Nebula 里面的二级索引都是基于 kv 形式实现的,对索引而言,最重要的就是需要保证有序,然而 RocksDB 官方 wiki 一直对于使用 Iterator 的参数语焉不详。我在之前的博客中大概说明了相关参数的作用,但没有详细结合代码解释其原理,这次就重新整理一下。
大概会分成几篇介绍:
- 第一篇介绍用户获取迭代器的过程
- 第二篇介绍
MergingIterator如何通过堆来组织多个层次的子迭代器 - 最后一篇介绍 SST 文件的迭代器
Iterator 使用方式
Range seek
RocksDB 默认的 NewIterator 默认只提供了范围查询,使用的方式也很简单:
- 调用
Seek会定位到大于等于 target 的位置 - 调用
Next移动迭代器 - 每次使用迭代器之前,都通过
Valid判断是否指向有效数据。若有效,则可以通过key和value获取相应数据
ReadOptions read_options;
Iterator* iter = db->NewIterator(read_options);
for (iter->Seek("foobar"); iter->Valid(); iter->Next()) {
cout << iter->key() << endl;
cout << iter->value() << endl;
}
这个接口只提供了范围查询,因此在默认参数下,iter 会定位到第一个大于等于 foobar 的 kv,并可以一直迭代完之后的所有数据。
Prefix seek
由于默认接口只提供范围查询,假如想要只查询前缀为 foobar 的所有数据,是需要用户在迭代过程中自己判断前缀是否匹配的。而前缀查询是一个非常通用的场景,RocksDB 后来就提供了 prefix_extractor 这个 column family 级别的参数。配置之后,RocksDB 就会处于 ”prefix seek” 模式,官方示例如下:
Options options;
// <---- Enable some features supporting prefix extraction
options.prefix_extractor.reset(NewFixedPrefixTransform(3));
DB* db;
Status s = DB::Open(options, "/tmp/rocksdb", &db);
Iterator* iter = db->NewIterator(ReadOptions());
iter->Seek("foobar"); // Seek inside prefix "foo"
iter->Next(); // Find next key-value pair inside prefix "foo"
这里会涉及若干参数,我们分情况讨论。假设有以下 key,我们按字典序先排序好:
foobar-1
foobar-2
foobar-3
football
...
future
- 当指定了
prefix_extractor,并且使用默认ReadOptions时,其本质上还是个范围查询,它不能保证只扫描前缀为foobar的数据。并且不能保证迭代器的所有数据全局有序,只能保证前缀为foobar的这些数据全局有序。即对于前缀为foobar的数据一定能保证有序输出,但当遍历完这些数据之后,调用iter->Next()之后,可能会出现以下情况之一:
iter->Valid()为 falseiter->Valid()为 true,指向football或者future,或者任意大于foobar-3的 keyiter->Valid()为 true,指向一个大于foobar-3,且不存在的 key(甚至可能是一个之前被 delete 掉的 key)
- 当指定了
prefix_extractor,并且指定ReadOptions.prefix_same_as_start=true,此时就是真正的前缀查询。即对于前缀为foobar的数据一定能保证有序输出,并且当遍历完这些数据之后,iter->Valid()一定为 false。 - 当指定了
prefix_extractor,并且指定ReadOptions.total_order_seek=true,此时行为和默认的范围查询一致。即依次输出如下数据:
foobar-1
foobar-2
foobar-3
football
...
