前言
在之前的一篇文章中,我介绍了利用 Spark GraphX 进行模式匹配来实现子图抽取的方法(可查看上一篇文章),经过一段时间的使用,发现效果不是太好,主要是由于这种方法的设计缺陷,在上一篇文章最后的总结中,我指出了这个缺点。由于每次迭代的消息都是路径集合,越往后消息会越大,导致 JOIN 的数据量很大,内存占用较高。
在实际使用的一些场景中,我发现这个问题尤为突出,需要几倍甚至数十倍于数据大小的内存去支撑任务运行,这对资源的使用来说不太能接受,毕竟资源大小是有限的,所以针对这个问题,在经过一番探索之后进行了一些优化。
模式匹配优化
针对这个问题,由于是传递边来实现路径的遍历,所以每传播一次,相当于边数据就被复制一次,那么不停传播所产生的数据量就会越来越大,再加上 Spark RDD 的不可变性,内存占用会越来越多,直至溢写磁盘,那任务的运行效率就大打折扣了。对此,我采用了如下几种方法来解决。
调整传播数据结构
既然内存增长是复制边导致的,那么不复制边是否可行,经过计算之后,我发现也是可行的,设计了新的传播结构。

同样以前文的例子来介绍。这里为了抽取出 G,A 的二度点,在传播到 C,F 的时候,已经复制了很多边的列表了,具体可查看前文。我参考了 LPA 的思想,如果这里只传播点 A,G,那么每个点的数据只会有若干个点的信息,例如 C:[G,A],F:[A]。在传播之后,按照属性点进行聚合则得到了对应的边数据,也能完成相应的要求,相比于之前的方法,内存占用就少了很多。
只传播点确实可行,但是某些模式匹配的要求比较复杂,需要保留传播的路径,并对边进行筛选,那这种方法就无法满足要求了。对此,我只好增加了一个 step 属性,每次传播时,传播主点的 ID 以及该点到当前点的 step,那么上边的 C,F 结果则为:C:[(G,2),(A,2)],F:[(A,2)],然后我就可以根据边两侧的点来判断传播的路径了,比如 D:[(A,1)],那么对于 E4 来说,起始点是 1,终止点是 2,就说明 A 是在第二次传播时经过 E4 边。如果两边相同 ID 的差值不为 1,那么该主点则不在该路径上传播。
以上方法相较于传播边列表的方法,会大大降低内存的占用,但是需要增加大量的传播后计算逻辑,整体上勉强解决内存太大的问题。
其他的一些手段则需要根据实际需求来,比如环路的模式,可先进行多次剪枝操作,去除出/入度为 0 的点。此外,并不是所有模式一定要使用 Pregel,简单的场景可以使用 AggregateMessages 可能会更有效率。也可以使用 GraphFrame 进行预计算,然后再进行逻辑判断划分子图。
使用 Angel 框架
使用上边的方法,虽然减少了计算的内存占用,但是由于 RDD 的不可变性,在某些需求下进行大量迭代时仍然不能有太好的效果,所以在调研了许多框架之后,选择了 Angel 框架中的 Spark-on-Angel 来进行实现。该框架实现了一套自己的存储体系,实现了存算分离,从根本上解决了 RDD 不可变的问题,并且与 Spark 技术栈无缝集成,这样也相对容易集成到之前项目中。
