的关系【字符串】? 英雄之间是否的匹配程度【数值】?英雄与阵营之间的关系,例如工作的时长?
考虑这些因素,设计了3个边定义。边follow是英雄之间的匹配程度, 边serve是英雄与阵营之间的关系,边关系是英雄之间相生相克,派生了下面边的边创建。
CREATE EDGE IF NOT EXISTS follow(degree int)
CREATE EDGE IF NOT EXISTS serve(start_year int, end_year int)
CREATE EDGE IF NOT EXISTS 关系(relate string)
按照这样的建模思路,如果算上铭文和装备,英雄和铭文的关系,英雄和装备的关系,装备与装备之间的叠加提成,铭文和装备之间的总成能力,可以延升更多边的关系。
第三步是在边上确认两边点数据的关系,这里十分麻烦,必须要对业务非常熟悉,通过 下面的简洁可观的内容进行编排,注意看 edge_follow.csv、edge_serve.csv、edge_relate.csv, 它们里面的数据是根据业务反复去调整 的。
举例 hero100 hero101 95,表明hero100和hero101之间程度数值 是95,INSERT EDGE IF NOT EXISTS follow(degree) VALUES "{}"->"{}":({}),它们的方向是根据->进行入库的,这表示hero100指向hero101的数值 是95。
而hero100,hero101,克制,使用INSERT EDGE IF NOT EXISTS 关系(relate) VALUES "{}"->"{}":("{}")的方式入库,注意看->,表示hero100对hero101进行克制。
数据
顶点-英雄基本表数据vertex_hero.csv
hero101,31,成吉思汗,射手
hero102,34,马克,射手
hero103,38,王昭君,法师
hero104,30,周瑜,法师
hero105,23,张飞,坦克
hero106,32,廉玻,坦克
hero107,32,曹操,战士
hero108,34,司空震,战士
hero109,29,阿珂,刺客
hero125,41,上官小腕,法刺
顶点-阵营基本表vertex_team.csv
team204 秦国
team218 魏国
team229 楚国
team202 汉国
team208 唐国
team216 吴国
team217 超自然
team223 明朝
team224 元国
team205 秦国
边-英雄之间关系值 edge_follow.csv,将来英雄之间关系值根据业务的变动变化而变化
hero100 hero101 95
hero100 hero125 95
hero101 hero100 95
hero101 hero102 90
hero101 hero125 95
hero102 hero100 75
hero102 hero101 75
hero103 hero102 70
hero104 hero100 55
hero104 hero101 50
边-英雄服役时间edge_serve.csv
hero100,team204,1997,2016
hero101,team204,1999,2018
