全村的希望
1
nebula 版本: 3.6.0
import:4.1.0
部署方式:单机
安装方式:RPM
是否上生产环境:N
硬件信息
。磁盘 SSD
。CPU、内存信息
version: v3
address: "xxxx:9669"
user: root
password: nebula
ssl:
enable: false
certPath: "/home/xxx/cert/importer.crt"
keyPath: "/home/xxx/cert/importer.key"
caPath: "/home/xxx/cert/root.crt"
insecureSkipVerify: false
concurrencyPerAddress: 10
reconnectInitialInterval: 1s
retry: 3
retryInitialInterval: 1s
manager:
spaceName: sf10
batch: 1024
readerConcurrency: 50
importerConcurrency: 50
statsInterval: 10s
hooks:
before:
- statements:
- |
DROP SPACE IF EXISTS sf10;
CREATE SPACE IF NOT EXISTS sf10(partition_num=5, replica_factor=1, vid_type=int);
USE sf10;
CREATE TAG Person(firstName string,lastName string,gender string,birthday string,creationDate string,locationIP string,browserUsed string,language string, email string);
CREATE EDGE KNOWS(creationDate string);
wait: 10s
after:
- statements:
- |
SHOW SPACES;
log:
level: INFO
console: true
files:
- /ssd/logs/nebula-importer.log
sources:
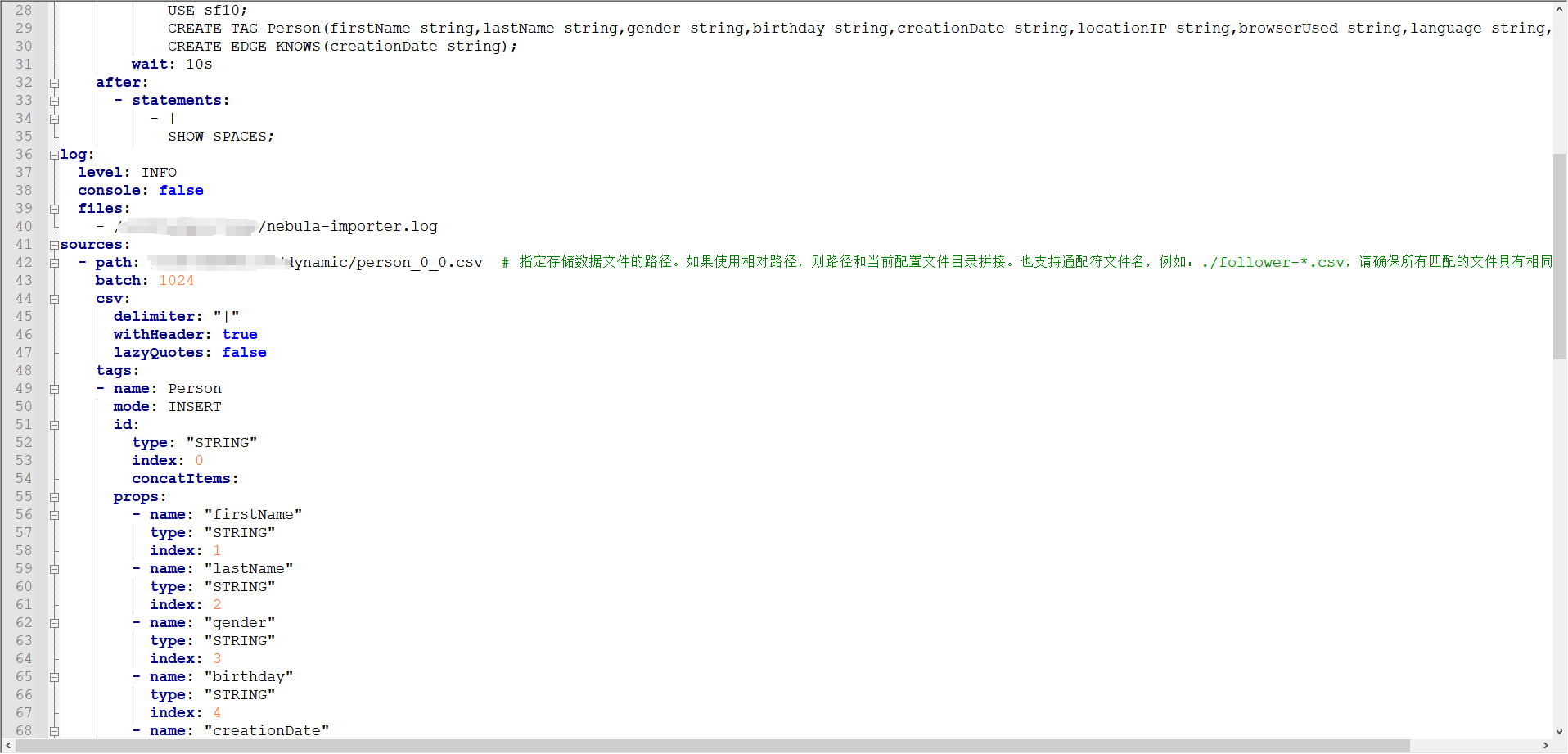
- path: /ssd/10/dynamic/person_0_0.csv
batch: 1024
csv:
delimiter: "|"
withHeader: true
lazyQuotes: false
tags:
- name: Person
mode: INSERT
id:
type: "STRING"
index: 0
props:
- name: "firstName"
type: "STRING"
index: 1
- name: "lastName"
type: "STRING"
index: 2
- name: "gender"
type: "STRING"
index: 3
- name: "birthday"
type: "STRING"
index: 4
- name: "creationDate"
type: "STRING"
index: 5
- name: "locationIP"
type: "STRING"
index: 6
- name: "browserUsed"
type: "STRING"
index: 7
- name: "language"
type: "STRING"
index: 8
- name: "email"
type: "STRING"
index: 9
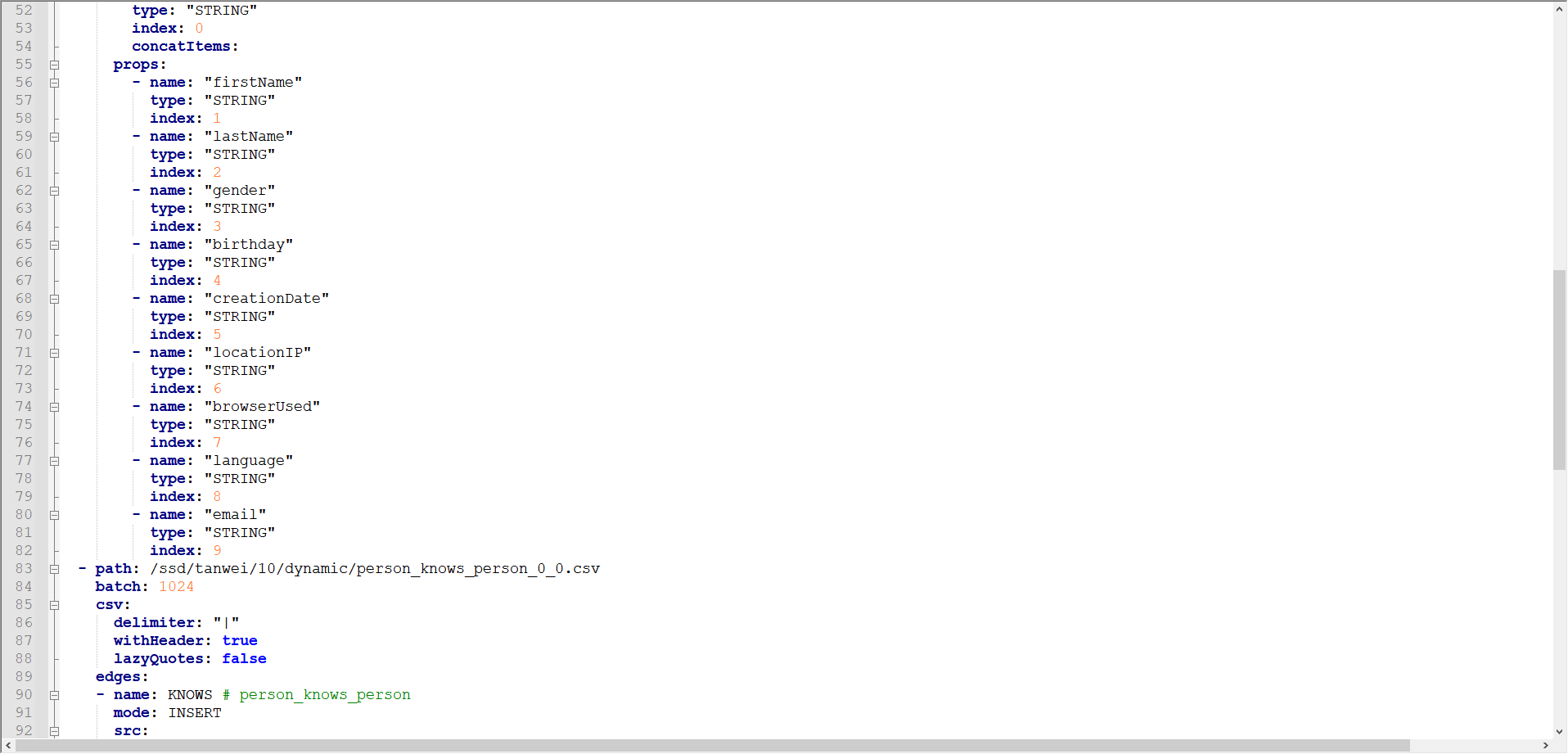
- path: /ssd/10/dynamic/person_knows_person_0_0.csv
batch: 1024
csv:
delimiter: "|"
withHeader: true
lazyQuotes: false
edges:
- name: KNOWS # person_knows_person
mode: INSERT
src:
id:
type: "STRING"
index: 0
dst:
id:
type: "STRING"
