本文主要回复 NebulaGraph 年度征文活动的选题二:数据库的内存都用在了哪里?
数据库作为常驻在计算机上的程序,需要在各种场景下使用软硬件资源,其中大家最关心的资源之一就是内存。内存既要服务前台的需求,如增删改查语句;也要服务后台的需求,如 Compaction、Raft 同步 等。NebulaGraph 中的 graphd、storaged、metad 三大服务在使用内存方面也各有千秋。那么,到底有哪些地方需要使用内存?它们都需要使用多久?我们应该如何理解内存用量的监控曲线?如何设置合理的内存用量告警机制呢?
回题,在 NebulaGraph 中哪些地方会用到内存呢?
一般数据的内存消耗点
一般来说,数据库会在下面的地方都会用到内存:
- 线程池:针对新用户,数据库服务端可能会选择一个进程或者一个线程连接会话。
- 计算:对用户的 SQL 请求进行解析,一般数据库服务端会有关系代数的计算,尤其多表关联,涉及二元的运算,消耗特别多的内存。此处NebulaGraph 虽然不是关系代数,但是也会耗费内存。
- 缓冲区: 对已经进行 nGQL 解析后的请求,将其结果保存在缓冲区,同样请求不需要额外解析,缓冲区内存资源越大越好。
- 索引:数据库的索引额外会占用内存,正常设置占用不多。
- 日志:一般数据库至少写两次日志,一个是数据库持久化,一个是数据库恢复日志,牵扯到分布式数据,还需要选举投票日志以及一致性日志。
- 健康巡检:进程间通讯或者线程之间的监测线程,巡检角色是否健康.
- 元数据协同:数据库中心分派唯一事务 ID 或者协同其它角色达成一致认识,需要频繁与其它组件进行协作。
- 锁:常规数据的读写操作都会涉及到锁,这是一个频繁的操作。
- 锁管理器:全局共享的数据比如索引数据,表元数据,资源信息等,都必须保障多线程环境下的可靠运行,所以这种锁管理器无疑会消耗更多的 CPU 资源。
- 后台管理:主要负责监控、归档、恢复等工作。
- 清理守护:主要是内存到数据中的同步,例如内存脏页的守护进程 ,达到阀值就把新数据刷到硬盘上,LSM的增量数据刷新到硬盘上,同时释放内存中的资源
NebulaGraph 工作流程