hero101,team215,2018,2019
hero102,team203,2006,2015
hero102,team204,2015,2019
hero103,team204,2017,2019
hero103,team208,2013,2017
hero103,team212,2006,2013
hero103,team218,2013,2013
hero104,team200,2007,2009
边-英雄之间牵制edge_relate.csv,将来英雄之间关系标签根据业务的变动变化而变化
hero100,hero101,克制
hero100,hero125,辅助
hero101,hero100,克制
hero101,hero102,加强
hero101,hero125,加强
hero102,hero100,辗压
hero102,hero101,克制
hero103,hero102,牵制
hero104,hero100,辅助
hero104,hero101,加强
代码建表
建立王者荣耀的2个顶点和3个边
from nebula3.gclient.net import ConnectionPool
from nebula3.Config import Config
import pandas as pd
config = Config() # 定义一个配置
config.max_connection_pool_size = 1 # 设置最大连接数
connection_pool = ConnectionPool() # 初始化连接池
source_root="C:/Users/HUAWEI/Desktop/NebulaGraph/csv/"
# 如果给定的服务器是ok的,返回true,否则返回false
ok = connection_pool.init([('xx.xx.xx.xx', 9669)], config)
# Session Pool,session将自动释放
with connection_pool.session_context('root', 'root') as session:
# 创建basketballplayer_python空间
nGQL='CREATE SPACE IF NOT EXISTS `HonorofKings` (vid_type = FIXED_STRING(64));' \
'USE HonorofKings;' \
'CREATE TAG IF NOT EXISTS hero(name string, age int,type string);' \
'CREATE TAG IF NOT EXISTS team(name string);' \
'CREATE EDGE IF NOT EXISTS follow(degree int);' \
'CREATE EDGE IF NOT EXISTS 关系(relate string);' \
'CREATE EDGE IF NOT EXISTS serve(start_year int, end_year int);'
session.execute(nGQL)
result = session.execute('SHOW SPACES')
print(result)