index: 1
props:
- name: "creationDate"
type: "STRING"
index: 2
steam
3
分类选到问题分类了,这不是个需求,而是一个问题。然后麻烦按照问题的模版,补充下信息:
- nebula 的版本号
- nebula importer 的版本号
- nebula-importer 的配置文件(不要截图,文本贴过来)
全村的希望
4
nebula 版本: 3.6.0
import:4.1.0
部署方式:单机
安装方式:RPM
是否上生产环境:N
硬件信息
。磁盘 SSD
。CPU、内存信息
steam
7
这种有滚动条的,信息肯定是截不去拿的,光标移动到 yaml / csv 文件中,ctrl + c,ctrl + v 贴过来的就是文本信息。
全村的希望
8
client:
version: v3
address: “xxxx:9669”
user: root
password: nebula
ssl:
enable: false
certPath: “/home/xxx/cert/importer.crt”
keyPath: “/home/xxx/cert/importer.key”
caPath: “/home/xxx/cert/root.crt”
insecureSkipVerify: false
concurrencyPerAddress: 10
reconnectInitialInterval: 1s
retry: 3
retryInitialInterval: 1s
manager:
spaceName: sf10
batch: 1024
readerConcurrency: 50
importerConcurrency: 50
statsInterval: 10s
hooks:
before:
- statements:
- |
DROP SPACE IF EXISTS sf10;
CREATE SPACE IF NOT EXISTS sf10(partition_num=5, replica_factor=1, vid_type=int);
USE sf10;