future
这其中,最危险的就是第一种情况。首先它使用的是默认参数 ReadOptions,并且它的行为十分诡异。除此之外,在使用 prefix_extractor 时还有非常多的坑需要注意,具体可以参照之前的博客rocksdb prefix seek - Braid (critical27.github.io),这里就不做过多展开。接下来我们会结合代码看看到底 Iterator 是如何使用的,使用的源码版本是 7.8.3。
Iterator Internal
NewIterator
由于 LSM 的特性,每次对迭代器进行迭代时,势必要汇总 memtable + 多个 sst level 的数据,这样才能保证最终输出的数据全局有序。我们可以看下 RocksDB 是如何组织这个迭代器的,当调用 NewIterator 时,会经过这几个函数获取到一个迭代器。
DBImpl::NewIterator
-> DBImpl::NewIteratorImpl
-> DBImpl::NewInternalIterator
我们最终拿到的迭代器的大致形式如下所示:
// Try to generate a DB iterator tree in continuous memory area to be
// cache friendly. Here is an example of result:
// +-------------------------------+
// | |
// | ArenaWrappedDBIter |
// | + |
// | +---> Inner Iterator ------------+
// | | | |
// | | +-- -- -- -- -- -- -- --+ |
// | +--- | Arena | |
// | | | |
// | Allocated Memory: | |
// | | +-------------------+ |
// | | | DBIter | <---+
// | | + |
// | | | +-> iter_ ------------+
// | | | | |
// | | +-------------------+ |
// | | | MergingIterator | <---+
// | | + |
// | | | +->child iter1 ------------+
// | | | | | |
// | | +->child iter2 ----------+ |
// | | | | | | |
// | | | +->child iter3 --------+ | |
// | | | | | |
// | | +-------------------+ | | |
// | | | Iterator1 | <--------+
// | | +-------------------+ | |
// | | | Iterator2 | <------+
// | | +-------------------+ |
// | | | Iterator3 | <----+
// | | +-------------------+
// | | |
// +-------+-----------------------+
最外层是一个 ArenaWrappedDBIter,里面有一个 DBIter 和 Arena。DBIter 内部可能会由一个 memtable 的迭代器加上每个 sst level 的迭代器组成的,所有这些迭代器组成一个 MergingIterator。MergingIterator 中通过一个最小堆维护各个子迭代器的指针,每次迭代就是不断输出堆顶的子迭代器所指向的数据,然后重新调整最小堆。
另外 DBIter 会处于 Arena 分配的连续内存中,之所以这么做的一个核心原因就在于在维护 MergingIterator 的最小堆时,需要不断调整最小堆,而把各个子迭代器的指针放在一块连续内存中,会对 cache 更加友好。
相关类的关系图如下:
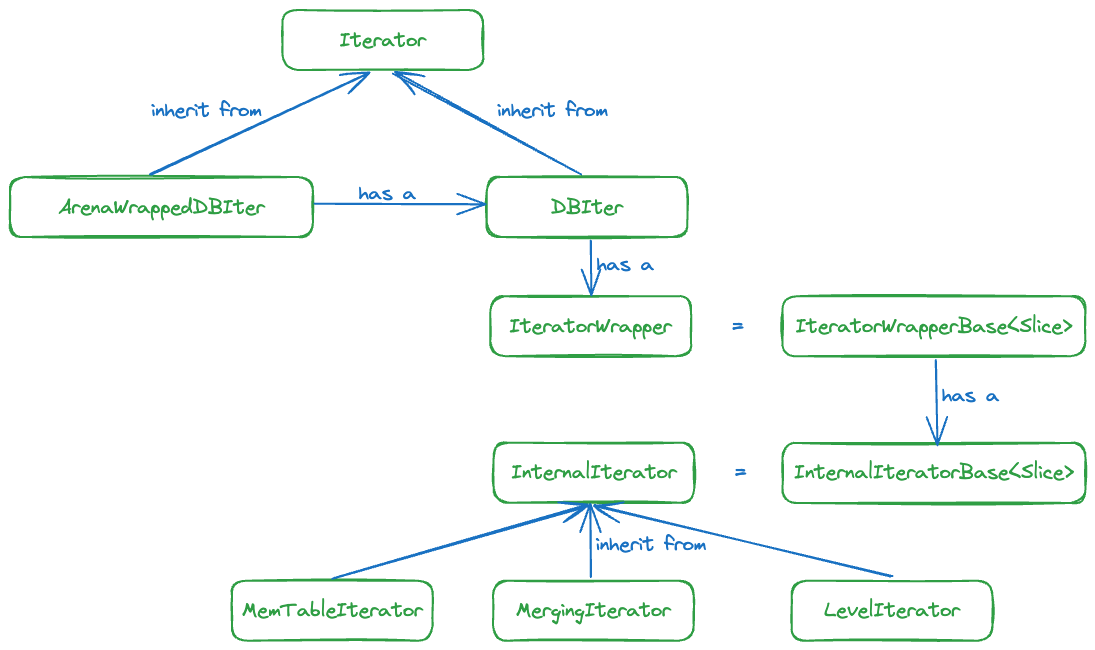
这里有一个地方对理解后面的代码非常重要,DBIter 和 MergingIterator 的区别是什么?
