机器配置如下:
机器数 12台
磁盘类型 普通硬盘
CPU 核数 40C * 12
内存大小 186G * 12
NebulaGraph 版本号 v2.6.2
图空间 schema
数据量,涉及到的数据量大概多少:
查询语句,需要调优的那条语句:
PROFILE go from '51b284301fb9114161cdfd9b39e105d5','55eb83c16b8e9f37569e0a86151afb24','29068789be05e6cc6d0b5839b0ca55fc','bfacdd51ffa9531bb30ada247defb9e6','4cbadbf321054b642accaf625ba940da','8f1c18a3c5ad5ffedd9a37b70680a802','76eb93519c55fe6ef93117e9299af879','b0f7455930fcc96a81f0b976df7a470a','51d5c94dcb9a359a1c065c2c77a1a67f','a1f976a3a80d193e3d265640e8639af1','4032c94176f9f182170b78e57a59bb6c','590592a406787368db036fd74c300270','2029710071a252db82c65b4d3248e091','44abc3a03f7405b5f92bec8b10cf1e88' over contain BIDIRECT where $^.domain.label == 'domain' and $$.report.label=='report' yield $^.domain.label,$^.domain.name,$^.domain.sld,$^.domain.dynamic,$^.domain.is_malicious,$^.domain.is_targeted,$^.domain.malicious_type,$^.domain.malicious_family,$^.domain.apt_group,$^.domain.is_tpd,$^.domain.ti_tags, contain._src, contain._dst, contain._dst as dst, contain._type, contain.ts,contain.label,contain.type, $$.report.label,$$.report.name,$$.report.ts ,contain.ts as ts| order by $-.ts desc,$-.dst desc | limit 0, 20
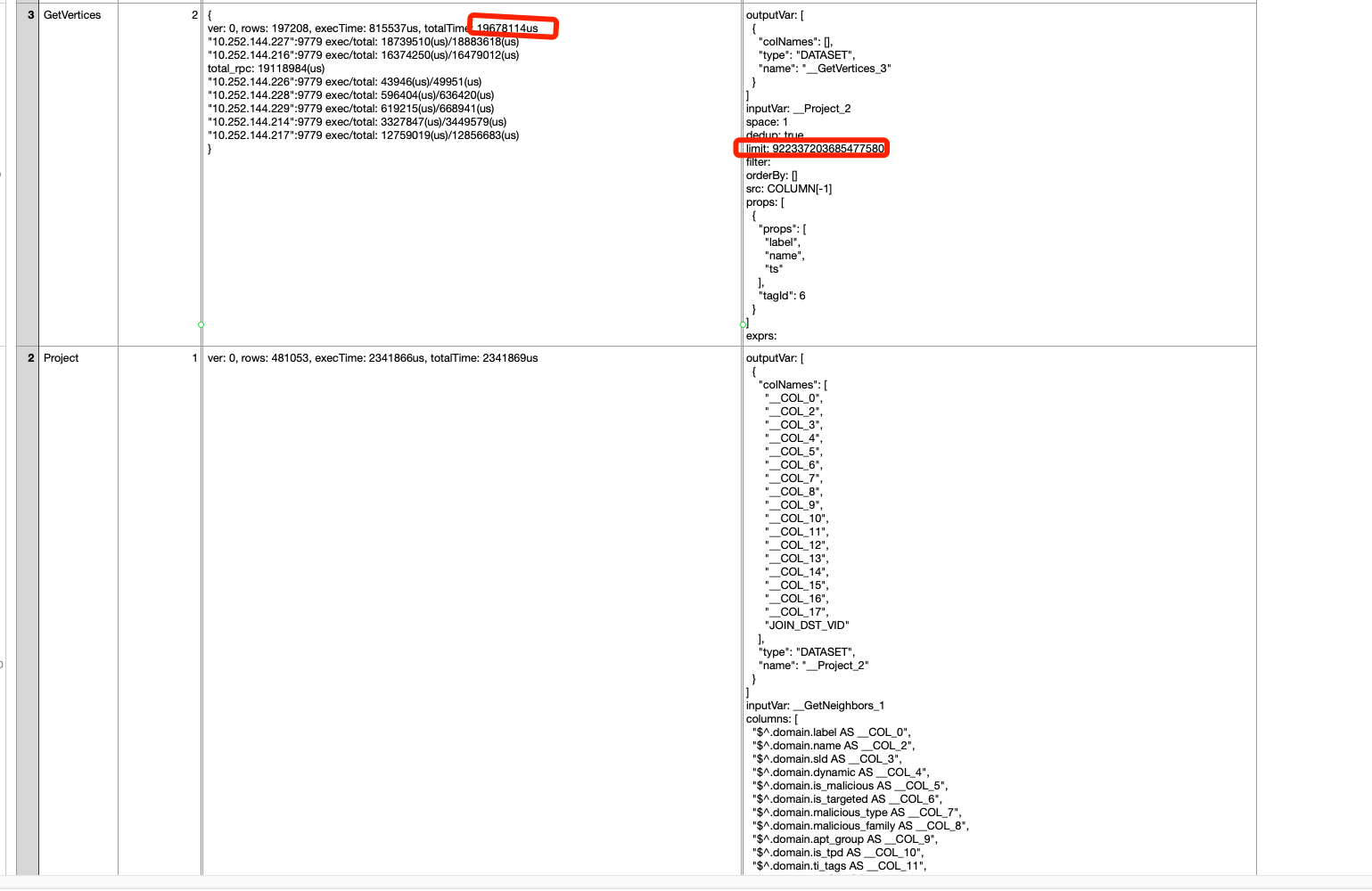
profile 信息,使用 profile query 语句,参考示例 2:
nebula> PROFILE format="row" SHOW TAGS;
Got 2 rows (time spent 2038/2728 us)
Execution Plan
result.csv (9.6 KB)