CREATE TAG Person(firstName string,lastName string,gender string,birthday string,creationDate string,locationIP string,browserUsed string,language string, email string);
CREATE EDGE KNOWS(creationDate string);
wait: 10s
after:
- statements:
- |
SHOW SPACES;
log:
level: INFO
console: true
files:
- /ssd/logs/nebula-importer.log
sources:
- path: /ssd/10/dynamic/person_0_0.csv
batch: 1024
csv:
delimiter: “|”
withHeader: true
lazyQuotes: false
tags:
- name: Person
mode: INSERT
id:
type: “STRING”
index: 0
props:
- name: “firstName”
type: “STRING”
index: 1
- name: “lastName”
type: “STRING”
index: 2
- name: “gender”
type: “STRING”
index: 3
- name: “birthday”
type: “STRING”
index: 4
- name: “creationDate”
type: “STRING”
index: 5
- name: “locationIP”
type: “STRING”
index: 6
- name: “browserUsed”
type: “STRING”
index: 7
- name: “language”
type: “STRING”
index: 8
- name: “email”
type: “STRING”
index: 9
- path: /ssd/10/dynamic/person_knows_person_0_0.csv
batch: 1024
csv:
delimiter: “|”
withHeader: true
lazyQuotes: false
edges:
- name: KNOWS # person_knows_person
mode: INSERT
src:
id:
type: “STRING”
index: 0
dst:
id:
type: “STRING”
index: 1
props:
- name: “creationDate”
type: “STRING”
index: 2
steam
9
这里指明了你的图空间中点的 vid 类型是 int(数值),你传入的数据是 string 类型的 vid。
这里也是,指定了 string。
steam
13
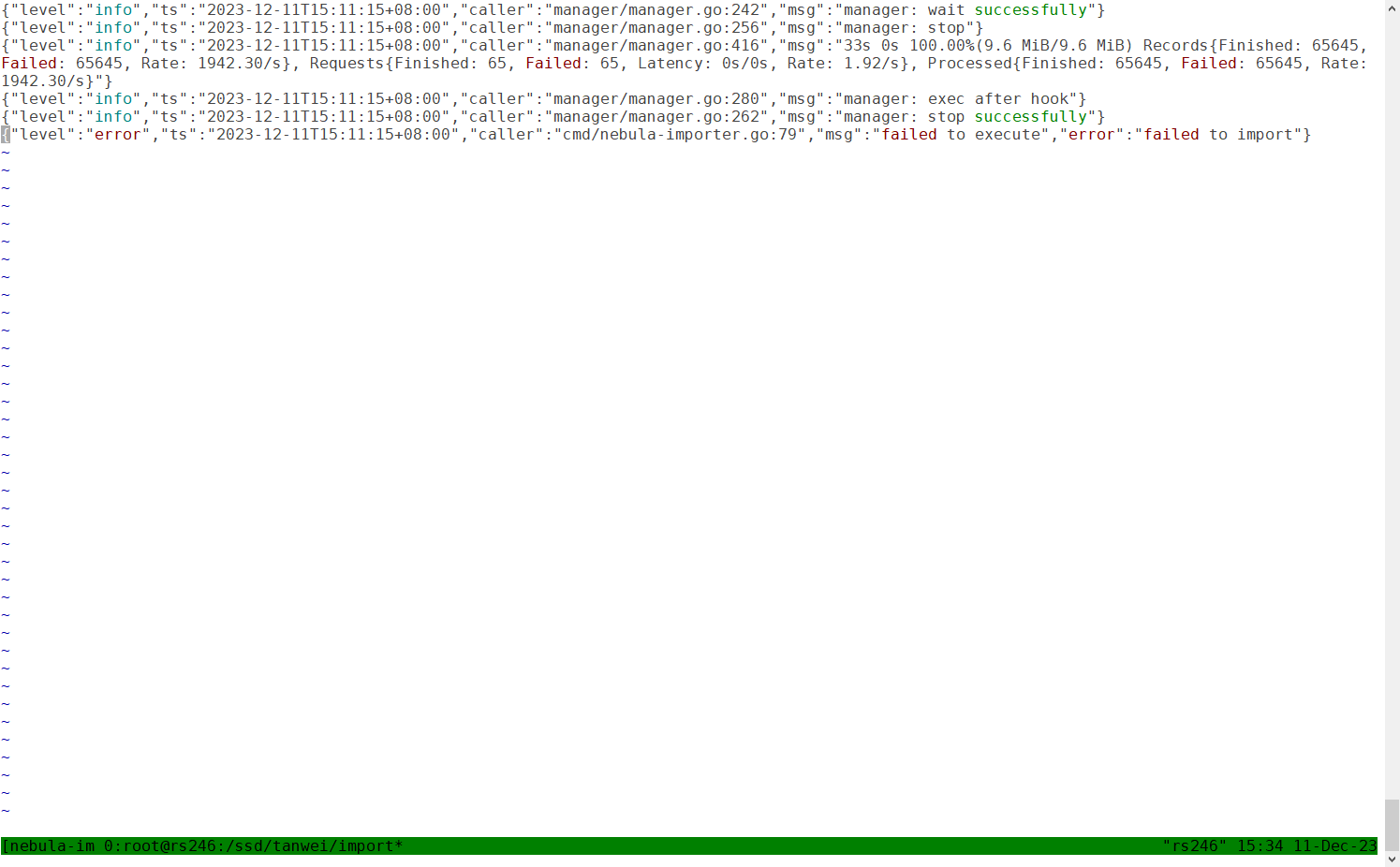
你数据导入之后,可以通过 show stats 命令(它有一个使用前提,你可以看下文档:SHOW STATS - NebulaGraph Database 手册 )查看下数据量,和你的源文件对比下。
这里要注意的是,nebula 的 insert 是覆盖写,就是如果 vid 相同的话,tag 也相同的话,你即便有两条数据,也是以最后成功插入的数据为准。
全村的希望
14
ldbc数据包含list类型数据,import是否支持呐
steam
15
importer 支持不支持还要看内核的,nebulagraph 目前是不支持 list 类型的 schema。
全村的希望
16
- statements:
- |
DROP SPACE IF EXISTS sf10;
CREATE SPACE IF NOT EXISTS sf10(partition_num=5, replica_factor=1, vid_type=FIXED_STRING(16));
USE sf10;
CREATE TAG Person(firstName string,lastName string,gender string,birthday string,creationDate string,locationIP string,browserUsed string,language string, email string);