首先 RocksDB 的 memtable 和 sst 文件存储的 key 实际是 InternalKey,InternalKey 由 userkey + seq + type 组成,userkey 是用户写入的 key,seq 用来支持快照读,而 type 说明这个数据的操作是 Put、Delete 还是 Merge 等等。
DBIter 的遍历粒度是 userkey,只要 userkey 相同,那么 seq 越大就代表记录越新。根据 LSM 数据组织形式,只要在较上层找到某个 userkey 的数据之后,下面的所有层次即便存在相同 userkey 的数据,都可以忽略(这些记录的 seq 更小)。因此每次 DBIter 的迭代都会将迭代器指向下一个不同 userkey 的数据。而 MergingIterator 的遍历粒度是 InternalKey,只要 InternalKey 中的任意一个字段不同,都认为是不同的数据。
DBIter
基于上面的分析,我们看一下 DBIter 的关键实现。首先是 Seek:
void DBIter::Seek(const Slice& target) {
// ...
// Seek the inner iterator based on the target key.
{
PERF_TIMER_GUARD(seek_internal_seek_time);
SetSavedKeyToSeekTarget(target);
iter_.Seek(saved_key_.GetInternalKey());
RecordTick(statistics_, NUMBER_DB_SEEK);
}
if (!iter_.Valid()) {
valid_ = false;
return;
}
direction_ = kForward;
// Now the inner iterator is placed to the target position. From there,
// we need to find out the next key that is visible to the user.
ClearSavedValue();
if (prefix_same_as_start_) {
// The case where the iterator needs to be invalidated if it has exhausted
// keys within the same prefix of the seek key.
assert(prefix_extractor_ != nullptr);
Slice target_prefix = prefix_extractor_->Transform(target);
FindNextUserEntry(false /* not skipping saved_key */,
&target_prefix /* prefix */);
if (valid_) {
// Remember the prefix of the seek key for the future Next() call to
// check.
prefix_.SetUserKey(target_prefix);
}
} else {
FindNextUserEntry(false /* not skipping saved_key */, nullptr);
}
if (!valid_) {
return;
}
// ...
}
大致逻辑如下:
- 调用
MergingIterator::Seek,如果迭代器无效就直接返回。注意MergingIterator::Seek的参数是InternalKey,因此搜索到的记录可能因为几种情况是需要跳过的: - 这条记录可能是一个 Delete 记录
- 这条记录可能不满足 seq 或者 timestamp 的范围
- 在 prefix seek 模式下,这条记录的前缀可能和 target 的前缀不匹配
- 此时需要调用
FindNextUserEntry,确保迭代器指向一个存在的记录。注意这里如果启用了 prefix seek 模式,会把对应的前缀也传入,保证指向记录的前缀和 targe 的前缀相同。
FindNextUserEntryInternal 会在几个情况下直接跳过当前数据(Seek 和 FindNextUserEntryInternal 会把当前记录保存在 saved_key_ 中),继续检查下一个数据
- 超过了用户传入的
iterate_upper_bound - prefix seek 模式下前缀不匹配
- 当前数据是 Delete 记录
bool DBIter::FindNextUserEntryInternal(bool skipping_saved_key,
const Slice* prefix) {
// Loop until we hit an acceptable entry to yield
assert(iter_.Valid());
assert(status_.ok());
assert(direction_ == kForward);
current_entry_is_merged_ = false;
// How many times in a row we have skipped an entry with user key less than
// or equal to saved_key_. We could skip these entries either because
// sequence numbers were too high or because skipping_saved_key = true.