# 关闭连接池
connection_pool.close()
代码装载数据
from nebula3.gclient.net import ConnectionPool
from nebula3.Config import Config
import pandas as pd
config = Config() # 定义一个配置
config.max_connection_pool_size = 1 # 设置最大连接数
connection_pool = ConnectionPool() # 初始化连接池
source_root="C:/Users/HUAWEI/Desktop/NebulaGraph/csv/"
# 如果给定的服务器是ok的,返回true,否则返回false
ok = connection_pool.init([('xx.xx.xx.xx', 9669)], config)
vertex_player_df = pd.read_csv(source_root+"vertex_hero.csv", header=None,sep=',',
names=['player_id', 'age', 'name', 'type'])
vertex_team_df = pd.read_csv(source_root+"vertex_team.csv", header=None,sep='\t',
names=['team_id', 'name'])
edge_follow_df = pd.read_csv(source_root+"edge_follow.csv", header=None,sep='\t',
names=['player_id1', 'player_id2', 'degree'])
edge_relate_df = pd.read_csv(source_root+"edge_relate.csv", header=None,sep=',',
names=['player_id1', 'player_id2', 'relate'])
edge_serve_df = pd.read_csv(source_root+"edge_serve.csv", header=None,sep=',',
names=['player_id', 'team_id', 'start_year', 'end_year'])
# Session Pool,session将自动释放
with connection_pool.session_context('root', 'ee') as session:
session.execute("use HonorofKings")
# 从CSV文件中读取数据,插入到player标签中
for index, row in vertex_player_df.iterrows():
print('INSERT VERTEX IF NOT EXISTS hero(name, age,type) VALUES "{}":("{}", {},"{}");'.format(row['player_id'],
row['name'],
row['age'],
row['type']
))
session.execute(