Angel 框架的原理不在这里详细描述了,可以自行查看,下边只讲一下 Spark-on-Angel 最主要的特点,以及是如何使用的。
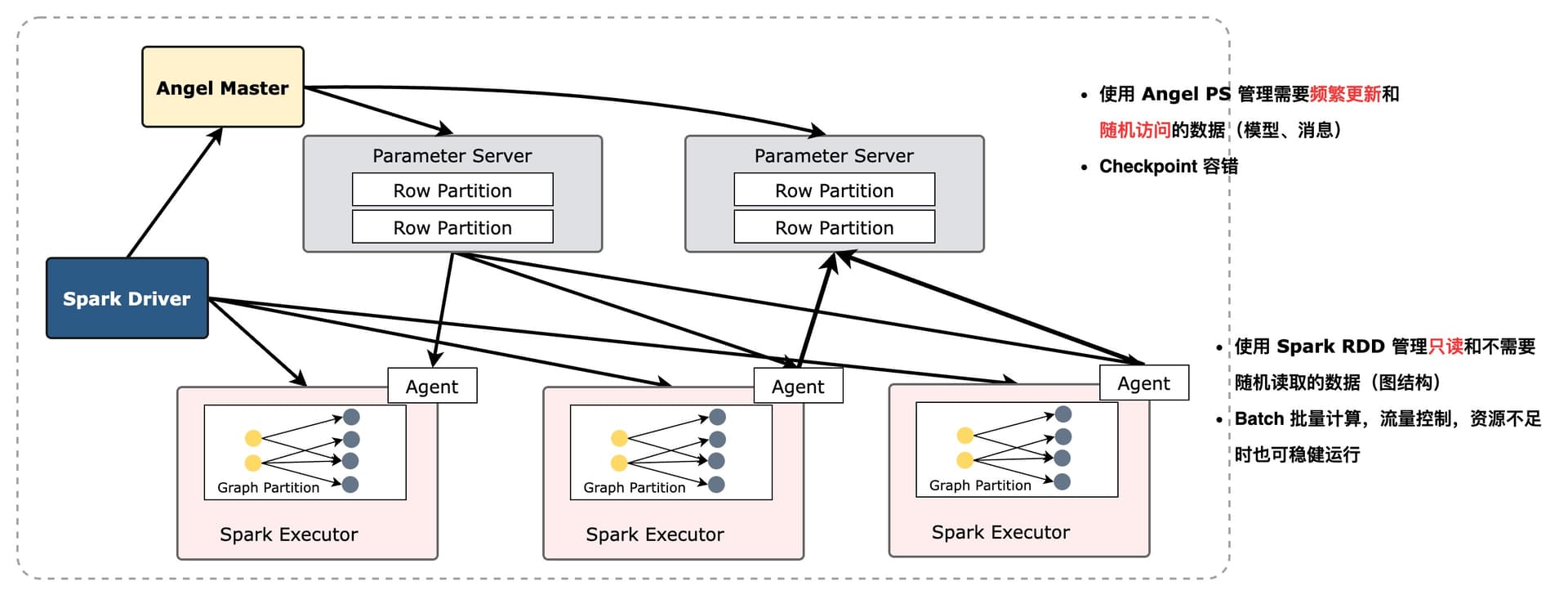
Spark on Angel 是一个基于 Paramter Service 结构的高性能图计算引擎。在 Spark 的基础上使用 Angel。Spark 负责分布式计算,Angel 负责存储图模型,主要做内容的随机读取和访问。
Angel 主要通过使用 PS 管理频繁可变的数据结构,以代替 Spark 中不可变的 RDD,以此来减少内存的使用,同时在数据结构的设计上也采用矩阵和向量的方式,通过预置的计算函数批量完成数据的更新计算。这样在 Spark 部分就只需要完成对数据的处理,实现好计算逻辑,理论上 Spark 只需要占用一份数据的内存即可。
在实际的使用中,针对上边的模式匹配思路,可以将优化后的数据结构存储在 PS 中,这样就极大地减少了诸如Pregel迭代中不断缓存的 RDD 了,内存占用减少的同时,也加快了计算的速度。尤其在一些传统的算法中效果非常明显。
在 3 节点集群(单台 16C 48G yarn、内存 100G),数据量:点 2,800w、边 1.2 亿的情况下,测试如下:
| Spark GraphX | Spark-on-Angel | |
|---|---|---|
| PageRank | 12.5 min | 12 min |
| LPA | 2 h 54 min | 13 min |
| Louvain | 内存不足 | 27 min |
通过对比发现计算越复杂,数据量越大的,采用 Angel 的效果是巨大的。
值得注意的是,在实际使用中,设计 PS 的 model 结构较为重要,如果这里的数据结构设计的占用过多,同样会引起内存问题的,查看源码中的算法,对于传统图算法基本上都设计了两个矩阵,这样总内存使用也大致在数据量的 2 倍。
总结
目前在图的 OLAP 领域中,确实还没有形成主流的方案,所以最兼容的还是要数 Spark,所以针对计算逻辑只能尽力的去优化,无法有质的突破。在 Spark 的基础上,拓展使用了 Angel 框架,解决了 Spark 的问题,确实有比较不错的效果。
但是 Angel 框架也有很多问题:
-
开源项目已经很久没有更新了,文档也有点落后,用户极少。
-
二次开发上手有一定的难度,需要理解相关概念。
-
由于 Angel 是另起一个 yarn 任务,所以在 debug 上有点麻烦。
由于 Spark 技术栈与大数据集成较为紧密,所以在技术栈的选择上也是有所限制,其他的框架例如 Plato 采用 C++,虽然效率高但是没有开发资源,GraphScope 也是 Python 技术栈,与云原生结合较为紧密。所以多方调研之后也算是选择项目当下最合适的解决方案。最后希望本文可以给大家带来一些思路,能够帮到大家。
本文正在参加 NebulaGraph 技术社区年度征文活动,征文详情:https://discuss.nebula-graph.com.cn/t/topic/13970
如果你觉得本文对你有所启发,记得给我点个
,谢谢你的鼓