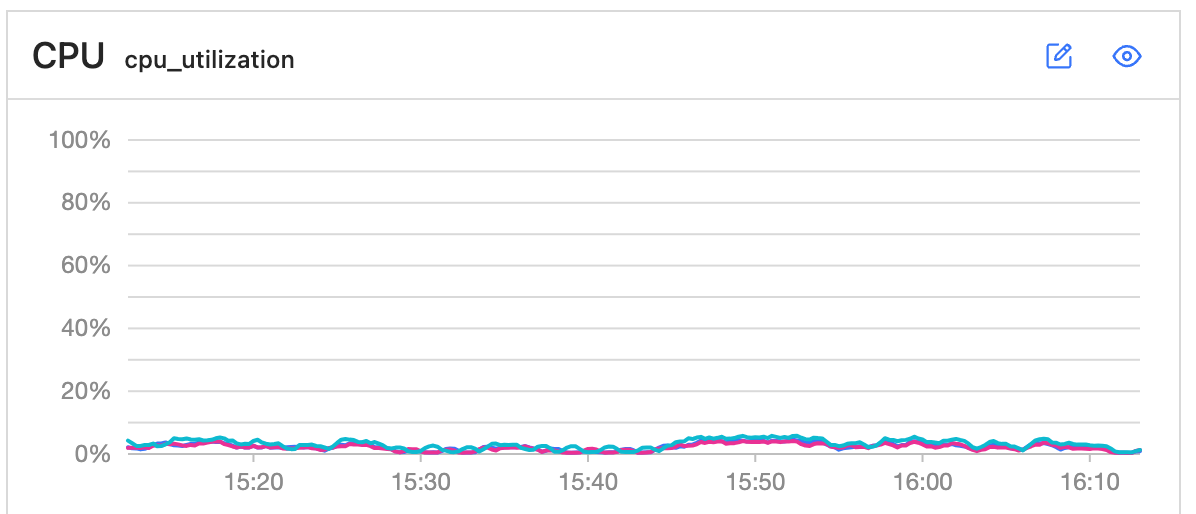
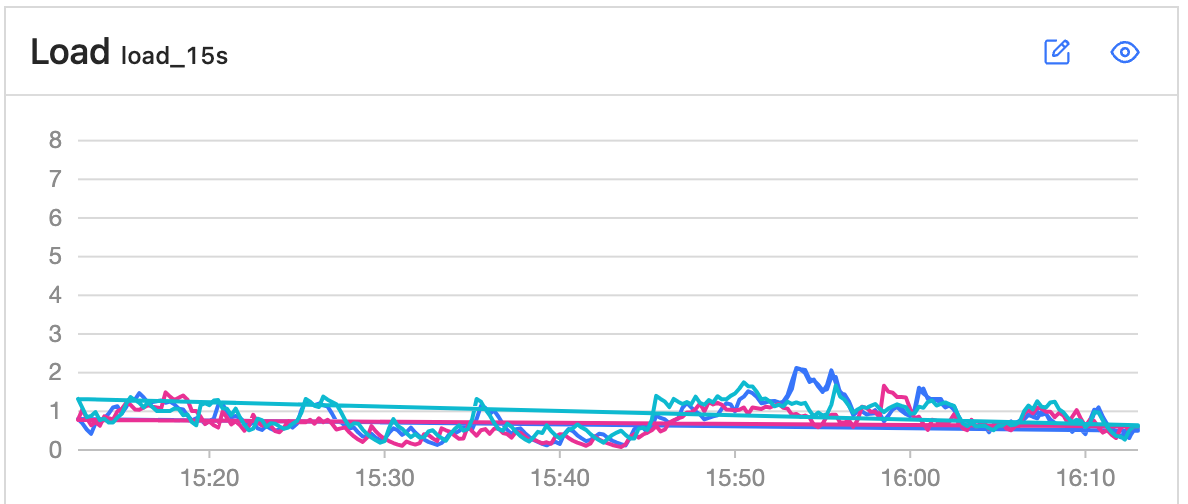
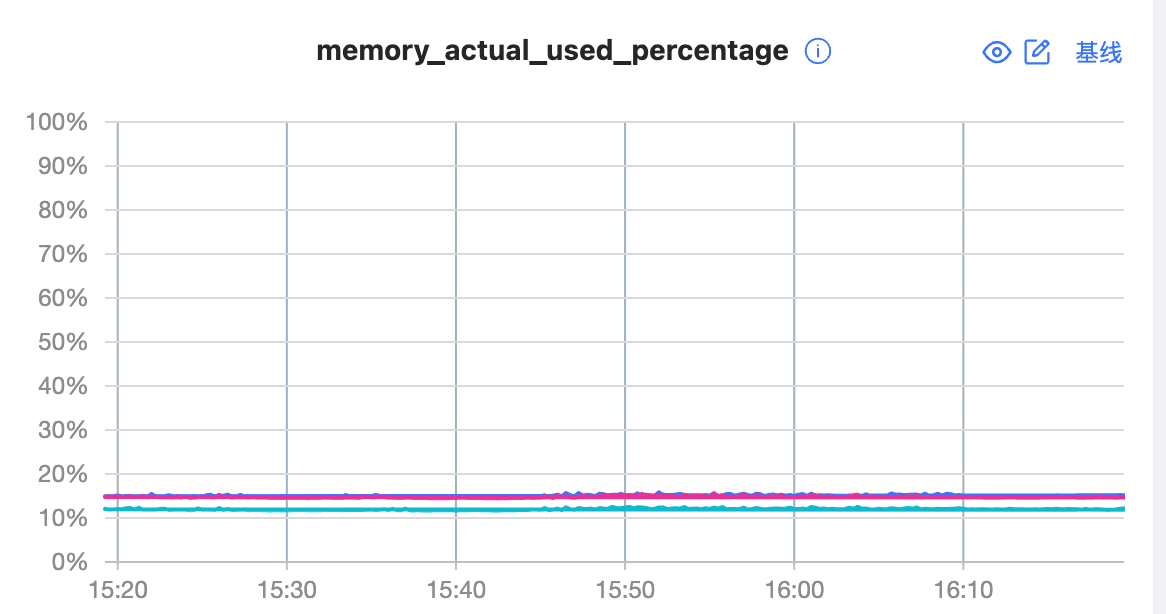
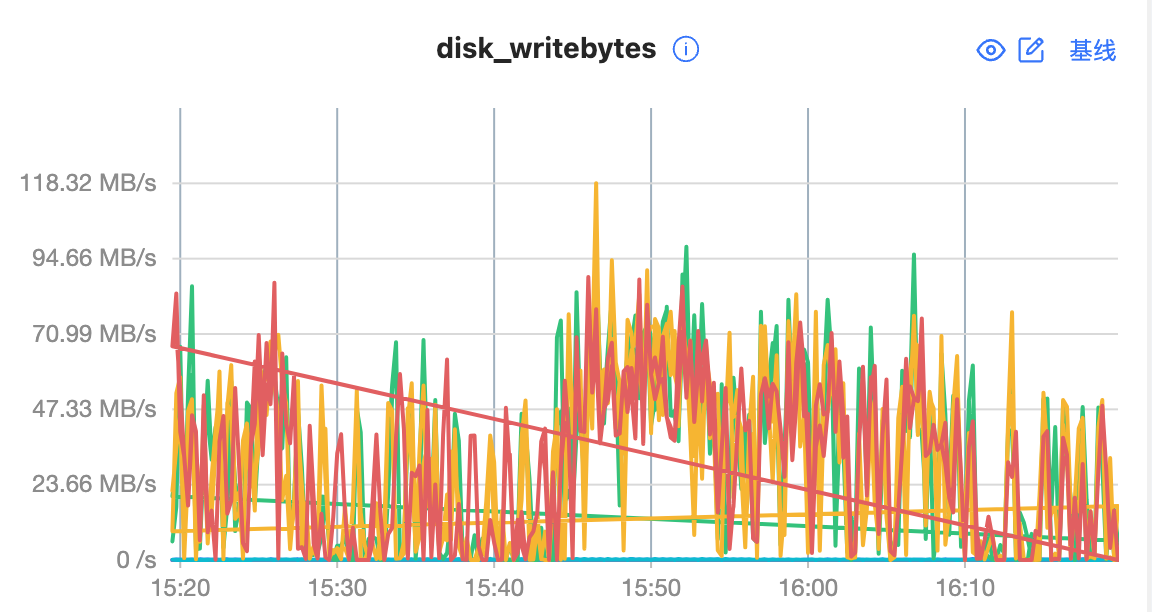
目前使用python导入数据,但是我发现机器的内存消耗不高、cpu很低、磁盘写入速度不到100MB/s,即使增加再多的进程数,相同数据量下,导入速度依旧相差不大。写入4千万条数据,时间在5小时左右
当前集群:graph、meta、strage各3个节点,配置是 32核、96GB内存、4*1TB SSD
Space vertices 72564603
Space edges 484686172
目前使用python导入数据,但是我发现机器的内存消耗不高、cpu很低、磁盘写入速度不到100MB/s,即使增加再多的进程数,相同数据量下,导入速度依旧相差不大。写入4千万条数据,时间在5小时左右
当前集群:graph、meta、strage各3个节点,配置是 32核、96GB内存、4*1TB SSD
Space vertices 72564603
Space edges 484686172
贴一下你的代码,自己通过client写入,导入速度跟 并发、批量写入、多线程下client的使用方式,连接的graphd数量等都有关系。
如果是一条一条写入导致的,可以试试批量写入:
for row in tqdm(datas, desc="创建节点进度:"):
try:
n += 1
vid = row[0]
names = row[1]
address = row[2]
ngql_vertex += [
f"'{vid}':('{names}','{address}')"
]
if n == 500: # 批量写入条数
