Reid00
1
提问参考模版:
- nebula 版本:3.4.1
- 部署方式:分布式
- 安装方式:RPM
- 是否上生产环境:Y
- 硬件信息
- 问题的具体描述
- 相关的 meta / storage / graph info 日志信息(尽量使用文本形式方便检索)
hi @wey 看到你的项目可以跑ngql nebula-up/spark/pagerank_example.ipynb at main · wey-gu/nebula-up (github.com)
想问个问题,如果我想跑subgraph 该如何做?尝试了下
- label 不能写多个
- 语句为GET SUBGRAPH WITH PROP 2 STEPS FROM ‘f625a5b661058ba5082ca508f99ffe1b’ BOTH HasCompany,Controlled YIELD VERTICES as v, Edges as e
目前这个有办法解决吗?
# option 1: read graph data with ngql, get data from graphd
df = spark.read.format(
"com.vesoft.nebula.connector.NebulaDataSource").option(
"type", "edge").option(
"spaceName", "basketballplayer").option(
"label", "follow").option(
"returnCols", "degree").option(
"metaAddress", "metad0:9559").option(
"graphAddress", "graphd:9669").option(
"ngql", "MATCH ()-[e:follow]->() return e LIMIT 1000").option(
"partitionNumber", 1).load()
我的
df = (
spark.read.format("com.vesoft.nebula.connector.NebulaDataSource")
.option("type", "edge")
.option("spaceName", SPACE)
.option("label", "HasCompany")
.option("returnCols", "role")
.option("metaAddress", metaHost[cluster])
.option("graphAddress", graphHost[cluster])
.option("partitionNumber", 1000)
.option("operateType", "read")
.option("ngql", "GET SUBGRAPH WITH PROP 2 STEPS FROM 'f625a5b661058ba5082ca508f99ffe1b' BOTH HasCompany,Controlled YIELD VERTICES as v, Edges as e")
.load()
)
wey
2
目前 spark connector 的 ngql reader 实现的很懒,只支持了 match  ,对于任意query result 的支持理论上不难,只需要把查询写一下迭代的 cast 逻辑就可以,但是还没人做
,对于任意query result 的支持理论上不难,只需要把查询写一下迭代的 cast 逻辑就可以,但是还没人做
wey
3
看了一下实现,似乎只解析了两种类型的 value, edge 和 list of edge,比我想像的多一种情况,而且会白名单对照 edge 类型,你的 return 如果改成只有 edges AS e 没有 vertex 现成的实现应该是可以解析的,试试?
wey
5
嗯嗯,我说你改一下query本身哈,不用动 spark connector,只 return edges 感觉就可以(我也不会 java scala)。
我无 scala/java 知识撸了一个 pr ,感觉主要还是那个 raise ,改善一下这个情况,有了 feat: support path in nGQL, not raise exception for other types by wey-gu · Pull Request #133 · vesoft-inc/nebula-spark-connector · GitHub 应该 FIND PATH/GET SUBGRAPH/复杂的大多数 MATCH 也都支持了。
Reid00
6
感谢大佬,试了下return edges 是行的,但是有问题,
df = (
spark.read.format("com.vesoft.nebula.connector.NebulaDataSource")
.option("type", "edge")
.option("spaceName", SPACE)
.option("label", "HasCompany")
.option("returnCols", "role")
.option("metaAddress", metaHost[cluster])
.option("graphAddress", graphHost[cluster])
.option("partitionNumber", 1000)
.option("operateType", "read")
.option("ngql", "GET SUBGRAPH WITH PROP 2 STEPS FROM 'f625a5b661058ba5082ca508f99ffe1b' BOTH HasCompany,Controlled YIELD VERTICES as v, Edges as e")
.load()
)
- 在这个里面, label 只能指定一个HasCompany, 导致 语句里面即便写了多个边类型 也是无效得,这个能怎么解决吗?
- returnCols 里面 有办法返回edge 的type吗?
我看正常Console 里面返回的meta 信息里面是有的
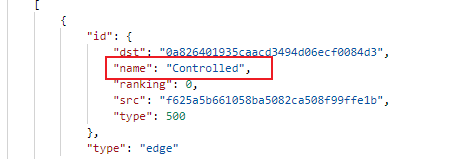
- 或者说如何返回edge 的所有属性,因为如果两种edge 的schema 不同,不能指定两种edge 对应的returnCols 的话 会有问题,只能分开一种边一个语句?
1 个赞
wey
7
现有实现不行,你这个是宝贵的真实场景需求,列一下到这个 issue 里?
我就这这个 pr 看看能不能一起撸出来
wey
8
@nicole 感觉这个 ngql reader 场景支持多类型边比较自然(相比于全图扫的场景),可不可以考虑允许 NebulaOptions.label 如果带逗号,分割成多个边,当它是多个的时候,returnCols 是 jsonString 这样向后兼容的扩充 returnCols可以是二维 list?如果 OK 的话,我试着实现一下
1 个赞
Reid00
9
这个要实现吗? 我看pr 里面只加了asPath 的解析。ps: 我理解path 应该是包含了vertex 和 edge 的属性的吧?
system
关闭
12
此话题已在最后回复的 7 天后被自动关闭。不再允许新回复。