用docker部署的集群形式,版本是3.1还是3.4记不清楚了,反正是3.1以上
模糊查询节点,如果数据量大的话怎么办,已经创建索引并重构了,现在是10多万数据,模糊查询直接超时了

在 v3.5 和 v3.6 对全文索引(模糊搜索依赖全文索引)进行了重构,如果你方便的话,看看升级到 v3.6.0 是不是这个问题会解决。参考升级文档:升级版本 - NebulaGraph Database 手册
明白了,那现在低版本的大数据量模糊检索有什么好的解决方案吗?
o.o 你这个数据量倒不是很大,主要是我清楚是不是之前的全文索引有什么隐藏的问题,所以我建议你先升级看看,升级如果能解决问题的话,估计是在新版本中被修复了。
profile给下看看
您好,请问一下,我在用spring boot集成图库的时候,怎样保证session被重复使用呢,因为现在用的一个统一处理类,每次查询后session数都会增加,并且释放不掉。

您好,profile具体指的是哪个,是linux下的etc/profile吗
如果你的 query 是 MATCH xxx RETURN YYY
现在提供一下
PROFILE MATCH xxx RETURN YYY 的结果。如果结果失败,可以提供
EXPLAIN MATCH xxx RETURN YYY 的结果
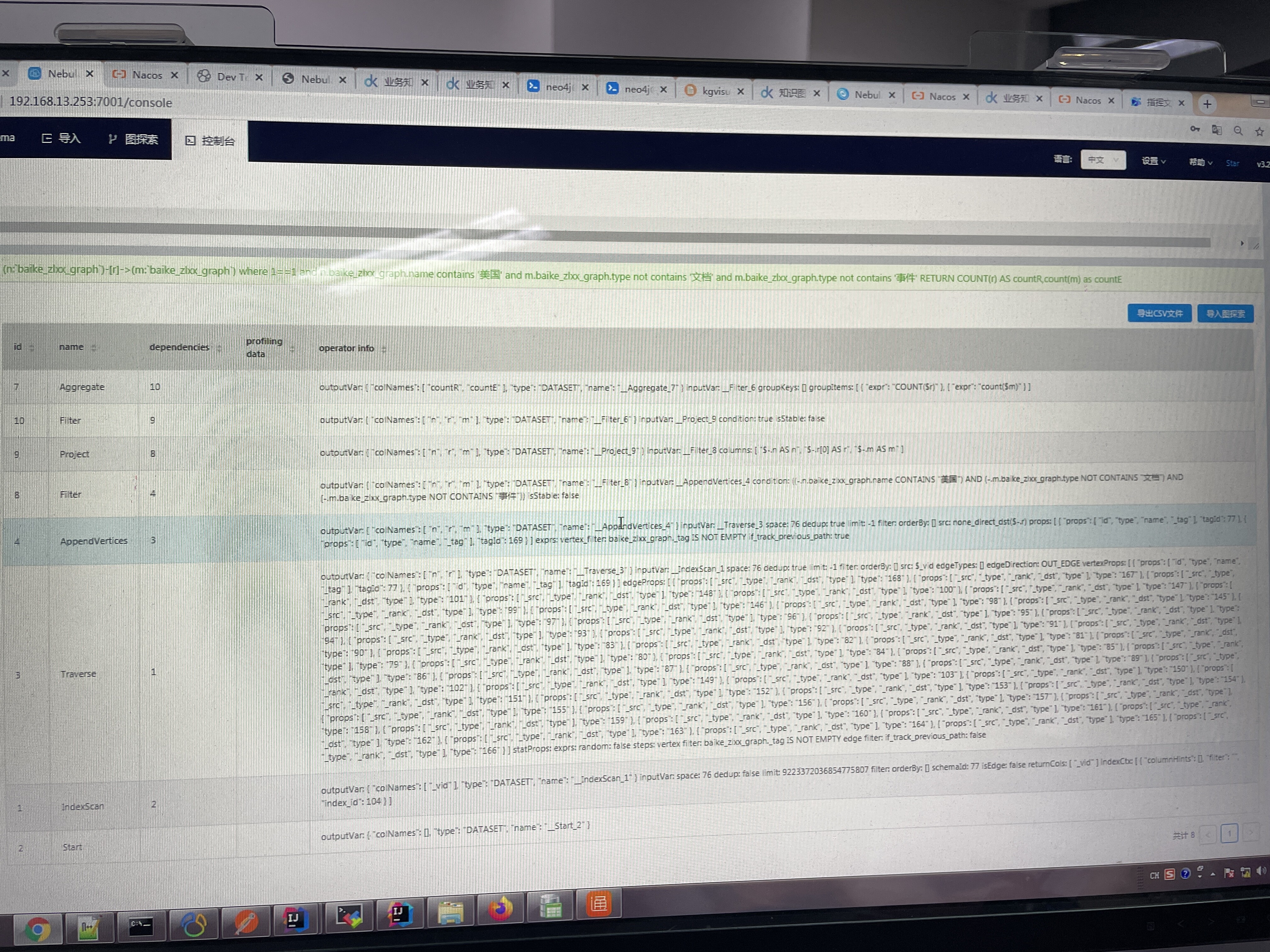
忘了回复您了,执行日志是这样的,您看一下
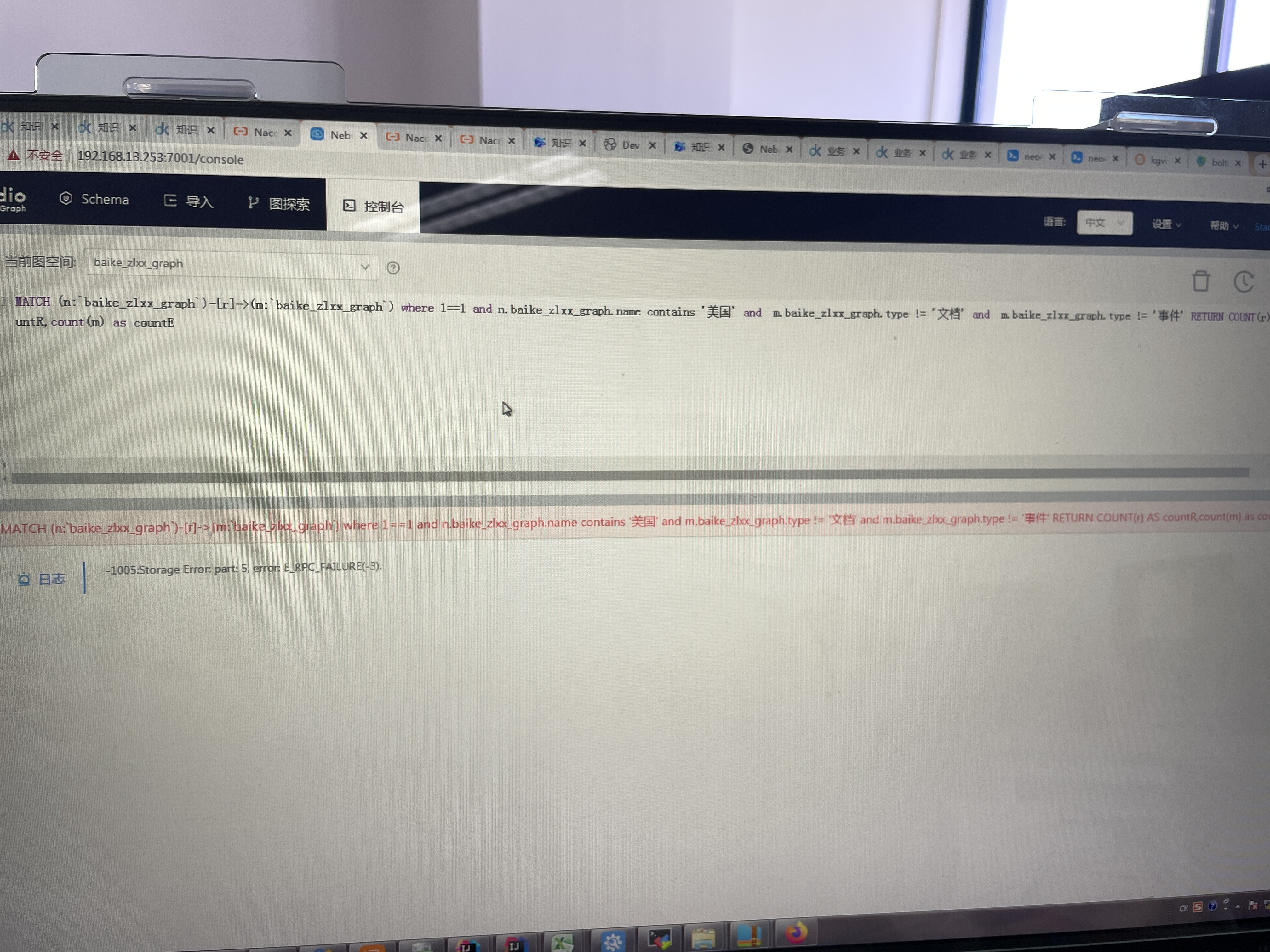
AND n.xxx.name contains "美国"
这个表达不 scale,它需要把 xxx 的数据全扫描。
推荐的做法是预处理你的数据,识别 country,把 country 作为 xxx 的 prop。
然后,这个查询是一跳的,推荐用一边的条件建立索引, LOOKUP ON 从一侧查,然后再管道 GO FROM
此话题已在最后回复的 30 天后被自动关闭。不再允许新回复。