除了上面的通用情况,具体到图数据库 NebulaGraph。我们先来看看它的工作流程:
- 用户发起请求,数据库客户端发起请求到指定的 NebulaGraph集群中;
- 目标数据库响应,NebulaGraph 数据库集群指定一个 nebula-graphd 节点响应用户的请求;
- 两者建立会话,nebula-graphd 客户端产生会话;
- 对象请求解析,nebula-graphd 接收的请求进行图语法检查、对象解析,并与 nebula-metad 紧密沟通,nebula-metad 提全局唯一号、时间戳以及数据位置;
- 调度并且执行,根据客户需求,选合最适合的 nebula-storaged,nebula-storaged 通过 raft 与其它 nebula-storagd 保持数据同步;
- 任务运行状态,数据库持续执行读写中,NebulaGraph 内置 RocksDB,增量内存会持久化生成第一层级的 SST,大的 SST 需要更多层级的 SST。
- 返回数据结果,数据库服务端返回结果给数据库客户端。
测试环境背景
下面,我们来实操下,看下具体的内存消耗情况。
服务端
| 服务器 | IP | 角色 | 系统 | CPU | 内存 |
|---|---|---|---|---|---|
| 虚拟机 | 192.xxx.xxx.128 | nebula-graphd、nebula-storaged、nebula-metad | CentOS 7.6.1810 | 8核 | 8G |
客户端
| IP | 角色 | 系统 |
|---|---|---|
| 192.xxx.xxx.18 | Python PyCharm + Nebula Client + Coding | Windows 11 |
测试用例
- 连入 nebula 后,高并发同时创建多个Space,参数设置是1亿个Space,观察DDL下的内存消耗
- 连入 nebula 后,高并发同时创建10个 Space,每个 Space 生成 1 亿条点数据和 1 亿条边,观察DML下的内存消耗;
- 将 CPU 核数进行等级划分,划分为:2 核、4 核、8 核、16 核等 4 档,观察数据写入状况,以及内存消耗;