CREATE TAG Comment(creationDate string,locationIP string,browserUsed string,content string,length string);
CREATE TAG Post(imageFile string,creationDate string,locationIP string,browserUsed string,language string,content string,length string);
CREATE TAG Forum(title string,creationDate string);
CREATE TAG Organisation(type string,name string,url string);
CREATE TAG Place(name string,url string,type string);
CREATE TAG Tag(name string, url string);
CREATE TAG Tagclass(name string, url string);
CREATE EDGE person_knows_person(creationDate string);
CREATE EDGE PersonLikesComment(creationDate string);
CREATE EDGE PersonLikesPost(creationDate string);
CREATE EDGE PostHasCreatorPerson();
CREATE EDGE CommentHasCreatorPerson();
CREATE EDGE CommentHasTagTag();
CREATE EDGE CommentIsLocatedInPlace();
CREATE EDGE CommentReplyOfComment();
CREATE EDGE CommentReplyOfPost();
CREATE EDGE ForumContainerOfPost();
CREATE EDGE ForumHasMemberPerson(joinDate string);
CREATE EDGE ForumHasModeratorPerson();
CREATE EDGE ForumHasTagTag();
CREATE EDGE PersonHasInterestTag();
CREATE EDGE PersonIsLocatedInPlace();
CREATE EDGE PersonStudyAtOrganisation(classYear string);
CREATE EDGE PersonWorkAtOrganisation(workFrom string);
CREATE EDGE PostHasTagTag();
CREATE EDGE PostIsLocatedInPlace();
CREATE EDGE OrganisationIsLocatedInPlace();
CREATE EDGE PlaceIsPartOfPlace();
CREATE EDGE TagHasTypeTagClass();
CREATE EDGE TagClassIsSubclassOfTagClass();
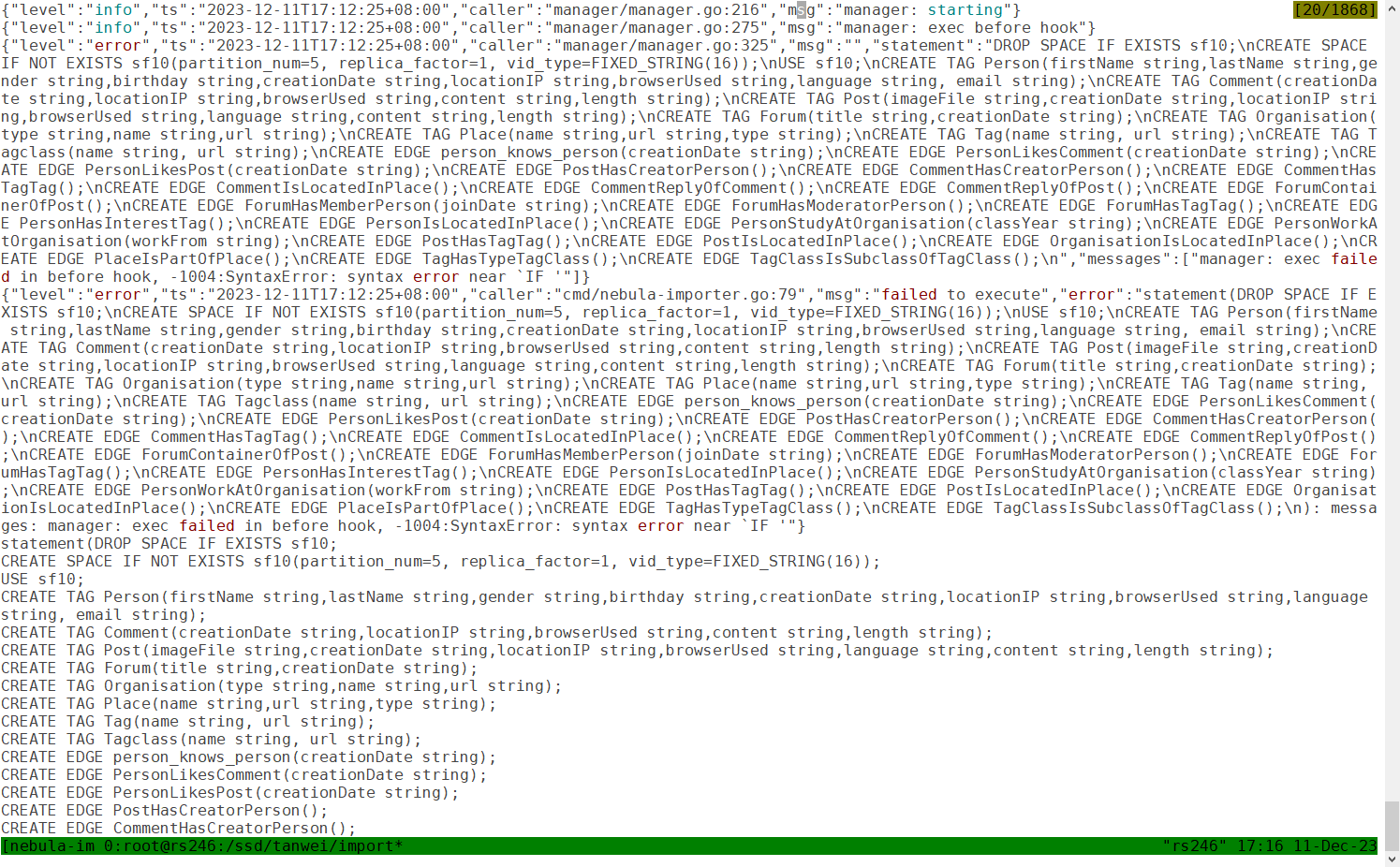
steam
18
看下我们的保留字说明 关键字 - NebulaGraph Database 手册 tag 你要用的话,得用引号。 以及 NebulaGraph 是支持时间类型的,timestamp、date 都支持,我看你还有日期之类的东西,可以用时间类型。
以及 NebulaGraph 是支持时间类型的,timestamp、date 都支持,我看你还有日期之类的东西,可以用时间类型。
steam
20
可能是当中有些数据和 schema 没对应上,所以部分导入失败了。
全村的希望
22
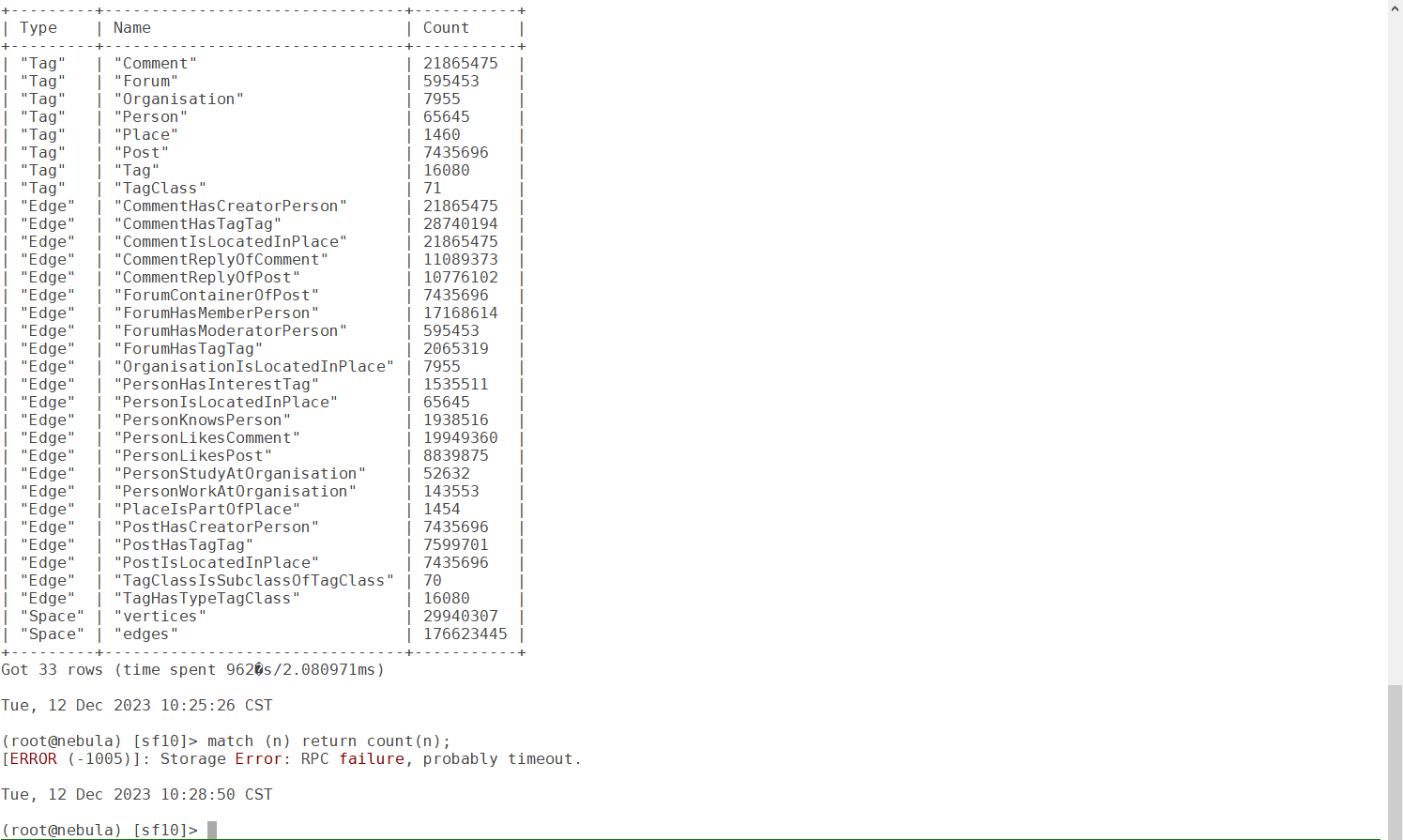
上面截图统计的vertices数量不对是为什么,正确值应该是29987835