一、前言
任何软件部署在部署时,尤其是集群部署时,都需要考虑服务器资源分配,好的资源分配,可以充分使用服务器资源的同时,保证服务的性能。主要考虑的就是cpu、内存、磁盘、网络等资源。今天结合官方文档以及测试,分析一下NebulaGraph的各个组件内存使用情况。
二、各个服务组件内存分析
2.1、meta
介绍
meta服务是 NebulaGraph的元数据管理,主要功能包括:管理用户账号、管理分片、管理图空间、管理 Schema 信息、管理 TTL 信息、管理作业以及维护自身集群。
服务架构
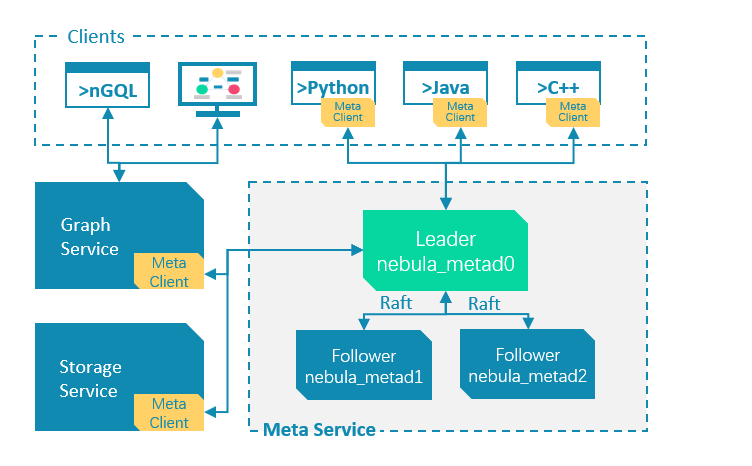
服务对象
meta服务主要是对外提供元数据查询服务 和集群状态监控接口,对内的提供元数据的同步与更新和分布式锁服务,以及集群自身Raft 协议通信。
内存使用分析
1、metad 负责管理 NebulaGraph 的元数据。内存用于缓存元数据以提高元数据查询性能。所以此部分使用的内存总量不是很大。
2、元数据相对稳定,需要长时间保存在内存当中,内存使用时间长。
3、不涉及大量的查询缓存等操作,即便在较高并发时,也不会存在内存使用爆发增长。
2.2、Graph
介绍
Graph 服务主要负责处理查询请求,包括解析查询语句、校验语句、生成执行计划以及按照执行计划执行四个大步骤。
服务架构
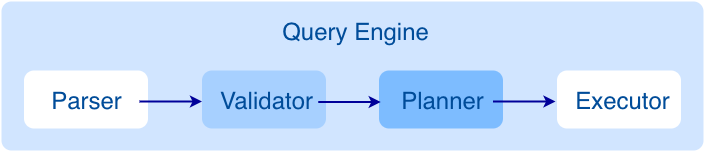
服务对象
Graph是NebulaGraph中主要对外服务的接口,负责解析和优化查询,然后生成和执行计划。各个步骤详细说明参考文档
内存使用分析
1、Graph负责解析和优化查询,不涉及大量数据操作以及缓存,不会过多占用内存,但是为了保证查询的性能很可能会缓存一些热数据,所以内存的使用量应该会和存储的数据量以及热数据量挂钩。
2、生成和执行计划,主要的内存消耗应该是在执行计划部分,执行查询时会涉及维护一些查询上下文信息,比如查询状态,查询进度等,但是有一部分的数据检索功能应该是在Storage interface层实现的,在加上生成计划的时的缓存,内存使用会比较多。容易收到高并发的影响导致内存使用大量增加。