写操作:这里主要是增加(新增数据),Python 客户端调到 200 并发,1 个并发写入 1 亿数据;
读操作:安装过 nebula-studio 之后,在 nebula-studio 的网页链接:http://ip:7001/schema/statistic/list,点击 refresh,这个按钮相当于提交统计 job,并进行相关的数据统计结果返回。
点击之后,能看到目前的点、边、Tag 和 EdgeType 的数据量。
内存使用状况观测
dstat -cmndst:查看CPU、内存、网络、磁盘工作状态top -p nebula-graphd nebula-storag nebula-metad:查看 res 使用内存top -H -p nebula-graphd nebula-storag nebula-metad:查看使用线程
nebula 调优参数
官方建议的 Storage 和 Graph 优化参数:
NebulaGraph Storage 服务优化配置项:
--rocksdb_block_cache数据在内存缓存大小,默认是 4 MB,大批量数据导入时可以设置到当前内存的 1/3;--num_worker_threads storaged的 RPC 服务的工作线程数量,默认 32;--query_concurrently为true表示 storaged 会并发地读取数据,false表示 storaged 是单线程取数;--rocksdb_db_options={"max_subcompactions":"48","max_background_jobs":"48"}:可用来加速自动 Compaction 过程;--rocksdb_column_family_options={"write_buffer_size":"67108864","max_write_buffer_number":"5"},在刚开始导入大量数据时可以将disable_auto_compaction选项设置为true,提升写入的性能;--wal_ttl=600在大量数据导入时,若磁盘不充裕,那么该参数需调小,不然可能会因为产生大量的 wal 导致磁盘空间被撑满。