// What saved_key_ contains throughout this method:
// - if skipping_saved_key : saved_key_ contains the key that we need
// to skip, and we haven't seen any keys greater
// than that,
// - if num_skipped > 0 : saved_key_ contains the key that we have skipped
// num_skipped times, and we haven't seen any keys
// greater than that,
// - none of the above : saved_key_ can contain anything, it doesn't
// matter.
uint64_t num_skipped = 0;
// For write unprepared, the target sequence number in reseek could be larger
// than the snapshot, and thus needs to be skipped again. This could result in
// an infinite loop of reseeks. To avoid that, we limit the number of reseeks
// to one.
bool reseek_done = false;
do {
// Will update is_key_seqnum_zero_ as soon as we parsed the current key
// but we need to save the previous value to be used in the loop.
bool is_prev_key_seqnum_zero = is_key_seqnum_zero_;
if (!ParseKey(&ikey_)) {
is_key_seqnum_zero_ = false;
return false;
}
Slice user_key_without_ts =
StripTimestampFromUserKey(ikey_.user_key, timestamp_size_);
is_key_seqnum_zero_ = (ikey_.sequence == 0);
assert(iterate_upper_bound_ == nullptr ||
iter_.UpperBoundCheckResult() != IterBoundCheck::kInbound ||
user_comparator_.CompareWithoutTimestamp(
user_key_without_ts, /*a_has_ts=*/false, *iterate_upper_bound_,
/*b_has_ts=*/false) < 0);
if (iterate_upper_bound_ != nullptr &&
iter_.UpperBoundCheckResult() != IterBoundCheck::kInbound &&
user_comparator_.CompareWithoutTimestamp(
user_key_without_ts, /*a_has_ts=*/false, *iterate_upper_bound_,
/*b_has_ts=*/false) >= 0) {
// 已经超过了用户传入的iterate_upper_bound
break;
}
assert(prefix == nullptr || prefix_extractor_ != nullptr);
if (prefix != nullptr &&
prefix_extractor_->Transform(user_key_without_ts).compare(*prefix) !=
0) {
// prefix seek模式 且前缀不匹配
assert(prefix_same_as_start_);
break;
}
if (TooManyInternalKeysSkipped()) {
return false;
}
assert(ikey_.user_key.size() >= timestamp_size_);
Slice ts = timestamp_size_ > 0 ? ExtractTimestampFromUserKey(
ikey_.user_key, timestamp_size_)
: Slice();
bool more_recent = false;
// 判断能否读取这个InternalKey的数据
// 依次检查数据的sequence是否小于生成DBIter时候的seq
// 以及数据的timestamp是否满足用户传入的timestamp范围 (ReadOptions里的参数)
if (IsVisible(ikey_.sequence, ts, &more_recent)) {
// If the previous entry is of seqnum 0, the current entry will not
// possibly be skipped. This condition can potentially be relaxed to
// prev_key.seq <= ikey_.sequence. We are cautious because it will be more
// prone to bugs causing the same user key with the same sequence number.
// Note that with current timestamp implementation, the same user key can
// have different timestamps and zero sequence number on the bottommost
// level. This may change in the future.
if ((!is_prev_key_seqnum_zero || timestamp_size_ > 0) &&
skipping_saved_key &&
CompareKeyForSkip(ikey_.user_key, saved_key_.GetUserKey()) <= 0) {
num_skipped++; // skip this entry
PERF_COUNTER_ADD(internal_key_skipped_count, 1);
} else {
// 找到一个InternalKey记录 检查对应的类型
assert(!skipping_saved_key ||
CompareKeyForSkip(ikey_.user_key, saved_key_.GetUserKey()) > 0);
if (!iter_.PrepareValue()) {
assert(!iter_.status().ok());
valid_ = false;
return false;
}
num_skipped = 0;
reseek_done = false;
switch (ikey_.type) {
case kTypeDeletion:
case kTypeDeletionWithTimestamp:
case kTypeSingleDeletion:
// Arrange to skip all upcoming entries for this key since
// they are hidden by this deletion.