3、由于需要缓存很多数据,在并发较高时热数据不能得到释放,同时增加新的热数据缓存,内存使用时间会很长,如果是突发性并非增加,内存使用量应当会在一定时间内下降。
2.3、Storage
介绍
负责存储和管理图数据的组件, 使用 RocksDB 作为默认的存储引擎,实现了图数据库的数据存储和检索功能。
服务架构
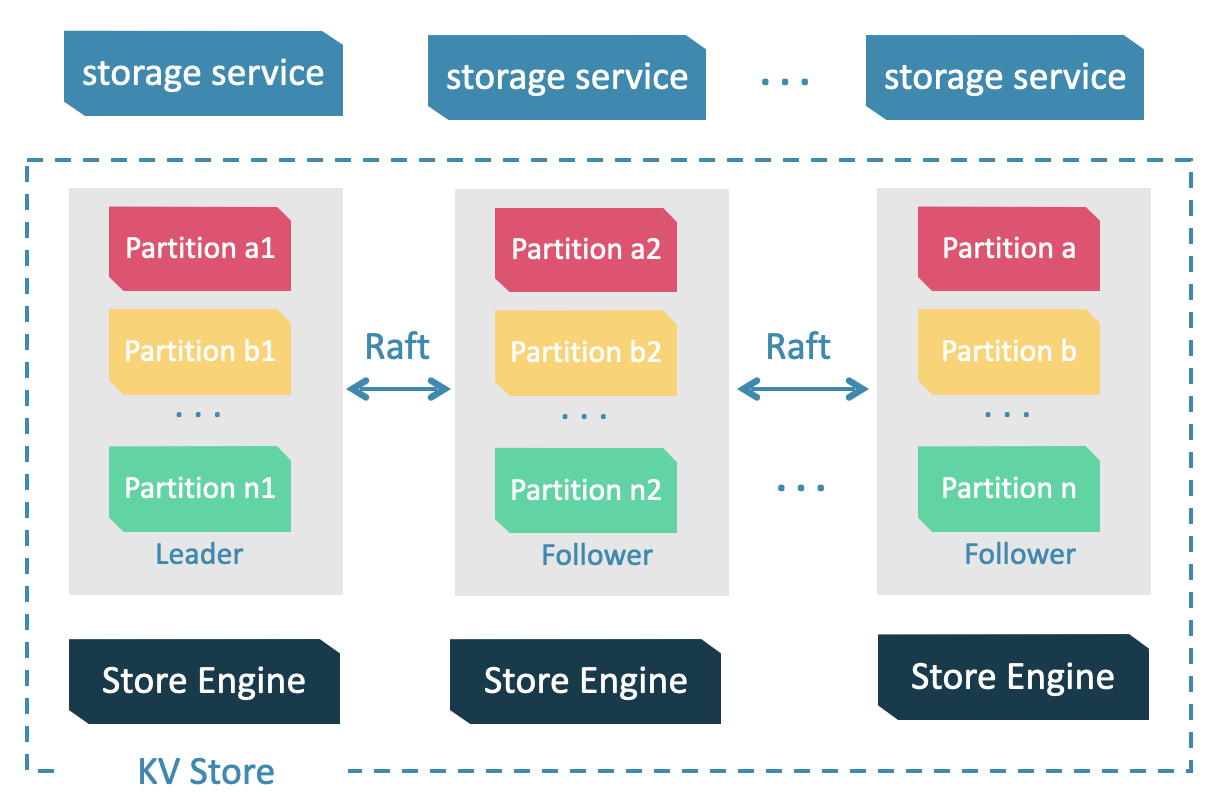
服务对象
对外提供一系列和图相关的 API,中间实现基于raft的分布式架构保证高可用,底层提供数据存储引擎,同时还有一个主要功能Compaction在Storage模块实现
内存使用分析
1、Storage interface会有大量的数据缓存以及各种对分片的kv操作进程消耗掉的内存。
2、维护集群信息消耗掉的内存,不会很多。
3、底层存储使用 RocksDB 作为默认的存储引擎会使用内存来缓存数据块、索引信息等,以提高数据的读取性能。
4、Compaction操作会读取硬盘上的数据,然后重组数据结构和索引,然后再写回硬盘,期间不仅会长时间占用硬盘IO,也会使用内存缓存,来提高执行效率。
5、Storage模块的服务内存使用应该是使用量最大,使用时间最长,同时会对硬盘IO性能要求很高。
2.4、补充
各个模块都会有一些其他的内存开销,但是占比应该不会很大,比如维护连接池,生成日志等。
三、总结和建议
很多分析都是基于文档介绍以及自己的推测(没有足够的资源部署多机集群环境),难免有不准确的地方,欢迎指出错误。
内存以及硬盘IO对Storage性能影响很大,尽量关闭系统的交换分区,使用ssd硬盘,将性能最好的服务器分配给Storage节点。meta节点占用资源较少,服务器数量不足时,可以考虑和其他服务部署在一台机器,但是尽量不要将所有meta模块部署到一台服务器。Graph服务涉及的计算会比较多,应优先分配cpu性能好,内存足够充足的服务器。
本文正在参加 NebulaGraph 技术社区年度征文活动,征文详情:https://discuss.nebula-graph.com.cn/t/topic/13970
如果你觉得本文对你有所启发,记得给我点个
,谢谢你的鼓励