提问参考模版:
- nebula 版本:3.1.0
- 部署方式:分布式
- 安装方式:RPM
- 是否上生产环境:Y
- 硬件信息
- 磁盘 14T SSD
- CPU:72C
- 内存信息:512G
- 问题的具体描述
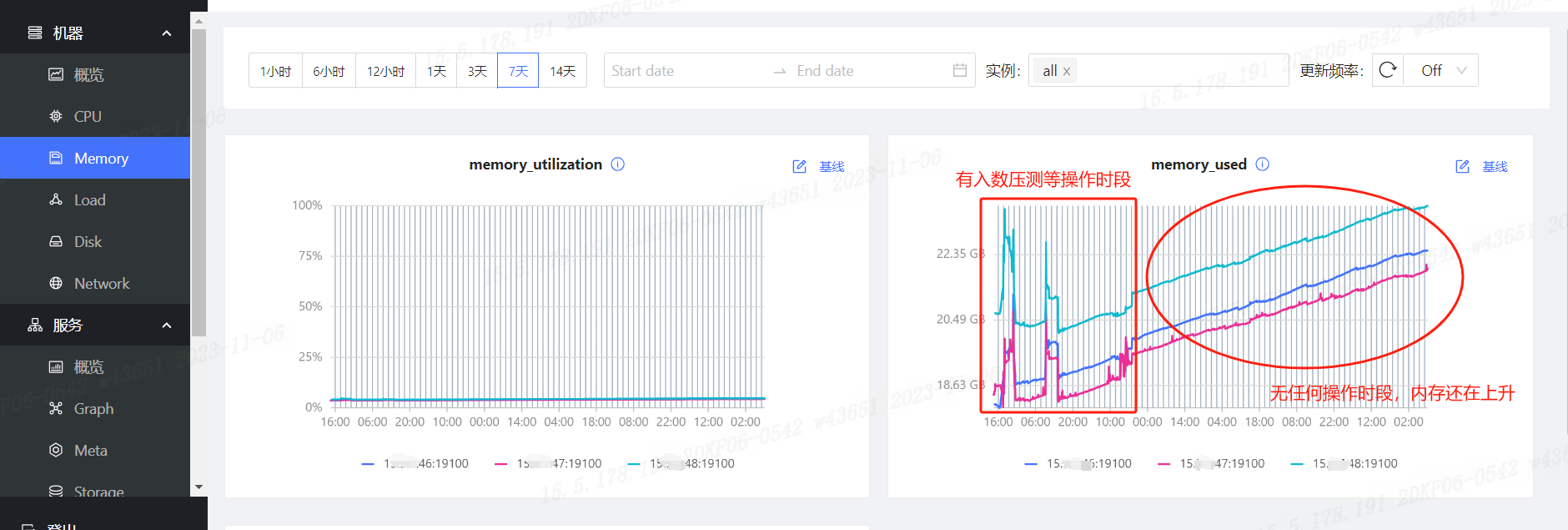
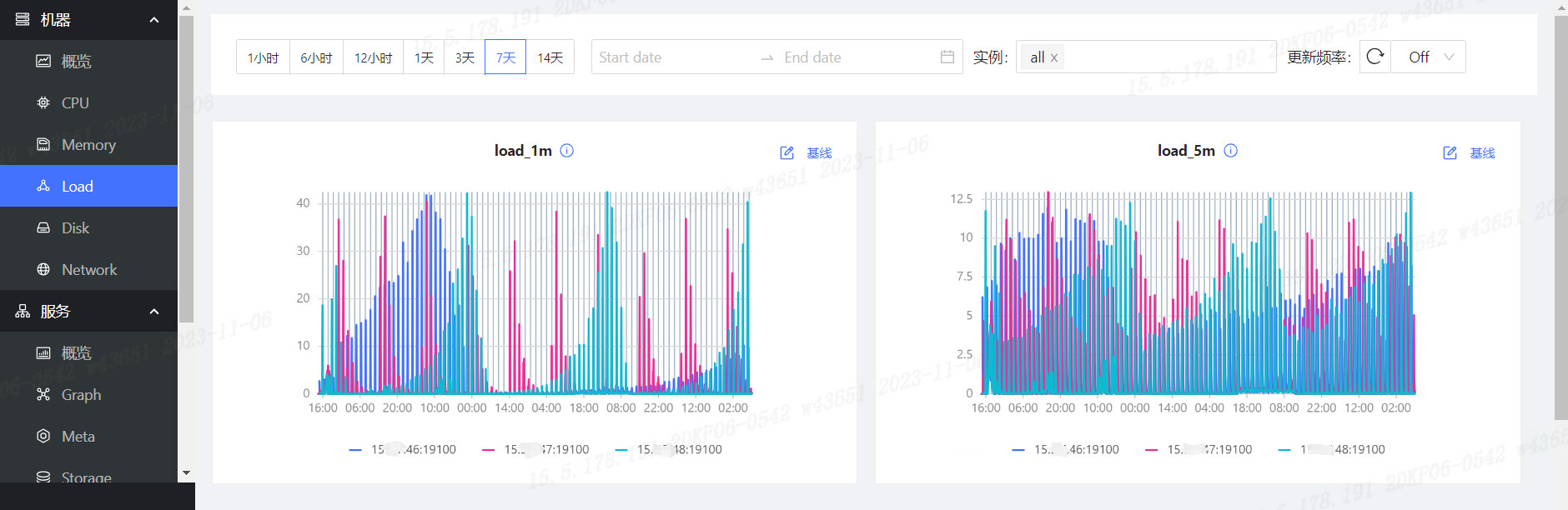
- 安装部署完nebulaGraph之后,导入数据进行压力测试,测试完成之后,发现dashboard监控到的几个指标不太正常
1.memory used在持续缓慢的增长(无使用时)。
2.load avrage存在间断性的大波动,在网上搜索了一下,都说该指标需要监控持续的情况,目前看,这个持续的压力情况是存在的,但是当前我们的集群是没有人在使用的,怎么负载也会这么高呢?