ngql_node = "INSERT VERTEX `tag` (names,address) VALUES " + ",".join(ngql_vertex) + ";"
resp = session.execute(ngql_node)
assert resp.is_succeeded(), resp.error_msg()
n = 0
ngql_vertex = []
except Exception as e:
print(e)
if n > 0:
ngql_node = "INSERT VERTEX `tag` (names,address) VALUES " + ",".join(ngql_vertex) + ";"
try:
resp = session.execute(ngql_node)
assert resp.is_succeeded(), resp.error_msg()
except Exception as e:
print(e)
嗯,用的就是这个方法
我说一下代码逻辑吧,原始代码里有很多业务逻辑,就不贴了。
insert使用的是批量写入,语句是 insert vertex user vid:(name1, kind1, status1),vid2:(name2,kind2, statu2) 每次批量写入1000个。
并发方面,每次开10个进程,每个进程都是单线程写入,同步等待 execute 返回后,再执行下一次操作。
session配置如下:
config = SessionPoolConfig()
config.min_size = 3
config.max_size = 9
这地方,无论我开10个进程,还是20个进程,总体上写入4千万条数据时间差不多。另外,其他逻辑时间也打印了,主要还是在写入图数据库这块。
你把批量插入的latency和客户端执行语句的时间都打出来看看正常吗,如果正常的话,看样子还是客户端的压力没上去
嗯,我再试试
此话题已在最后回复的 30 天后被自动关闭。不再允许新回复。