if (timestamp_lb_) {
saved_key_.SetInternalKey(ikey_);
valid_ = true;
return true;
} else {
saved_key_.SetUserKey(
ikey_.user_key, !pin_thru_lifetime_ ||
!iter_.iter()->IsKeyPinned() /* copy */);
skipping_saved_key = true;
PERF_COUNTER_ADD(internal_delete_skipped_count, 1);
}
break;
case kTypeValue:
case kTypeBlobIndex:
case kTypeWideColumnEntity:
if (timestamp_lb_) {
saved_key_.SetInternalKey(ikey_);
} else {
saved_key_.SetUserKey(
ikey_.user_key, !pin_thru_lifetime_ ||
!iter_.iter()->IsKeyPinned() /* copy */);
}
if (ikey_.type == kTypeBlobIndex) {
if (!SetBlobValueIfNeeded(ikey_.user_key, iter_.value())) {
return false;
}
SetValueAndColumnsFromPlain(expose_blob_index_ ? iter_.value()
: blob_value_);
} else if (ikey_.type == kTypeWideColumnEntity) {
if (!SetValueAndColumnsFromEntity(iter_.value())) {
return false;
}
} else {
assert(ikey_.type == kTypeValue);
SetValueAndColumnsFromPlain(iter_.value());
}
valid_ = true;
return true;
break;
case kTypeMerge:
saved_key_.SetUserKey(
ikey_.user_key,
!pin_thru_lifetime_ || !iter_.iter()->IsKeyPinned() /* copy */);
// By now, we are sure the current ikey is going to yield a value
current_entry_is_merged_ = true;
valid_ = true;
return MergeValuesNewToOld(); // Go to a different state machine
break;
default:
valid_ = false;
status_ = Status::Corruption(
"Unknown value type: " +
std::to_string(static_cast<unsigned int>(ikey_.type)));
return false;
}
}
} else {
if (more_recent) {
PERF_COUNTER_ADD(internal_recent_skipped_count, 1);
}
// This key was inserted after our snapshot was taken or skipped by
// timestamp range. If this happens too many times in a row for the same
// user key, we want to seek to the target sequence number.
int cmp = user_comparator_.CompareWithoutTimestamp(
ikey_.user_key, saved_key_.GetUserKey());
if (cmp == 0 || (skipping_saved_key && cmp < 0)) {
num_skipped++;
} else {
saved_key_.SetUserKey(
ikey_.user_key,
!iter_.iter()->IsKeyPinned() || !pin_thru_lifetime_ /* copy */);
skipping_saved_key = false;
num_skipped = 0;
reseek_done = false;
}
}
// If we have sequentially iterated via numerous equal keys, then it's
// better to seek so that we can avoid too many key comparisons.
//
// To avoid infinite loops, do not reseek if we have already attempted to
// reseek previously.
if (num_skipped > max_skip_ && !reseek_done) {
// 当连续若干次顺序查找的userkey都是同一个 会尝试换一个userkey
// ...
iter_.Seek(last_key);
RecordTick(statistics_, NUMBER_OF_RESEEKS_IN_ITERATION);
} else {
iter_.Next();
}
} while (iter_.Valid());
valid_ = false;
return iter_.status().ok();
}
当从 FindNextUserEntryInternal 函数退出的时候,如果 valid_ 为true,就指向一个合法数据,否则迭代器失效。理解了 Seek 的工作原理,Next 就非常简单:
- 调用
MergingIterator::Next,此时指向的记录仍然可能是无效。 - 同样调用
FindNextUserEntry,将迭代器移动到一个下一个位置。FindNextUserEntry此时传入的第一个参数为 true,代表要跳过与当前记录saved_key_中userkey相同的数据(因为在调用Next之前,一定已经调用过Seek,因此需要跳过userkey相同的记录)
void DBIter::Next() {
assert(valid_);
assert(status_.ok());
// ...
bool ok = true;
if (direction_ == kReverse) {
is_key_seqnum_zero_ = false;
if (!ReverseToForward()) {
ok = false;
}
} else if (!current_entry_is_merged_) {
// If the current value is not a merge, the iter position is the
// current key, which is already returned. We can safely issue a
// Next() without checking the current key.