'INSERT VERTEX IF NOT EXISTS hero(name, age,type) VALUES "{}":("{}", {},"{}");'.format(row['player_id'],
row['name'],
row['age'],
row['type']
))
# 从CSV文件中读取数据,插入到team标签中
for index, row in vertex_team_df.iterrows():
print('INSERT VERTEX IF NOT EXISTS team(name) VALUES "{}":("{}");'.format(row['team_id'], row['name']))
session.execute('INSERT VERTEX IF NOT EXISTS team(name) VALUES "{}":("{}")'.format(row['team_id'], row['name']))
# 从CSV文件中读取数据,插入到follow边中
for index, row in edge_follow_df.iterrows():
print('INSERT EDGE IF NOT EXISTS follow(degree) VALUES "{}"->"{}":({});'.format(row['player_id1'],
row['player_id2'],
row['degree']))
session.execute('INSERT EDGE IF NOT EXISTS follow(degree) VALUES "{}"->"{}":({})'.format(row['player_id1'],
row['player_id2'],
row['degree']))
# 从CSV文件中读取数据,插入到follow边中
for index, row in edge_relate_df.iterrows():
print('INSERT EDGE IF NOT EXISTS 关系(relate) VALUES "{}"->"{}":("{}");'.format(row['player_id1'],
row['player_id2'],
row['relate']))
session.execute('INSERT EDGE IF NOT EXISTS 关系(relate) VALUES "{}"->"{}":("{}")'.format(row['player_id1'],
row['player_id2'],
row['relate']))
# 从CSV文件中读取数据,插入到serve边中
for index, row in edge_serve_df.iterrows():
print('INSERT EDGE IF NOT EXISTS serve(start_year, end_year) VALUES "{}"->"{}":({}, {});'.format(row['player_id'],
row['team_id'],
(row['start_year']),
row['end_year']))
session.execute(
'INSERT EDGE IF NOT EXISTS serve(start_year, end_year) VALUES "{}"->"{}":({}, {})'.format(row['player_id'],