NebulaGraph Graph 服务优化:
再简单地罗列下 Graph 服务相关的一些优化配置项:
--storage_client_timeout_ms为 graphd 与 storaged 通信的超时时间;--max_sessions_per_ip_per_user是单用户单 IP 客户端允许创建的最大 session 数;--system_memory_high_watermark_ratio设置内存使用量超过多少时停止计算,表示资源的占用率,一般设置为 0.8~1.0 之间;--num_worker_threads为 graphd 的 RPC 服务的工作线程数量,默认 32。
测试记录
内存占用
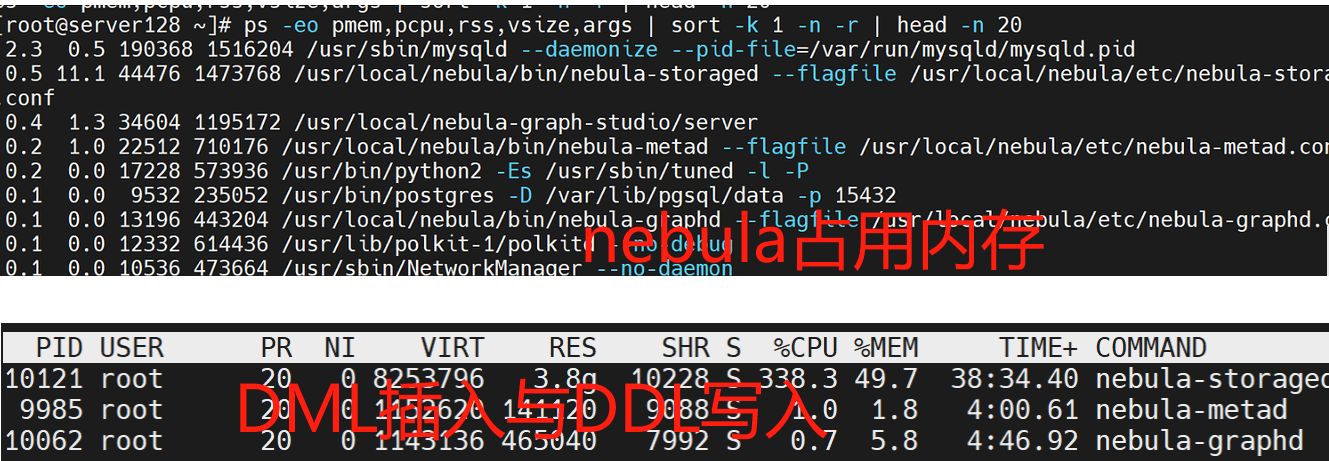
DML下,nebula-storaged 最吃资源,其次是 nebula-graphd,最后是 nebula-metad。
在数据持久化后进入rocksDB后,内存释放后, nebula-storag占用的内存资源与单点mysqld不相上下。
DDL下,同样是nebula-storaged的内存资源最大,其次是 nebula-graphd,最后是 nebula-metad。笔者先入为主,以为是DDL操作,nebula-metad占用的资源会更多,根据事实的反馈,发现是我错了。依据此特征表现,生产集群设计,可以把最好的资源投入 nebula-storaged,其次是 nebula-graphd,最后是 nebula-metad。
内存隔离

10 个线程创建 Space 后,持续写入 1 亿数据过程中,彼此之间会互相影响,因为 nebula-storaged 会持续扩大,进而影响到 nebula-graphd,从而触发 nebula-graphd 的内存水位线。
内存释放
随着数据量的增大,nebula-storaged 会不断的占用内存,而且一直不释放。数据写入 5,000 万的时候,停掉写数程序。当前 nebula-storaged 占用 2.3G 内存:
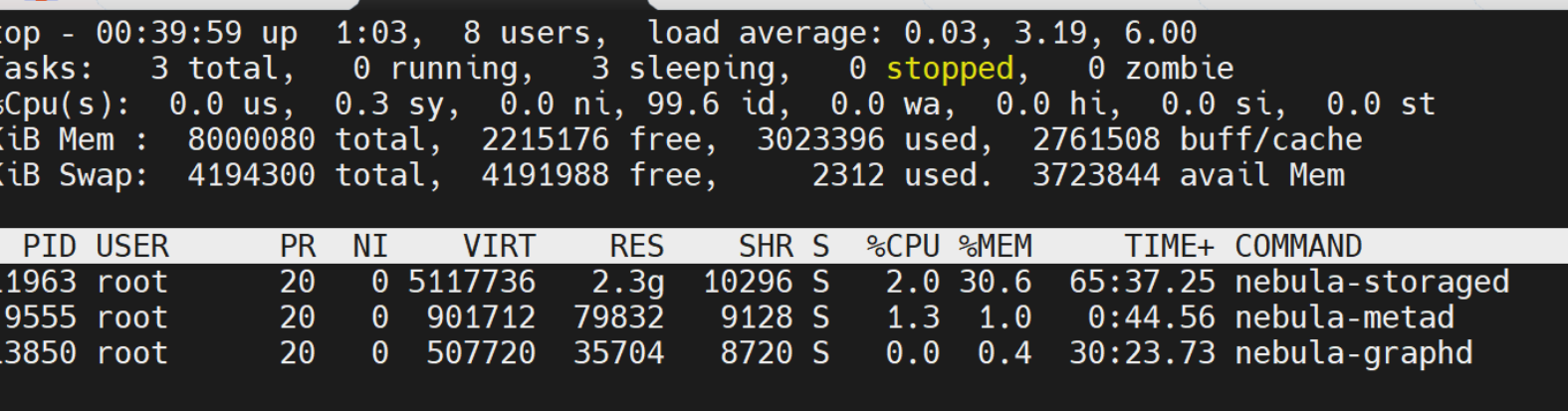