// If the current key is a merge, very likely iter already points
// to the next internal position.
assert(iter_.Valid());
iter_.Next();
PERF_COUNTER_ADD(internal_key_skipped_count, 1);
}
local_stats_.next_count_++;
if (ok && iter_.Valid()) {
if (prefix_same_as_start_) {
assert(prefix_extractor_ != nullptr);
const Slice prefix = prefix_.GetUserKey();
FindNextUserEntry(true /* skipping the current user key */, &prefix);
} else {
FindNextUserEntry(true /* skipping the current user key */, nullptr);
}
} else {
is_key_seqnum_zero_ = false;
valid_ = false;
}
if (statistics_ != nullptr && valid_) {
local_stats_.next_found_count_++;
local_stats_.bytes_read_ += (key().size() + value().size());
}
}
Build MergingIterator
既然 DBIter 面向 userkey,MergingIterator 就是面向 InternalKey 的迭代器了,其功能主要包含两方面:
- 添加多个子迭代器,并组成一个最小堆
- 在迭代过程中维护这个最小堆(下一篇再介绍)
我们看一下 MergingIterator 是如何被构造出来的,分成几部分,mutable memtable 的迭代器,immutable memtable 的迭代器,以及多个 sst level 的迭代器,然后调用 MergeIteratorBuilder::AddIterator 添加到 MergeIteratorBuilder 中。
InternalIterator* DBImpl::NewInternalIterator(
const ReadOptions& read_options, ColumnFamilyData* cfd,
SuperVersion* super_version, Arena* arena, SequenceNumber sequence,
bool allow_unprepared_value, ArenaWrappedDBIter* db_iter) {
InternalIterator* internal_iter;
assert(arena != nullptr);
// Need to create internal iterator from the arena.
MergeIteratorBuilder merge_iter_builder(
&cfd->internal_comparator(), arena,
!read_options.total_order_seek &&
super_version->mutable_cf_options.prefix_extractor != nullptr,
read_options.iterate_upper_bound);
// Collect iterator for mutable memtable
auto mem_iter = super_version->mem->NewIterator(read_options, arena);
Status s;
if (!read_options.ignore_range_deletions) {
// 不忽略range delete的tombstone
// 会往merge_iter_builder中增加point iterator和tombstone iterator
TruncatedRangeDelIterator* mem_tombstone_iter = nullptr;
auto range_del_iter = super_version->mem->NewRangeTombstoneIterator(
read_options, sequence, false /* immutable_memtable */);
if (range_del_iter == nullptr || range_del_iter->empty()) {
delete range_del_iter;
} else {
mem_tombstone_iter = new TruncatedRangeDelIterator(
std::unique_ptr<FragmentedRangeTombstoneIterator>(range_del_iter),
&cfd->ioptions()->internal_comparator, nullptr /* smallest */,
nullptr /* largest */);
}
merge_iter_builder.AddPointAndTombstoneIterator(mem_iter,
mem_tombstone_iter);
} else {
// 增加memtable的迭代器
merge_iter_builder.AddIterator(mem_iter);
}
// Collect all needed child iterators for immutable memtables
if (s.ok()) {
super_version->imm->AddIterators(read_options, &merge_iter_builder,
!read_options.ignore_range_deletions);
}
TEST_SYNC_POINT_CALLBACK("DBImpl::NewInternalIterator:StatusCallback", &s);
if (s.ok()) {
// Collect iterators for files in L0 - Ln
if (read_options.read_tier != kMemtableTier) {
// 增加L0 - Ln的迭代器
super_version->current->AddIterators(read_options, file_options_,
&merge_iter_builder,
allow_unprepared_value);
}
internal_iter = merge_iter_builder.Finish(
read_options.ignore_range_deletions ? nullptr : db_iter);
// ...