QingA
2
是否之前大批量写入了测试数据,在做自动compact
这地方包括的buffer占用的内存,看actual那个指标。
1 个赞
steam
6
对,有个新整理的内存相关的帖子,你可以看看:内存使用持续增加的原因
3.1.0版本的dashboard没有您说的那个指标,我安装的3.6.0的版本里才有
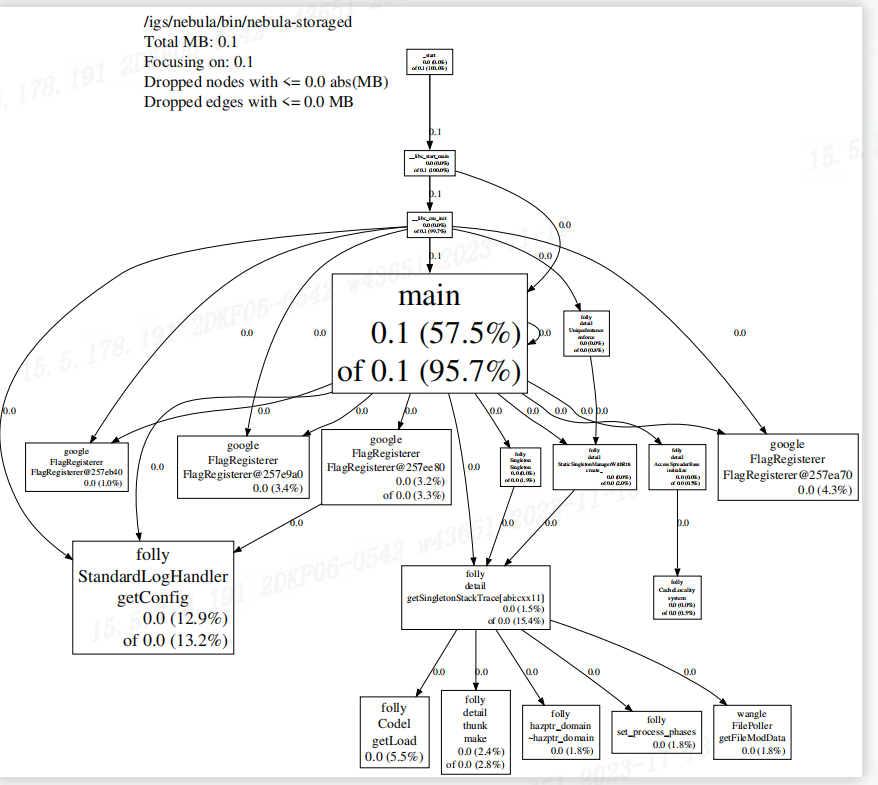
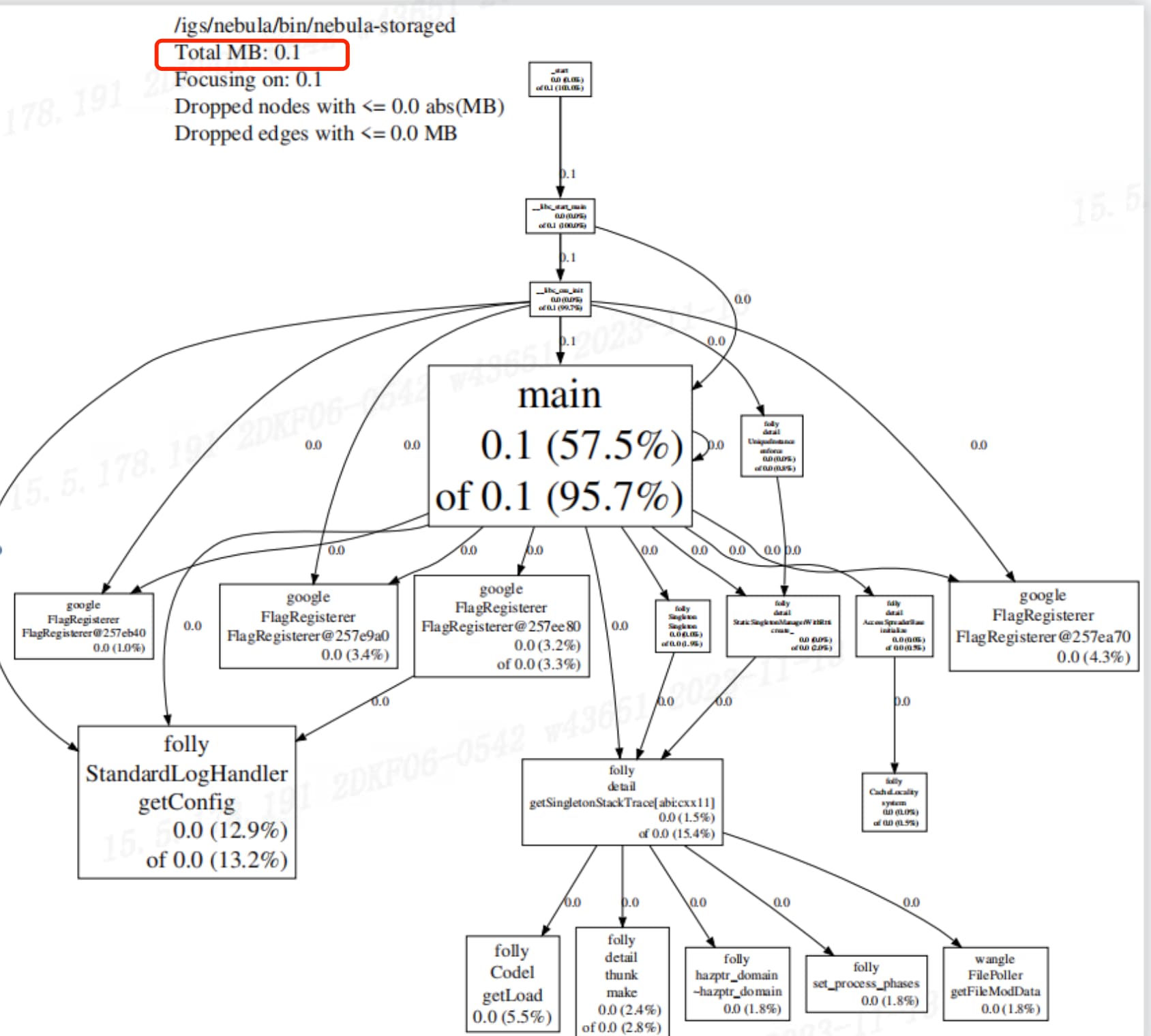
使用jemalloc分析nebula-storage的内存占用情况如下,请问这是什么情况?
pdf如下
steam
12
这里显示了 storage 的内存占用并不是很高,0.1 MB。系统如果内存占用高的话,不一定是 nebula 导致的,你可以用 free -h 看下具体的内存使用情况。
这个会不会和我获取内存文件的命令有关系呢?因为实际在dashboard里看到的内存是在持续增长的,我们自己用top命令监控了nebula-storaged的进程的内存使用情况,也是在持续增长的
我生成文件的命令如下:
得到的jeprof.heap之后
通过jeprof --pdf /igs/nebula/bin/nebula-storaged jeprof.heap得到的pdf文件结果
steam
14
就是你看这个进程占用的资源只是 0.1 MB,不算高的,你看我上面的命令,你先用 free -h 看下内存的分布
查到的结果如下,但是这个结果跟dashboard上监控到的结果还不一致。。。。
dashboard上监控到的这个时间点的内存是6.7G左右
我看cached占用量比较大,就手动回收了一下,内存占用情况如下
话说你这个节点部署了什么服务?
是否还有其他的内存开销的进程?Dashboard这里的监控是针对节点的监控
memory_used 这个指标,是包括了buffer和cache的,实际使用对不上吗?要不你直接查promeheus看下监控数据是否正确?
部署nebulagraph的三个服务节点和监控服务,目前监控看到是storaged在持续增长
promethous里没找到memory_used这个指标呢,是叫其他的名字么
memory_used = node_memory_MemTotal_bytes{instanceName=“your instance”} - node_memory_MemAvailable_bytes{instanceName=“your instance”}