停掉程序后,可以看 CPU 完全空闲,但是内存一直没有释放:

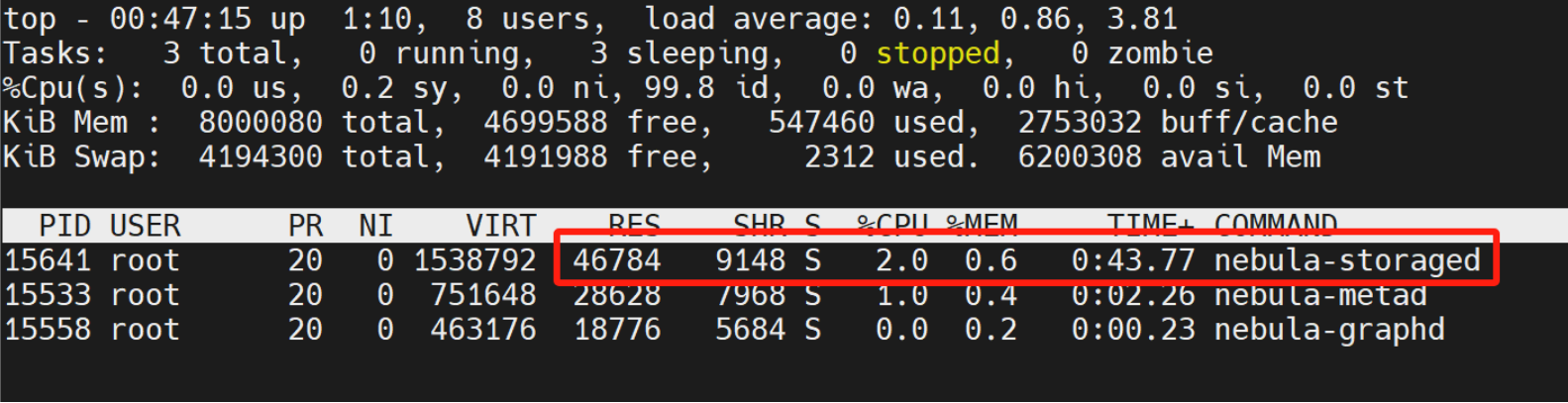
把 nebula-storaged 服务重启后,nebula-storaged 的内存降到最低点:
CPU 与数据写入
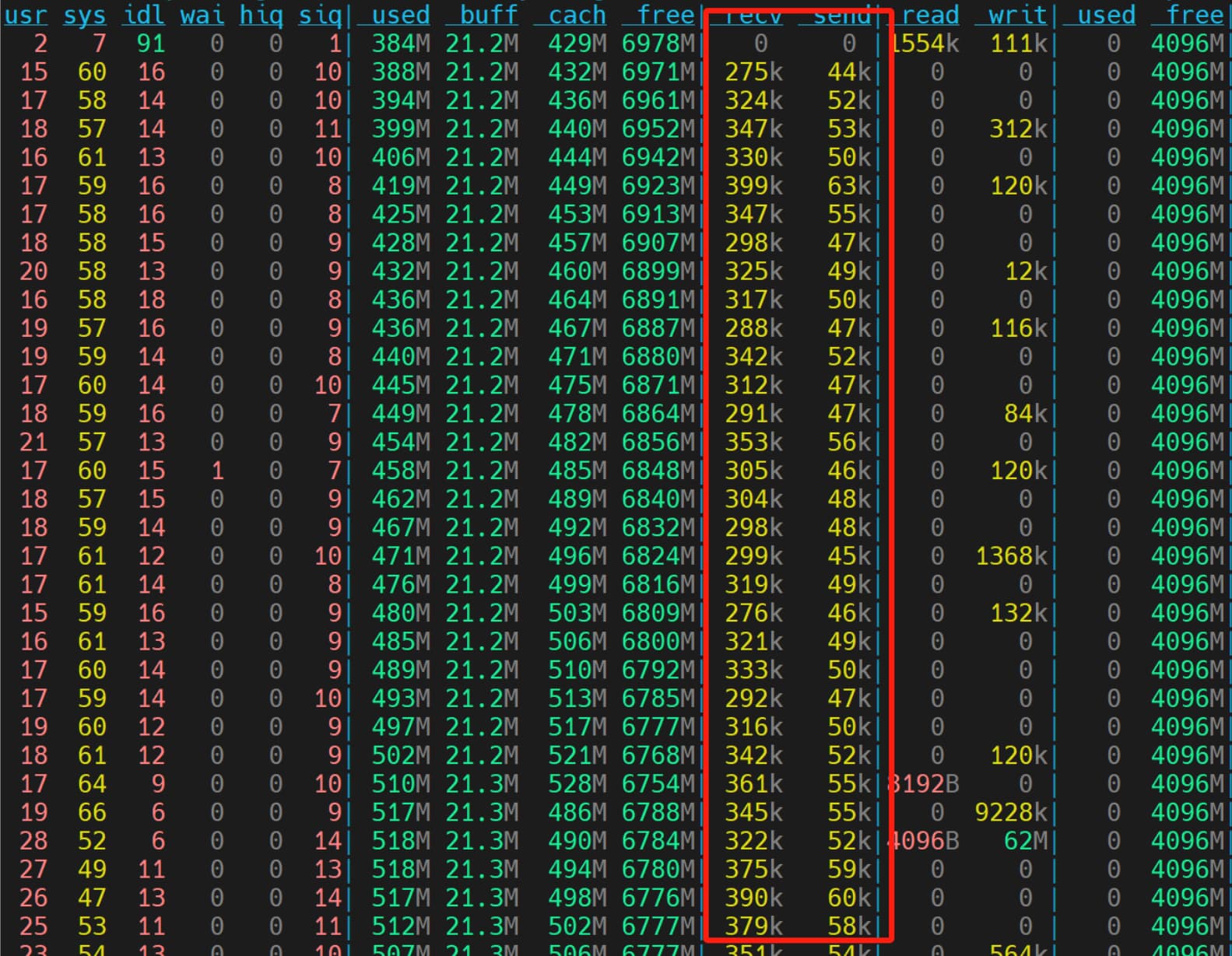
CPU 个数决定程序的数据写入速度,间接验证 RocksDB 是多线程的。2 个 CPU 的网络写入约是 300 KB,4 个 CPU 的写入网络是 500 KB,8 个 CPU 的写入网络 800 KB 左右,16 个 CPU 的网络高峰写入是 2,000 KB 左右。
CPU 个数越多,越有助系统稳定,尤其协助数据落地到硬盘的时候。



结论:NebulaGraph内存上哪里了
- nebula-storag在内存管理占了大头,在数据读写中起了重要的作用。当只有数据持续只有写入时【没有其它读操作】,nebula-storag的内存容量渐渐加大,后台compact落盘后,内存会有回收。CPU个数越多有助于内存回收。
- 面对重复插入的数据,nebula采用忽略掉的机制。假使数据长度不符合不能写入nebula-storage,将会都写入nebula-storage的err日志上,不会占用内存。
- 当CPU个数较少,compact落盘释放内存资源的速度慢于 写入数据的速度,内存会持续上升冲破水平警戒线。
- 读操作统计Tag和Edge个数,假设个数太多将耗费nebula-storag大量的内存,如果nebula-storag有写入操作,很容易令nebula进入崩溃状态。
- nebula-storag的内存占用释放很慢,但是可以通过重启nebula-storag服务来释放。
- nebula-storag的锁、索引 、日志、健康巡检、清理守护方面都用不上很多,目前来使用内存最多的地方是nebula-storage。从技术的机制来看,nebula-storage是基于rocksdb基础的研发的,增量数据会在nebula-storage开辟内存区,读数据也会从nebula-storage开辟内存区,增量数据活动的过程中反复compact以及merge都会占用内存,数据持久化到硬盘后释放多少内存也是未知之数。