return internal_iter;
} else {
CleanupSuperVersion(super_version);
}
return NewErrorInternalIterator<Slice>(s, arena);
}
对于 memtable 就是创建一个 MemTableIterator,而 sst 文件会分布在多层,需要把每一层的迭代器都添加到 MergeIteratorBuilder 中。相关代码如下,可以看到 L0 由于有多个文件且无序,因此要添加每个 L0 sst 的迭代器,而 L1 及以上只有一个迭代器。
void Version::AddIterators(const ReadOptions& read_options,
const FileOptions& soptions,
MergeIteratorBuilder* merge_iter_builder,
bool allow_unprepared_value) {
assert(storage_info_.finalized_);
for (int level = 0; level < storage_info_.num_non_empty_levels(); level++) {
AddIteratorsForLevel(read_options, soptions, merge_iter_builder, level,
allow_unprepared_value);
}
}
void Version::AddIteratorsForLevel(const ReadOptions& read_options,
const FileOptions& soptions,
MergeIteratorBuilder* merge_iter_builder,
int level, bool allow_unprepared_value) {
// ...
auto* arena = merge_iter_builder->GetArena();
if (level == 0) {
// Merge all level zero files together since they may overlap
TruncatedRangeDelIterator* tombstone_iter = nullptr;
for (size_t i = 0; i < storage_info_.LevelFilesBrief(0).num_files; i++) {
const auto& file = storage_info_.LevelFilesBrief(0).files[i];
auto table_iter = cfd_->table_cache()->NewIterator(
read_options, soptions, cfd_->internal_comparator(),
*file.file_metadata, /*range_del_agg=*/nullptr,
mutable_cf_options_.prefix_extractor, nullptr,
cfd_->internal_stats()->GetFileReadHist(0),
TableReaderCaller::kUserIterator, arena,
/*skip_filters=*/false, /*level=*/0, max_file_size_for_l0_meta_pin_,
/*smallest_compaction_key=*/nullptr,
/*largest_compaction_key=*/nullptr, allow_unprepared_value,
&tombstone_iter);
if (read_options.ignore_range_deletions) {
merge_iter_builder->AddIterator(table_iter);
} else {
merge_iter_builder->AddPointAndTombstoneIterator(table_iter,
tombstone_iter);
}
}
// ...
} else if (storage_info_.LevelFilesBrief(level).num_files > 0) {
// For levels > 0, we can use a concatenating iterator that sequentially
// walks through the non-overlapping files in the level, opening them
// lazily.
auto* mem = arena->AllocateAligned(sizeof(LevelIterator));
TruncatedRangeDelIterator*** tombstone_iter_ptr = nullptr;
auto level_iter = new (mem) LevelIterator(
cfd_->table_cache(), read_options, soptions,
cfd_->internal_comparator(), &storage_info_.LevelFilesBrief(level),
mutable_cf_options_.prefix_extractor, should_sample_file_read(),
cfd_->internal_stats()->GetFileReadHist(level),
TableReaderCaller::kUserIterator, IsFilterSkipped(level), level,
/*range_del_agg=*/nullptr, /*compaction_boundaries=*/nullptr,
allow_unprepared_value, &tombstone_iter_ptr);
if (read_options.ignore_range_deletions) {
merge_iter_builder->AddIterator(level_iter);
} else {
merge_iter_builder->AddPointAndTombstoneIterator(
level_iter, nullptr /* tombstone_iter */, tombstone_iter_ptr);
}
}
}
默认参数下,ignore_range_deletions 为 false,因此实际是调用 MergeIteratorBuilder::AddPointAndTombstoneIterator,MergeIteratorBuilder 中有个成员变量 use_merging_iter,初始值为 false。只调用过一次 AddIterator 或者 AddPointAndTombstoneIterator 时,就直接使用这个子迭代器即可,而超过两次就会真正通过最小堆类维护多个子迭代器。
有关
MergeIteratorBuilder的具体逻辑会在下一篇介绍
void MergeIteratorBuilder::AddIterator(InternalIterator* iter) {
if (!use_merging_iter && first_iter != nullptr) {
merge_iter->AddIterator(first_iter);
use_merging_iter = true;
first_iter = nullptr;
}
if (use_merging_iter) {
merge_iter->AddIterator(iter);
} else {
first_iter = iter;
}
}
void MergeIteratorBuilder::AddPointAndTombstoneIterator(
InternalIterator* point_iter, TruncatedRangeDelIterator* tombstone_iter,
TruncatedRangeDelIterator*** tombstone_iter_ptr) {
// tombstone_iter_ptr != nullptr means point_iter is a LevelIterator.