row['team_id'],
(row['start_year']),
row['end_year']))
# 关闭连接池
connection_pool.close()
模型探索
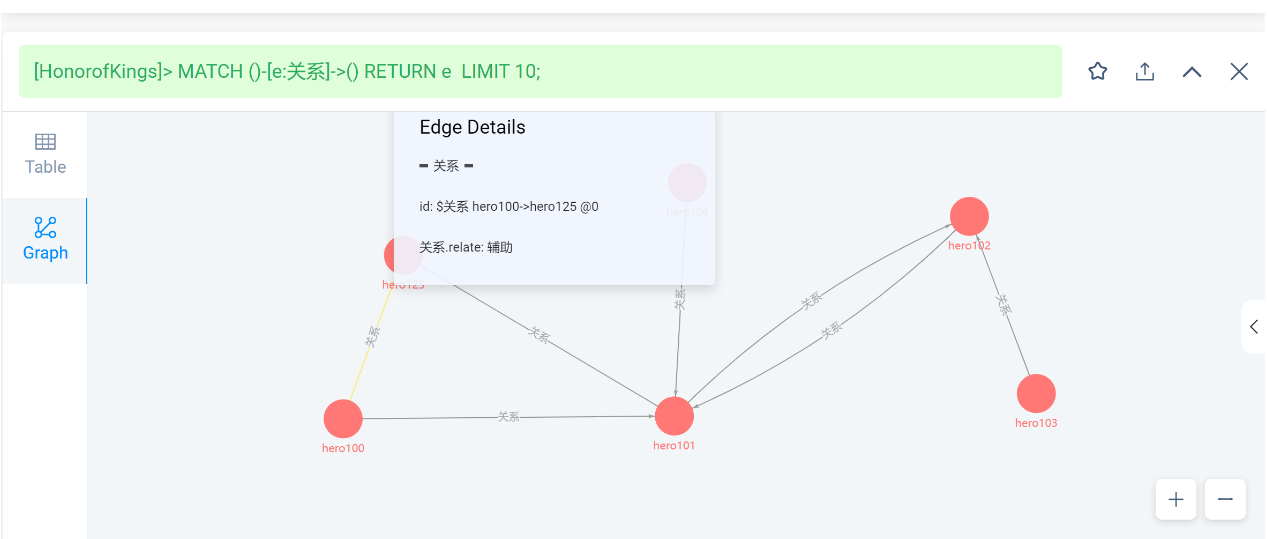
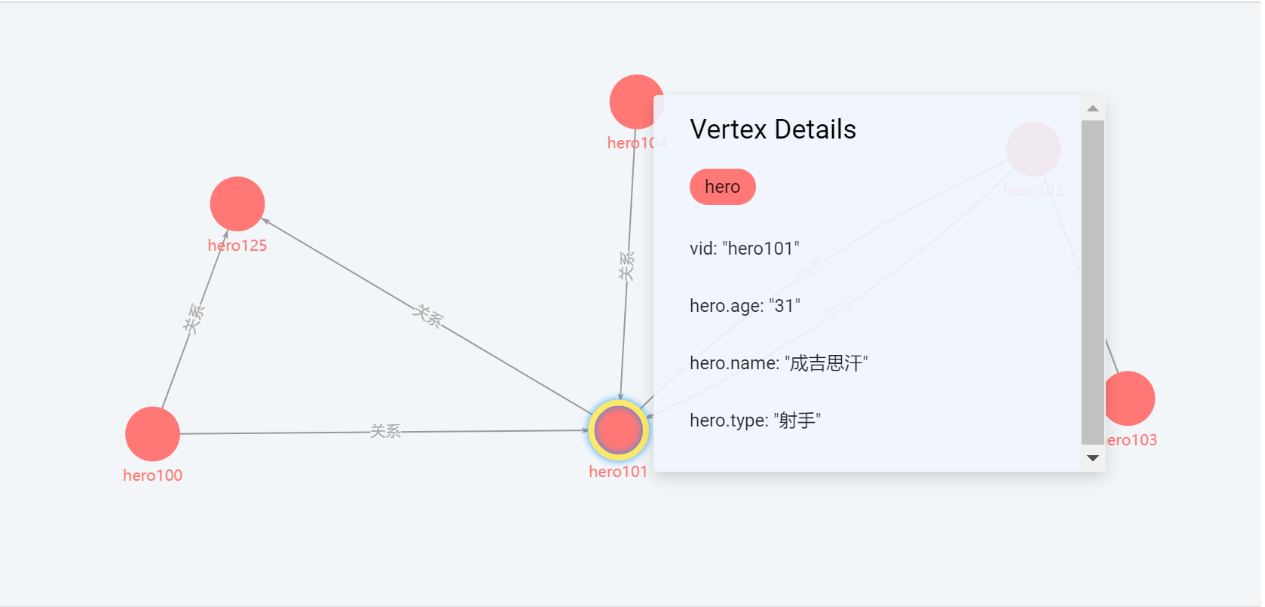
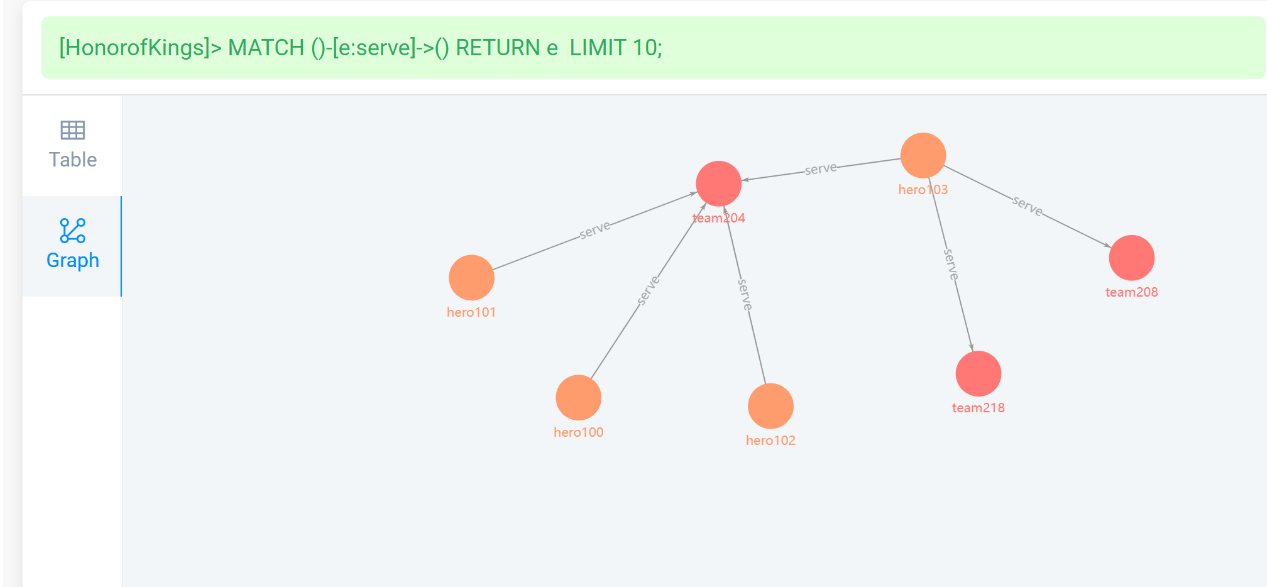
查看英雄之间的依赖关系【字符】,应用于关系查找,通过业务去确定。
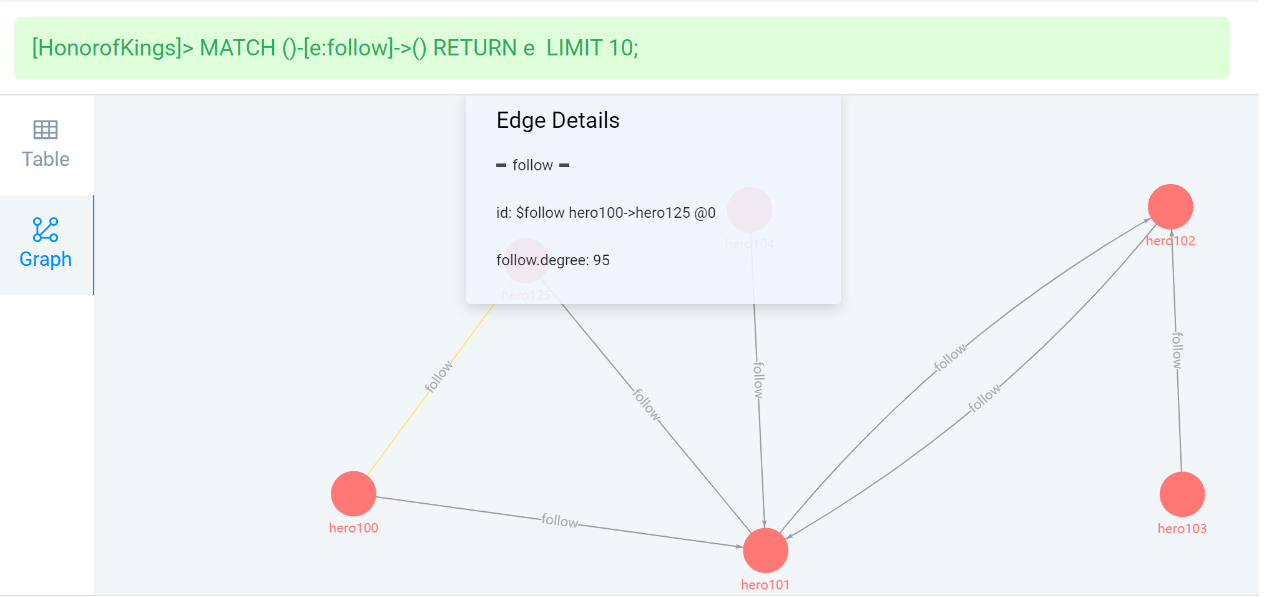
查看英雄之间的程度关系【数值】,应用于算法路径调优,通过业务判断量化。
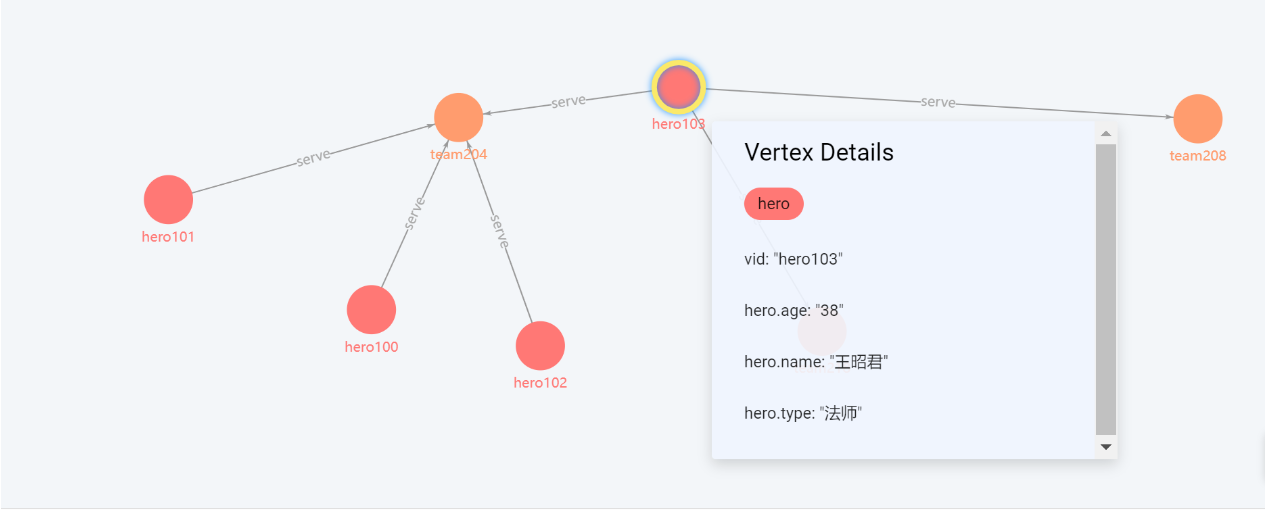
查看英雄属于联盟【时间范围 】,应用于关系,通过业务去衡量量化。
Nebulagraph如何赋能快速创建大模型
探索大模型的建设,NebulaGraph提供以下能力。
- 除了晦涩的Cypher语言,NebulaGraph支持简洁的nGQL,python api上支持使用nGQL的 update操作或者insert操作实现图模型的构建。
- 如果数据较多可以在源数据文件修改,再通过python的代码进行修改变更,数据导入可以通过图形化界面IMPORT 的方式实现数据导入。
- NebulaGraph支持第三方工具NebulaGraph Importer可以快速导入数据,这样意味着开发者可以通过CSV文件快速确定边的关系,然后进行模型构建。
- **Nebulagraph提供NebulaGraph Studio工具 进行图模型的顶点和边的关系结构构建。针对进一步的业务定制,**针对不懂技术的业务人员, NebulaGraph提供NebulaGraph Explorer分析工具,小白也能通过简单的拖拉拽进行图探索, 直接就可以在图形上可以自由修改模型参数, 选择适合业务的数据模型。
- NebulaGraph Explorer上直接就可以执行我多种丰富的图算法数据,马上得到响应反馈。
- 性能方面,NebulaGraph支持单机,也支持分布式,支持本地部署,也支持云部署 。假设大模型涉及的数据很多,通过NebulaGraph的技术架构扩展完成升级改造
结论
- 图模型相对关系模型、维度模型,在建模时必须要对业务了解更多,要花费更多时间,而且这是一个持续调优的过程。
- NebulaGraph的API以及nGql有助于减少建模花费的时间。
- NebulaGraph的生态建设丰富,除了支持主流hadoop、spark框架,也有对接其它主流数据库的能力。
- 从API和使用界面上,NebulaGraph在图建模考虑开发者和业务者的使用感受,考虑舒适的体验性以省心省力的指标,例如NebulaGraph Studio有一个
rebulid index的按钮,一键完成索引重构。
本文正在参加 NebulaGraph 技术社区年度征文活动,征文详情:https://discuss.nebula-graph.com.cn/t/topic/13970
如果你觉得本文对你有所启发,记得给我点个
,谢谢你的鼓励