建议:对nebula的内存监控指标
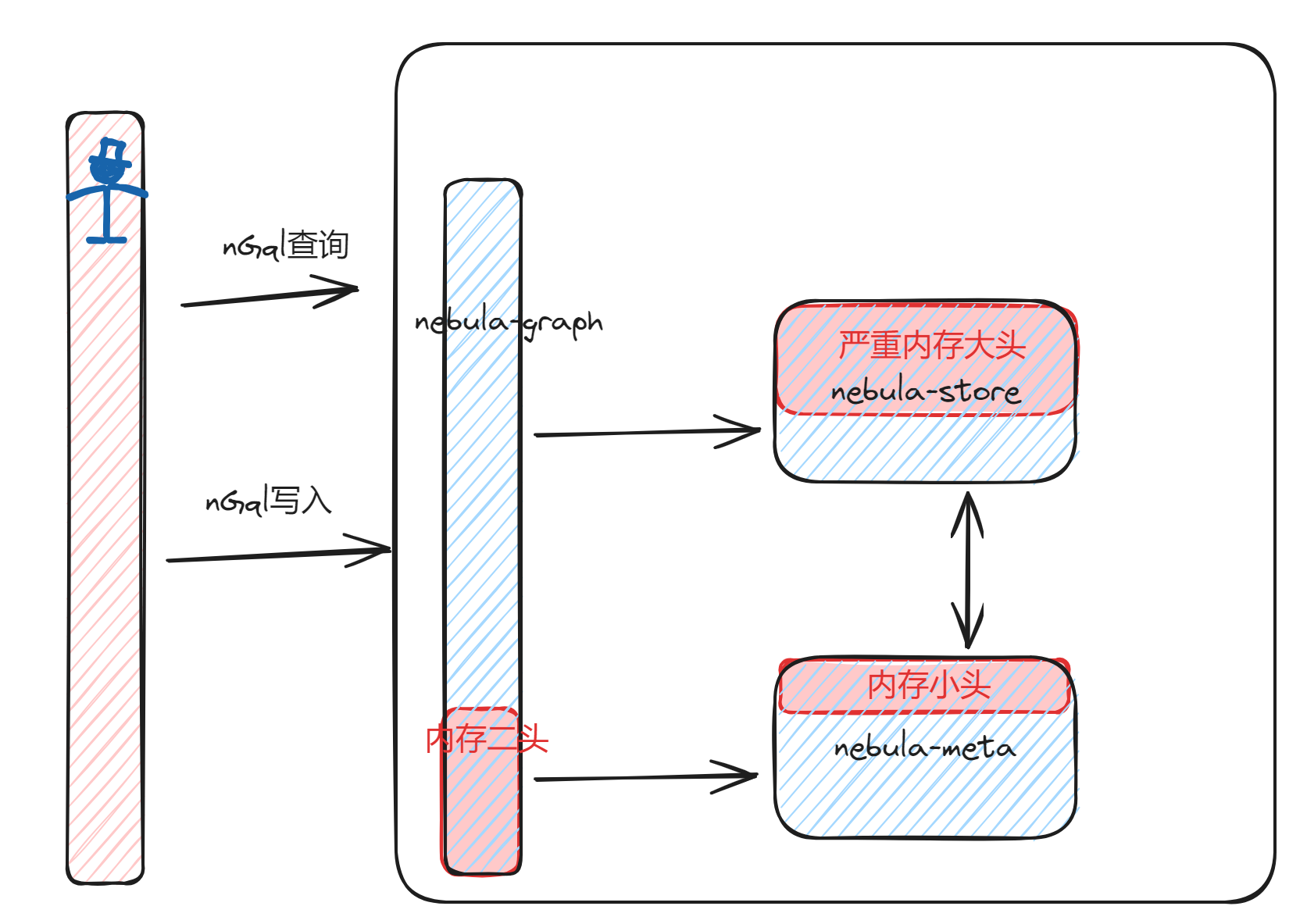
- nebula-store的全局内存使用状态,包括graphd、metad的内存,三点占据系统内存的比例方式来表达。
- nebula-store里面rocksdb协作写入产生的缓冲区内存,主要是数据写入到nebula-store后对应产生的内存量。
- nebula-store里面的针对 rocksdb的全生命周期监控。
- nebula-store里面读取产生的缓冲区内存,主要是数据读取产生缓冲区内存。
- CPU核数与nebula性能关系很大,即使内存再高,CPU没有对齐,不能发挥好的效果,所以检测到 CPU个数太少,系统会自动提醒。
- **以后技术路线发展道路上,DML、DDL、WAL日志、UNDO日志、表空间、模式、缓冲、批量导入、备份、还原、SQL解析、事务操作、分析操作、后台管理这些有独立的内存管理空间当然更好。**当前亟待解决的一个问题,点击 refresh,这个按钮相当于提交统计 job,并进行相关的数据统计结果返回。假设数据量很大, 读取的操作将耗费nebula-store大量的内存,检测到这个行为,系统应当可以自动提醒。可以参考openGauss对于数据库单条语句进行内存使用限制,set query_max_mem预估占用内存,将提示报警。
- 每个 nebula-store 实例的使用的存储空间的大小以及可用的存储空间的大小
- nebula-store的CPU使用情况
- nebula-store内存的使用情况,与graphd、metad的交互通信请求
- nebula-store写入和读取的数据大小,以及造成的IO使用率
以上,为 NebulaGraph 内存使用的分析。
本文正在参加 NebulaGraph 技术社区年度征文活动,征文详情:https://discuss.nebula-graph.com.cn/t/topic/13970
如果你觉得本文对你有所启发,记得给我点个
,谢谢你的鼓励