bool add_range_tombstone = tombstone_iter ||
!merge_iter->range_tombstone_iters_.empty() ||
tombstone_iter_ptr;
if (!use_merging_iter && (add_range_tombstone || first_iter)) {
use_merging_iter = true;
if (first_iter) {
merge_iter->AddIterator(first_iter);
first_iter = nullptr;
}
}
if (use_merging_iter) {
merge_iter->AddIterator(point_iter);
if (add_range_tombstone) {
// If there was a gap, fill in nullptr as empty range tombstone iterators.
while (merge_iter->range_tombstone_iters_.size() <
merge_iter->children_.size() - 1) {
merge_iter->AddRangeTombstoneIterator(nullptr);
}
merge_iter->AddRangeTombstoneIterator(tombstone_iter);
}
if (tombstone_iter_ptr) {
// This is needed instead of setting to &range_tombstone_iters_[i]
// directly here since the memory address of range_tombstone_iters_[i]
// might change during vector resizing.
range_del_iter_ptrs_.emplace_back(
merge_iter->range_tombstone_iters_.size() - 1, tombstone_iter_ptr);
}
} else {
first_iter = point_iter;
}
}
里面会调用 MergingIterator::AddIterator 和 MergingIterator::AddRangeTombstoneIterator
virtual void AddIterator(InternalIterator* iter) {
children_.emplace_back(children_.size(), iter);
if (pinned_iters_mgr_) {
iter->SetPinnedItersMgr(pinned_iters_mgr_);
}
// Invalidate to ensure `Seek*()` is called to construct the heaps before
// use.
current_ = nullptr;
}
void AddRangeTombstoneIterator(TruncatedRangeDelIterator* iter) {
range_tombstone_iters_.emplace_back(iter);
}
当所有迭代器都添加完之后,最终调用MergeIteratorBuilder::Finish和MergingIterator::Finish。
InternalIterator* MergeIteratorBuilder::Finish(ArenaWrappedDBIter* db_iter) {
InternalIterator* ret = nullptr;
if (!use_merging_iter) {
ret = first_iter;
first_iter = nullptr;
} else {
for (auto& p : range_del_iter_ptrs_) {
*(p.second) = &(merge_iter->range_tombstone_iters_[p.first]);
}
if (db_iter && !merge_iter->range_tombstone_iters_.empty()) {
// memtable is always the first level
db_iter->SetMemtableRangetombstoneIter(
&merge_iter->range_tombstone_iters_.front());
}
merge_iter->Finish();
ret = merge_iter;
merge_iter = nullptr;
}
return ret;
}
到这里关于 Iterator 的构造部分的主干代码我们就分析完了。
Conclusion
这一篇我们总结了以下内容:
- RocksDB 的不同类型的Iterator如何组织的
- DBIter 和 MergingIterator 的作用
我们会在下一篇分析 MergingIterator 是如何通过最小堆来维护多个子迭代器,进而保证迭代器的输出有序。